
Os sistemas de agentes desenvolveram-se rapidamente nos últimos anos, mostrando a capacidade de resolver tarefas complexas que imitam processos de tomada de decisão semelhantes aos humanos. Esses sistemas são projetados para realizar análises passo a passo de tarefas intermediárias e semelhantes às humanas. No entanto, um dos maiores desafios neste domínio é avaliar eficazmente estes programas. Os métodos tradicionais de avaliação concentram-se apenas nos resultados, deixando de fora o feedback crítico que pode ajudar a melhorar as etapas intermediárias para resolver problemas. Como resultado, as capacidades de otimização em tempo real dos sistemas de agentes podem ser melhoradas, retardando o seu progresso em aplicações do mundo real, como geração de código e desenvolvimento de software.
A falta de métodos de teste eficazes representa um grande problema na investigação e desenvolvimento da IA. As estruturas de avaliação atuais, como o LLM-as-a-Judge, que utiliza grandes modelos de linguagem para julgar os resultados de outros sistemas de IA, devem cuidar de todo o processo de resolução de tarefas. Esses modelos tendem a ignorar estágios intermediários, que são importantes em sistemas de agentes porque simulam estratégias de resolução de problemas semelhantes às humanas. Além disso, embora mais precisos, os testes humanos consomem muitos recursos e são impraticáveis para operações em grande escala. A falta de um método de teste abrangente e padronizado limitou o desenvolvimento de sistemas de agentes, deixando os desenvolvedores de IA necessitados das ferramentas certas para testar seus modelos durante todo o processo de desenvolvimento.
Os métodos existentes para avaliar sistemas de agentes dependem fortemente do julgamento humano ou de benchmarks que avaliam apenas os resultados finais de uma tarefa. Benchmarks como o SWE-Bench, por exemplo, concentram-se na medição do sucesso de soluções ponta a ponta em tarefas automatizadas de longo prazo, mas fornecem poucos insights sobre o desempenho de etapas intermediárias. Da mesma forma, HumanEval e MBPP avaliam a geração de código apenas em tarefas algorítmicas básicas, que não refletem a complexidade do desenvolvimento de IA no mundo real. Além disso, modelos linguísticos de grande escala (LLMs) já demonstraram a capacidade de resolver 27% das tarefas no SWE-Bench. No entanto, o seu desempenho em tarefas práticas e abrangentes de desenvolvimento de IA ainda precisa de ser melhorado. O escopo limitado desses benchmarks existentes destaca a necessidade de ferramentas de teste dinâmicas e informativas que capturem toda a gama de capacidades do sistema de agente.
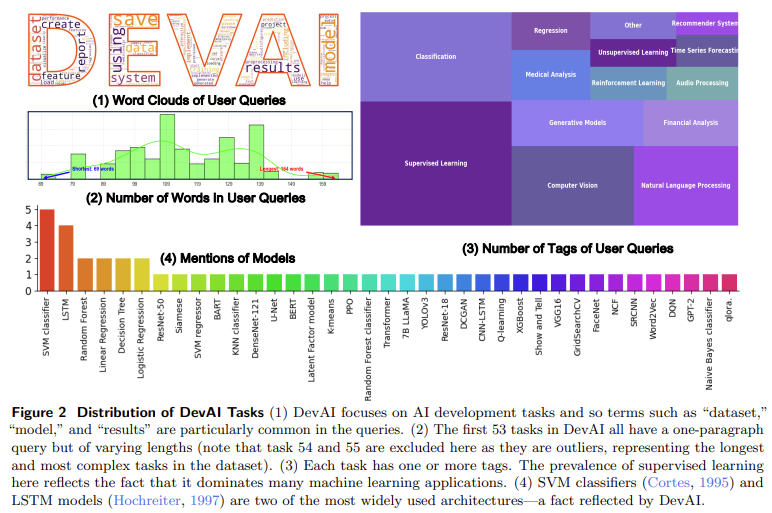
Pesquisadores da Meta AI e da Universidade de Ciência e Tecnologia King Abdullah (KAUST) introduziram uma nova estrutura de teste chamada. Agente como Juiz. Esta abordagem inovadora utiliza sistemas de agentes para avaliar outros sistemas de agentes, fornecendo feedback detalhado ao longo do processo de resolução de tarefas. Os pesquisadores desenvolveram um novo benchmark chamado DevaIincluindo 55 trabalhos práticos de desenvolvimento de IA, como geração de código e engenharia de software. O DevaI inclui 365 requisitos hierárquicos de usuário e 125 preferências, fornecendo um ambiente de teste abrangente para testar sistemas de agentes em tarefas dinâmicas. A introdução do Agente como Juiz permite feedback contínuo, ajuda a melhorar o processo de tomada de decisão e reduz significativamente a dependência do julgamento humano.
A estrutura do Agente como Juiz avalia os sistemas de agentes em cada estágio da atividade, em vez de apenas avaliar o resultado. Este método é uma extensão do LLM-as-a-Judge, mas corresponde às características únicas dos sistemas de agentes, que lhes permitem julgar o seu desempenho na resolução de problemas complexos. A equipe de pesquisa testou a estrutura em três sistemas líderes de agentes de código aberto: MetaGPT, GPT-Pilot e OpenHands. Esses sistemas são marcados contra 55 funções no DevaI. O MetaGPT foi o mais barato, com um preço médio de US$ 1,19 por transação, enquanto o OpenHands foi o mais caro, com US$ 6,38. Em termos de tempo de desenvolvimento, o OpenHands foi o mais rápido, terminando com uma média de 362,41 segundos, enquanto o GPT-Pilot demorou mais tempo, com 1622,38 segundos.
Os resultados da estrutura Agente como Juiz alcançaram 90% de concordância com avaliadores humanos, em comparação com o alinhamento LLM como Juiz de 70%. Além disso, a nova estrutura reduziu o tempo de teste em 97,72% e o custo em 97,64% em comparação com testes em humanos. Por exemplo, o preço médio de um teste em humanos sob o benchmark DevaI é de aproximadamente US$ 1.297,50, demorando mais de 86,5 horas. Em contraste, o Agente como Juiz reduziu esse custo para apenas US$ 30,58, exigindo apenas 118,43 minutos para ser concluído. Estes resultados mostram o potencial do framework para orientar e melhorar o processo de avaliação de sistemas de agentes, tornando-o uma alternativa eficaz à dispendiosa avaliação humana.
O estudo forneceu várias conclusões importantes, resumindo as implicações da pesquisa para o desenvolvimento futuro da IA. Agent-as-a-Judge apresenta uma maneira escalável, eficiente e altamente precisa de avaliar sistemas de agentes, abrindo a porta para um maior desenvolvimento desses sistemas sem depender de intervenção humana dispendiosa. O benchmark DevaI apresenta um conjunto de tarefas desafiadoras, mas realistas, que demonstram os requisitos do desenvolvimento de IA e permitem uma avaliação completa das capacidades do sistema do agente.
Principais conclusões do estudo:
- A estrutura Agente como Juiz alcançou 90% de concordância com examinadores humanos, superando o LLM como Juiz.
- O DevaI inclui 55 tarefas de desenvolvimento de IA do mundo real com 365 requisitos de classe e 125 preferências.
- O agente como juiz reduz o tempo de inspeção em 97,72% e os custos em 97,64% em comparação com os inspetores humanos.
- OpenHands é o mais rápido na conclusão do trabalho, com média de 362,41 segundos, enquanto o MetaGPT é o mais econômico, com US$ 1,19 por trabalho.
- A nova estrutura é uma forma diferente de avaliação humana. Ele fornece feedback contínuo durante os processos de resolução de tarefas, o que é essencial para o desenvolvimento do sistema de agentes.

Em conclusão, este estudo marca um grande avanço nos testes de sistemas de IA de agentes. A estrutura Agente como Juiz fornece um método de avaliação altamente eficiente e escalonável e fornece insights profundos sobre as etapas intermediárias do desenvolvimento de IA. O benchmark DevaI melhora esse processo ao introduzir tarefas realistas e abrangentes, ampliando os limites do que os sistemas de agentes podem alcançar. Esta combinação de novos métodos experimentais e medições robustas está preparada para acelerar o progresso no desenvolvimento da IA, permitindo aos investigadores desenvolver sistemas de agentes de forma mais eficaz.
Confira Conjunto de papel e dados. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a intersecção entre IA e soluções da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


