 verifica o desenvolvimento e os desafios nos modelos de IA de pensamento multimorde")
Após o sucesso de grandes idiomas (LLMs), o presente estudo excede o texto com base em atividades de consulta multimodal. Essas atividades incluem uma visão e linguagem, que é importante para a articulação artificial normal (AGI). Sintomas dos Qunchmarks como PuzzleVQA e AlgoupuzzlevzqQA explorando a IA calculativa para o impacto e a consulta algorítmica. Mesmo após o desenvolvimento, os LLMs são travados contra o pensamento multimorde, especialmente o reconhecimento do padrão e a solução de problemas locais. O maior custo de concorrência inclui esses desafios.
Estudo anterior depende de benchmarks simbólicos como o ARC-AGI e a avaliação visual, como a matrícula contínua de Raven. No entanto, isso não paga a capacidade de AI a capacidade de processar entrada multimoral. Recentemente, os conjuntos de dados são como um PuzzleVQA e Algozleve apresentados para verificar o pensamento incompreensível e a solução de problemas algorítmicos. Esta venda requer modelos, incluindo reduções visuais, lógicas e consulta formal. Enquanto modelos anteriores, como GPT-4-Turbo e GPT-4O, mostrando melhora, eles ainda estão sob a exibição misteriosa e a demonstração multimodal.
Investigadores da Universidade de Tecnologia e Design de Cingapura (SUTD) apresentaram a avaliação formal do GPTA de Opelaa-[n] ao lado[n] Uma série de modelo na resolução de um quebra -cabeça multimodal. O estudo deles avaliou como as habilidades pensativas vieram de diferentes modelos do modelo. Um estudo que pretende identificar espaços em habilidades de ver, pensamento misterioso e resolução de problemas. A equipe comparou o desempenho dos modelos como GPT-4-Turbo, GPT-4O e O1 nos conjuntos de dados PuzzleVQA e Algouxzleve, incluindo desafios algorítmicos visíveis.
Os investigadores executam uma avaliação formal usando dois conjuntos de dados principais:
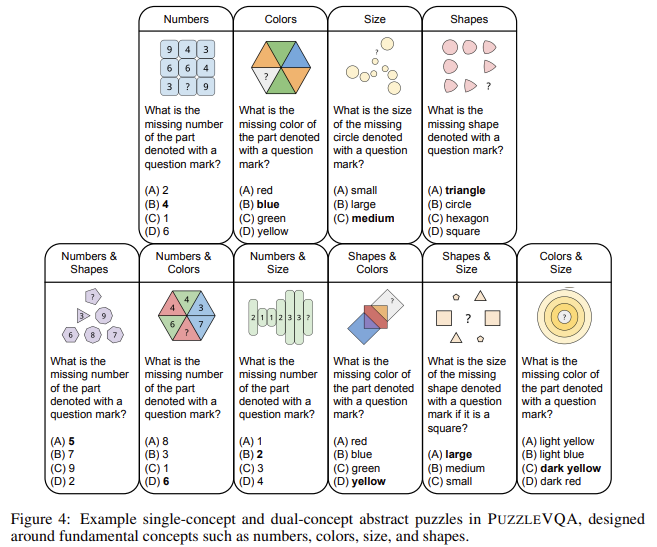
- Puzzleva: Puzzlevqa se concentra na visão imoral e requer modelos para ver padrões com números, formas, cores e tamanhos.
- I-AlgoPuzzzzqa: I-AlgoPuzzzzqa Ye-AlgoPuzzzkka Iveza imisebenzi yokuxazulula inkinga ye-algorítmico edinga ukuncishiswa okunengqondo nokucabanga kwe-computacional.
O teste é realizado usando formatos selecionados e desagradáveis. O estudo utilizou a cadeia de pensamento zero (COT) emitindo em consulta e analisando a diminuição do desempenho ao alterar muitas opções. Os modelos são testados e, sob condições, ao visualizar uma consulta visual e específica, foi fornecida separadamente para obter certas fraquezas.
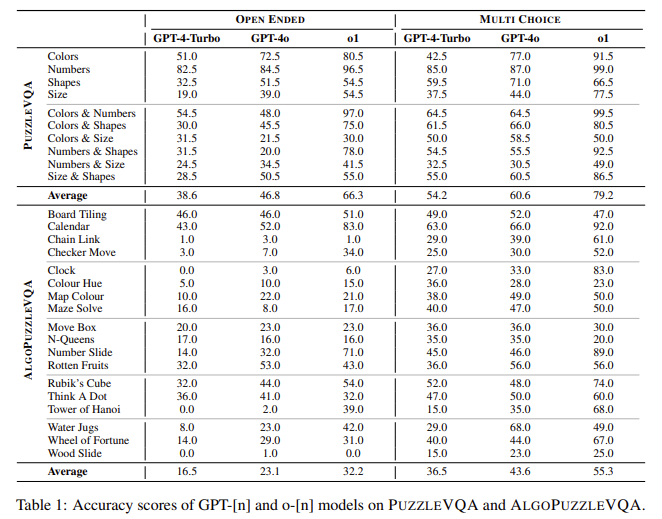
A lição viu um forte progresso no poder da consulta em diferentes gerações de modelos. O GPT-4O tem um desempenho melhor que o GPT-4-Turbo, enquanto o O1 recebe um significado significativo, especialmente em consulta algorítmica. No entanto, esses benefícios chegaram ao forte aumento no custo da integração. Sem o desenvolvimento completo, os modelos de IA ainda estão atendendo a trabalhos que exigem interpretação direta, como ver a ausência ou especificar padrões incomuns. Enquanto o O1 foi bem feito por razões numéricas, era difícil levantar o quebra -cabeça com base na tela. A diferença entre muitas atividades de seleção e abertura revelou uma sólida resposta às respostas. Além disso, o perction continua sendo um grande desafio para todos os modelos, com a precisão que promove informações claras.
Com uma repetição rápida, o trabalho pode resumir alguns pontos detalhados:
- A lição reconheceu o maior hábito nas habilidades de consulta do GPT-4-Turbo no GPT-4O e O1. Embora o GPT-4O mostre benefícios moderados, a transformação O1 levou a um desenvolvimento significativo, mas chegou ao custo 750X dos custos computacionais em comparação com o GPT-4O.
- Do outro lado do PuzzleVQA, o O1 recebeu entre 79,2% preciso em muitas configurações de seleção, excedendo 60,6% e 54,2% do GPT-4-Turbo. No entanto, nas atividades de abertura, todos os modelos mostraram operações, 66,3%de pontos, GPT-4O em 46,8%e GPT-Turbo em 38,6%.
- Em Algouzzzqzqqqqa, O1 muito melhor do que os modelos anteriores, especialmente os quebra -cabeças precisam de redução numérica e vegetal. A O1 recebeu 55,3% de pontos, em comparação com 43,6% e 43,6% e 36,5% do GPT-Turbo em atividades de seleção selecionadas. No entanto, sua precisão é reduzida em 23,1% nas atividades de abertura.
- A pesquisa identificou a visão como o limite principal para todos os modelos. Para inserir informações, informações claras desenvolveram a precisão de 22% -30%, o que indica depender de objetivos de entendimento externo. O incrível Guia da Consulta também fortaleceu o trabalho de 6% a 19%, especialmente o reconhecimento de números e padrão de localização.
- O O1 é exposto em linhas matemáticas, mas está lutando com flutuações com base em uma mutelulação, mostrando 4,5% em comparação com o GPT-4O em serviços de reconhecimento. Além disso, faça bem em resolver problemas formais, mas enfrentou desafios em condições abertas que requerem redução independente.
Enquete Página e papel do github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Registre a plataforma de IA de código aberto: 'Sistema de código aberto interestagente com muitas fontes para testar o programa difícil' (Atualizado)
Sana Hassan, um contato em Marktechpost com um aluno do estudante de dual-grau no IIIT Madras, adora usar a tecnologia e a IA para lidar com os verdadeiros desafios do mundo. Estou muito interessado em resolver problemas práticos, traz uma nova visão da solução de IA para a IA e soluções reais.
✅ [Recommended] Junte -se ao nosso canal de telégrafo
: uma nova abordagem de IA para montagem de modelos")

