
No mundo de hoje, GRAMPO é um dos modelos multimodais básicos mais importantes. Ele combina sinais visuais e textuais em um espaço de recursos compartilhado usando perda de aprendizagem diferencial para pares de imagens de texto grandes. Como detector, o CLIP suporta muitas funções, incluindo classificação zero-shot, detecção, classificação e recuperação de texto de imagem. Além disso, como extrator de recursos, tornou-se poderoso em quase todas as tarefas de representação multimodo, como reconhecimento de imagem, reconhecimento de vídeo e geração de texto para imagem/vídeo. Seu poder vem principalmente de sua capacidade de conectar imagens com linguagem natural e capturar o conhecimento humano, pois é treinado em grandes dados da web com descrições de texto detalhadas, ao contrário dos codificadores visuais. Desde que eu principais modelos de linguagem (LLMs) está crescendo rapidamente, os limites da compreensão da linguagem e da geração estão sendo constantemente ultrapassados. As fortes habilidades textuais dos LLMs podem ajudar o CLIP a lidar melhor com legendas longas e complexas, um ponto fraco do CLIP original. Os LLMs também possuem amplo conhecimento de grandes conjuntos de dados textuais, tornando o treinamento mais eficaz. Os LLMs têm fortes habilidades de compreensão, mas seu método de produção de texto esconde as habilidades para tornar o resultado pouco claro.
Os desenvolvimentos atuais ampliaram o CLIP para lidar com outros métodos e sua influência na área está crescendo. Os novos modelos são semelhantes Lhama3 foram usados para estender o comprimento das anotações CLIP e melhorar sua funcionalidade usando o conhecimento de mundo aberto dos LLMs. Porém, integrar LLMs com CLIP dá trabalho devido às limitações de seu editor de texto. Em muitos experimentos, descobriu-se que combina diretamente LLMs No meio GRAMPO levando à redução do desempenho. Assim, existem certos desafios que devem ser superados para avaliar os benefícios potenciais da inclusão de LLMs no CLIP.
Universidade Tongji de novo Corporação Microsoft os pesquisadores conduziram um estudo detalhado e propuseram LLM2CLIP como melhorar a aprendizagem de representações visuais integrando modelos de linguagem em larga escala (LLMs). Esta abordagem dá um passo direto ao incluir o editor de texto CLIP original e melhora a interface do CLIP com o amplo conhecimento de LLMs. Identifica os principais obstáculos associados a esta nova ideia e sugere uma estratégia corretiva eficaz em termos de custos para os ultrapassar. Este método substitui a codificação CLIP original. Reconhece os desafios desta abordagem e sugere uma forma económica de aperfeiçoar o modelo para os resolver.
EU LLM2CLIP O método melhorou com sucesso o modelo CLIP integrando modelos linguísticos de grande escala (LLMs), como Lhama. Inicialmente, os LLMs tiveram dificuldades como codificadores de texto CLIP devido à sua incapacidade de distinguir claramente as legendas das imagens. Os pesquisadores apresentaram um vislumbre de um método de ajuste fino para lidar com isso, melhorando muito a capacidade do LLM de distinguir legendas. Esses refinamentos levaram a melhorias significativas de desempenho, superando os modelos existentes. A estrutura LLM2CLIP combinou o LLM aprimorado com uma interface CLIP pré-treinada, criando um poderoso modelo cross-modal. O método utilizou grandes LLMs, mas permaneceu eficiente ao contabilizar custos adicionais.
O teste se concentra no ajuste fino de modelos para melhor correspondência de imagens usando conjuntos de dados semelhantes CC-3M. Com o ajuste fino do LLM2CLIP, três tamanhos de conjuntos de dados testados: pequeno (CC-3M), que está entre (CC-3M e CC-12M), e grande (CC-3M, CC-12M, YFCC-15M e Recaptação-1B). O treinamento com legendas aumentadas melhorou o desempenho, enquanto o uso de um modelo de linguagem CLIP não treinado o piorou. Os modelos treinados com LLM2CLIP superam CLIP e EVA em tarefas como recuperação de imagem para texto e texto para imagem, destacando as vantagens de combinar modelos de linguagem grande com modelos de imagem-texto.
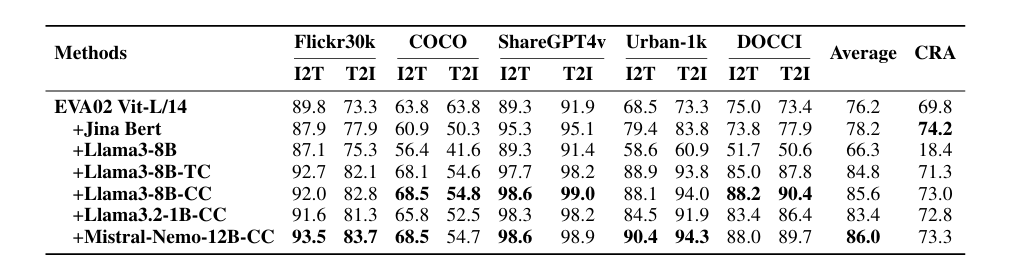
O método aumentou diretamente o desempenho do anterior SOTA EVA02 modelo com 16,5% para tarefas de recuperação de texto longo e curto, convertendo um modelo CLIP treinado apenas em dados em inglês em um modelo multilíngue moderno. Depois de combinar o treinamento multimodal com modelos semelhantes Lava 1.5superou o CLIP em quase todos os benchmarks, mostrando uma melhoria geral significativa no desempenho.

Concluindo, o método proposto permite que os LLMs auxiliem no treinamento CLIP. Ao ajustar parâmetros como distribuição de dados, duração ou fases, o LLM pode ser modificado para ajustar os limites do CLIP. Permite que o LLM atue como um professor abrangente de diversas profissões. No trabalho proposto, os gradientes LLM são congelados durante o ajuste fino para manter um grande tamanho do conjunto de treinamento CLIP. Em trabalhos futuros, o LLM2CLIP pode ser treinado do zero em conjuntos de dados semelhantes Laion-2Banda de novo Recaptação-1B para melhores resultados e desempenho. Este trabalho pode ser usado como base para futuras pesquisas em treinamento CLIP e seus diversos programas!
Confira Papel, O códigode novo O modelo do tamanho do rosto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🐝🐝 O próximo evento ao vivo do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar as equipes a construir modelos de IA revolucionários , rápido.


