
O aprendizado de máquina adversário é um campo em crescimento que se concentra em testar e melhorar a robustez dos sistemas de aprendizado de máquina (ML) com exemplos adversários. Esses modelos são criados alterando sutilmente os dados para induzir os modelos a fazerem previsões incorretas. Os modelos generativos profundos (DGMs) têm se mostrado promissores na geração de tais modelos adversários, especialmente em visão computacional, onde a avaliação de dados físicos é um modelo robusto. Estender este processo a outros tipos de dados, especialmente dados tabulares, apresenta desafios adicionais devido à necessidade de modelos para manter relações verdadeiras entre características. Por exemplo, em domínios como finanças ou saúde, os contraexemplos gerados devem estar em conformidade com os limites do domínio, que não são específicos quando comparados com imagens ou texto.
Um dos desafios mais proeminentes na aplicação de técnicas de processamento de dados tabulares decorre da complexidade da sua estrutura. Os dados tabulares costumam ser mais complexos do que outros tipos de dados porque envolvem muitos relacionamentos entre variáveis. Essas variáveis podem representar diferentes tipos de dados, como categóricos, numéricos ou binários, e requerem determinados parâmetros. Por exemplo, num conjunto de dados financeiros, o modelo pode necessitar de garantir que o “valor médio da transação” não excede o “valor máximo da transação”. O não cumprimento dessas restrições resulta em exemplos contraintuitivos que não podem ser usados para avaliar adequadamente a segurança dos modelos de ML. Os modelos existentes para gerar padrões conflitantes em dados tabulares geralmente sofrem com esse problema, produzindo até 100% de dados falsos.
Vários métodos têm sido usados para criar exemplos conflitantes de dados tabulares. Os primeiros modelos, como TableGAN, CTGAN e TVAE, foram originalmente projetados para criar conjuntos de dados tabulares sintéticos para otimização e geração de dados com preservação de privacidade. No entanto, estes modelos têm limitações quando utilizados para geração de adversários porque devem considerar restrições especiais específicas de domínio que são importantes para garantir o realismo em exemplos adversários. Modelos recentes tentaram resolver isso adicionando ruído aos dados ou manipulando recursos individuais. No entanto, esta abordagem limita o espaço de busca por contra-exemplos, tornando-os ineficazes em aplicações do mundo real.
Pesquisadores da Universidade de Luxemburgo, da Universidade de Oxford e do Imperial College London introduziram um novo método convertendo DGMs existentes em DGMs adversários (AdvDGMs) e melhorando-os adicionando uma camada de correção de barreira. O objetivo deles era modificar modelos como WGAN, TableGAN, CTGAN e TVAE em versões que pudessem gerar exemplos adversários e, ao mesmo tempo, garantir que eles atendessem aos parâmetros de domínio exigidos. Esses modelos avançados, chamados DGMs adversários (C-AdvDGMs), permitem aos pesquisadores gerar dados adversários que não apenas alteram as previsões do modelo de ML, mas também obedecem a regras lógicas e relacionamentos entre conjuntos de dados.
O principal desenvolvimento deste trabalho reside na camada de resolução de problemas. Esta camada verifica cada instância gerada em relação às restrições específicas do conjunto de dados predefinidas. Por exemplo, suponha que um contra-exemplo viole a regra, como uma única variável excedendo seu limite lógico. Nesse caso, a camada de ajuste de restrição ajusta a instância para garantir que ela atenda a todos os requisitos específicos do domínio. Essa técnica pode ser combinada durante o treinamento do modelo ou utilizada após a geração, tornando o método versátil. Adicionar esta camada limite não reduz significativamente o desempenho do modelo. Ele introduz apenas um pequeno aumento no tempo de cálculo, como um atraso de 0,12 segundos em alguns casos.
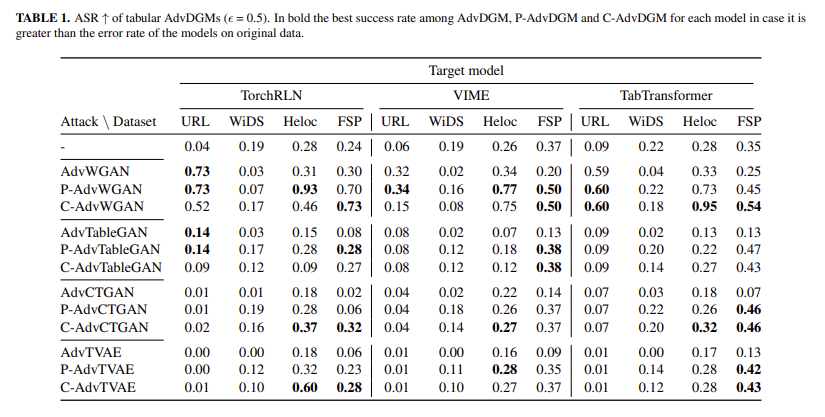
Ao testar a eficácia dos modelos propostos, os pesquisadores os testaram em vários conjuntos de dados do mundo real, incluindo URL, WiDS, Heloc e FSP. Eles compararam o desempenho de AdvDGMs irrestritos com seus equivalentes restritos, C-AdvDGMs, em três modelos populares de ML: TorchRLN, VIME e TabTransformer. A taxa de sucesso do ataque, medida como Taxa de Sucesso de Ataque (ASR), foi a métrica principal. Por exemplo, o modelo AdvWGAN, combinado com uma camada de bloqueio, alcançou um ASR impressionante de 95% no conjunto de dados Heloc quando testado no modelo TabTransformer. Este resultado é uma melhoria significativa em relação às tentativas anteriores de tabular dados adversários. Em 38 dos 48 casos de teste, os P-AdvDGMs (modelos restritos usados durante a amostragem) apresentaram ASR mais alto do que suas versões irrestritas, com o modelo de melhor desempenho aumentando o ASR em 62%.
Os pesquisadores também testaram seus modelos contra outros métodos de ataque de última geração (SOTA), incluindo ataques baseados em gradiente, como CPGD e CAPGD, e um ataque de algoritmo genético chamado MOEVA. AdvDGMs bloqueados mostraram alto desempenho em muitos casos, especialmente na geração de exemplos conflitantes do mundo real, tornando-os muito eficazes na manipulação de modelos de ML alvo. Por exemplo, em nove entre doze conjuntos de dados, o ataque de algoritmo genético MOEVA supera o ataque baseado em gradiente. No entanto, AdvWGAN e suas variantes ainda são classificados como o segundo melhor método para conjuntos de dados como Heloc e FSP.

Concluindo, este estudo aborda uma lacuna importante no aprendizado de máquina em relação a dados tabulares. Ao introduzir uma camada de correção de host, os pesquisadores modificaram com sucesso os DGMs para gerar modelos adversários que manipulam modelos de ML e mantêm as relações necessárias do mundo real entre os recursos. O sucesso do modelo AdvWGAN, que alcançou 95% de ASR no conjunto de dados Heloc, mostra o potencial desta abordagem para melhorar a robustez dos modelos de ML em domínios que exigem dados conflitantes altamente estruturados e realistas. Este trabalho abre caminho para testes de segurança mais confiáveis em sistemas de ML e demonstra a importância de restringir restrições na geração de modelos adversários.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


