
Grandes Modelos de Linguagem (LLMs) demonstraram habilidades notáveis de aprendizagem no conteúdo (ICL), onde podem aprender tarefas a partir de demonstrações sem precisar de treinamento adicional. Um desafio importante neste campo é compreender e prever a relação entre o número de determinados displays e a melhoria do desempenho do modelo, conhecida como curva ICL. Estas relações precisam de ser melhor compreendidas, apesar das suas implicações importantes para vários sistemas. A previsão precisa das curvas ICL tem uma importância importante na determinação dos valores absolutos da reflexão, antecipando a possível falha do alinhamento em muitas situações extremas, e avaliando os ajustes necessários para controlar o comportamento indesejado. A capacidade de modelar essas curvas de aprendizagem de forma eficaz pode melhorar a tomada de decisões em estratégias de implantação e ajudar a reduzir riscos potenciais associados à implementação do LLM.
Várias abordagens de pesquisa tentaram elucidar os mecanismos subjacentes de aprendizagem no contexto dos modelos de Big Language, apresentando diferentes teorias. Alguns estudos sugerem que LMs treinados em dados artificiais se comportam como alunos bayesianos, enquanto outros sugerem que seguem padrões de gradiente descendente, e outros mostram que o algoritmo de aprendizagem varia com base na complexidade da tarefa, na escala do modelo e no progresso do treinamento. As leis de potência surgiram como a principal estrutura para modelar o comportamento do LM, incluindo curvas ICL em diferentes configurações. No entanto, a pesquisa existente tem limitações significativas. Nenhum trabalho anterior estimou diretamente a curva ICL com base nas suposições subjacentes do algoritmo de aprendizagem. Além disso, as mudanças pós-treino demonstraram ser menos eficazes, com pesquisas mostrando que tais mudanças são frequentemente superficiais e facilmente evitadas, especialmente porque a ICL não consegue restaurar comportamentos que se pensava serem suprimidos com o condicionamento adequado.
Os pesquisadores propõem o que introduz regras bayesianas para modelar e prever as curvas de aprendizagem dentro do conteúdo para todas as condições do modelo de linguagem. O estudo testa essas regras usando testes de dados sintéticos com modelos GPT-2 e testes do mundo real em benchmarks padrão. O método vai além do simples ajuste de curvas, fornecendo parâmetros interpretáveis que capturam distribuições de atividades anteriores, eficiência de ICL e probabilidades de amostragem em diferentes atividades. O método de pesquisa inclui duas etapas principais de avaliação: em primeiro lugar, comparar o desempenho das regras Bayesianas com os modelos de lei de potência existentes na previsão de curvas e, em segundo lugar, analisar como as mudanças pós-treinamento afetam o comportamento do ICL em tarefas apreciadas e não apreciadas. O estudo conclui com uma avaliação abrangente de todos os principais modelos, dos parâmetros 1B a 405B, incluindo testes de habilidades, medidas de segurança e um conjunto robusto de dados sobre fugas de prisões.
A arquitetura das regras de escala bayesiana para ICL é construída em suposições básicas sobre como os modelos de linguagem processam e aprendem com exemplos dentro do contexto. A estrutura começa tratando a ICL como um processo de aprendizagem bayesiano, usando o teorema de Bayes iterativamente para modelar como cada instância dentro de um contexto atualiza a tarefa anterior. Uma inovação importante na arquitetura é a introdução de técnicas de redução de parâmetros para evitar overfitting. Isso inclui dois métodos diferentes de ajuste de parâmetros, por amostragem e por pontuação, que ajudam a manter a eficiência do modelo enquanto dimensionam ao longo do valor da distribuição. As propriedades incluem um coeficiente de eficiência ICL 'K' que leva em conta a natureza de processamento token a token dos LLMs e a variação da instância de informação, ajustando efetivamente o poder das atualizações bayesianas com base no comprimento e complexidade da instância.
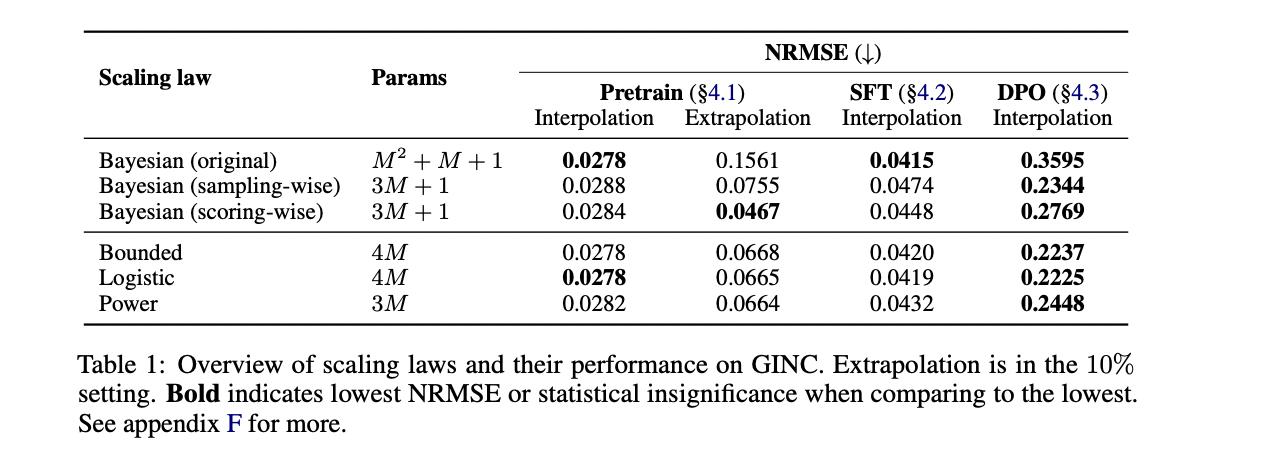
Os resultados experimentais mostram o desempenho superior das regras de escalamento Bayesiano em comparação com os métodos existentes. Em testes translacionais, a primeira lei de escala bayesiana alcançou o menor erro quadrático médio normalizado (NRMSE) em todas as escalas do modelo e comprimentos de trajetória, comparável apenas à linha de base robusta do sistema. A regra bayesiana mais inteligente foi a mais bem-sucedida nas funções aditivas, apresentando o melhor desempenho na previsão dos 90% restantes das curvas ICL usando apenas os primeiros 10% dos pontos de dados. Apesar da superioridade numérica, as regras bayesianas fornecem parâmetros interpretáveis que fornecem insights significativos sobre o comportamento do modelo. Os resultados revelam que a distribuição anterior corresponde à mesma distribuição de treinamento anterior, e a eficiência do ICL correlaciona-se bem com a profundidade do modelo e com o comprimento do exemplo, indicando que modelos maiores se beneficiam mais rapidamente do aprendizado de conteúdo, especialmente com exemplos instrutivos.
A comparação das versões Llama 3.1 8B Base e Instruct revelou informações importantes sobre a eficácia do ajuste de instruções. Os resultados mostram que, embora a reforma prescritiva reduza eficazmente a probabilidade anterior de comportamento inseguro em várias métricas de avaliação (incluindo testes de bancada e avaliação pessoal), ela não consegue prevenir eficazmente invasões nas prisões. A lei de escala bayesiana indica que as probabilidades posteriores são eventualmente saturadas, independentemente das probabilidades anteriores reduzidas obtidas pelo ajuste das instruções. Isto sugere que o planeamento instrucional altera principalmente os antecedentes da tarefa, em vez de alterar fundamentalmente o conhecimento subjacente da tarefa do modelo, possivelmente devido aos recursos computacionais limitados atribuídos ao planeamento instrucional em comparação com o pré-treinamento.
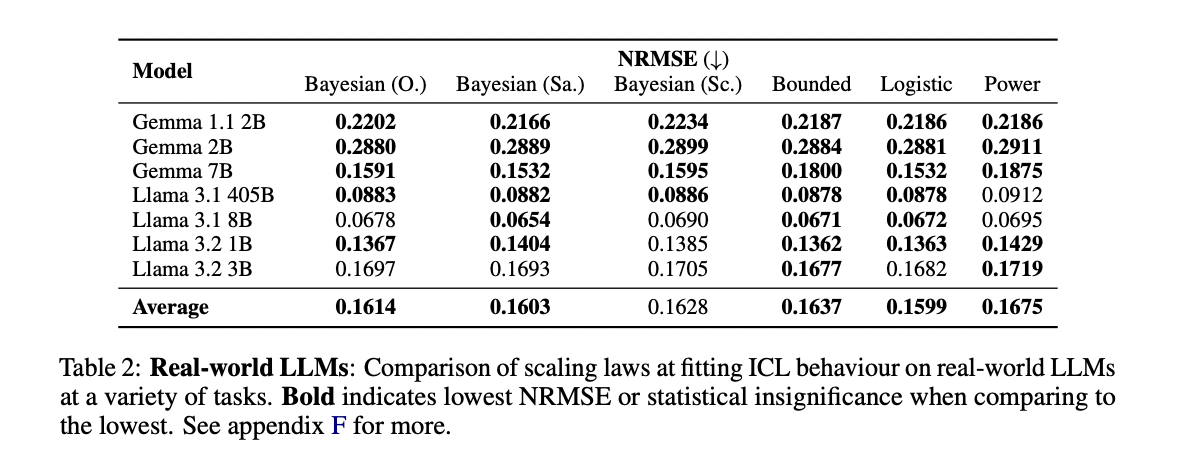
O estudo aborda com sucesso duas questões fundamentais sobre a aprendizagem de conteúdo, construindo e validando regras de escala bayesiana. Essas regras mostram uma eficiência notável na modelagem do comportamento da ICL tanto em pequenos LMs treinados em dados sintéticos quanto em grandes modelos treinados em linguagem natural. A principal contribuição está na descrição da estrutura Bayesiana, que fornece insights claros sobre prioridades, eficiência de aprendizagem e probabilidades condicionais de trabalho. Esta estrutura provou ser valiosa para a compreensão das habilidades de ICL dependentes da escala, analisando o efeito do ajuste fino na retenção de conhecimento e comparando modelos básicos com seus equivalentes baseados em disciplinas. O sucesso desta abordagem sugere que uma investigação mais aprofundada das leis de escala pode revelar informações importantes sobre a natureza e o comportamento da aprendizagem dentro do conteúdo, abrindo caminho para modelos de linguagem mais eficazes e manejáveis.
Confira Papel de novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


