
A classificação causal é um campo importante no aprendizado de máquina que se concentra em distinguir fatores causais sutis de conjuntos de dados complexos, especialmente em situações onde a intervenção direta não é possível. Esta capacidade de descobrir estruturas causais sem intervenção é muito importante em todos os campos, como visão computacional, ciências sociais e ciências da vida, pois permite aos investigadores prever como os dados se comportarão sob várias condições hipotéticas. A classificação causal melhora a interpretação e a generalização da máquina, o que é importante para aplicações que exigem análises preditivas fortes.
Um grande desafio na inferência causal é identificar factores causais subjacentes sem depender de dados de intervenção, onde os investigadores utilizam cada factor independentemente para observar os seus efeitos. Esta limitação coloca restrições significativas em situações em que as intervenções podem ser mais eficazes devido a restrições éticas, de custos ou logísticas. Portanto, permanece uma questão persistente: quanto podem os investigadores aprender sobre estruturas causais apenas a partir de dados observacionais quando não há controlo direto para potenciais variáveis latentes? Os métodos tradicionais de identificação causal enfrentam dificuldades neste contexto, pois muitas vezes exigem certas suposições ou restrições que às vezes podem ser válidas.
Os métodos existentes baseiam-se frequentemente em dados de intervenção, assumindo que os investigadores podem manipular cada variável de forma independente para revelar a causalidade. Esses métodos também dependem de suposições restritivas, como regressão linear ou estruturas de parâmetros, que limitam sua aplicabilidade a conjuntos de dados sem restrições predefinidas. Algumas técnicas tentam superar essas limitações usando dados de múltiplas observações ou impondo restrições estruturais adicionais à variável latente. No entanto, estes métodos permanecem limitados apenas a situações observacionais, uma vez que necessitam de ser melhor adaptados a situações onde não estão disponíveis dados intervencionais ou sistemáticos.
Pesquisadores do Broad Institute do MIT e de Harvard apresentaram um novo método para abordar a classificação causal usando apenas dados observacionais, sem assumir acesso intervencionista ou parâmetros estruturais estritos. A abordagem deles usa modelos não lineares que incluem ruído gaussiano aditivo e uma função de integração linear desconhecida para identificar fatores causais. Esta abordagem criativa explora assimetrias na distribuição conjunta de dados observados para descobrir estruturas causais plausíveis. Ao focar nas assimetrias da distribuição natural dos dados, esta abordagem permite aos pesquisadores descobrir relações causais até transformações em camadas, marcando um importante passo em frente no estudo da representação causal sem intervenção.
O método proposto combina correspondência de pontos com um esquema quadrático para estimar adequadamente as estruturas causais. Utilizando as funções de pontuação estimadas a partir dos dados observados, a abordagem isola os fatores causais por otimização iterativa com um sistema quadrático. A flexibilidade deste método permite integrar várias ferramentas de pontuação, tornando-o adaptável a todos os diferentes conjuntos de dados observacionais. Os pesquisadores aplicam estimativas pontuais aos Algoritmos 1 e 2 para capturar e refinar camadas causais. Esta estrutura permite que o modelo funcione com qualquer sistema de pontuação, fornecendo uma solução flexível e escalável para problemas complexos de atribuição causal.
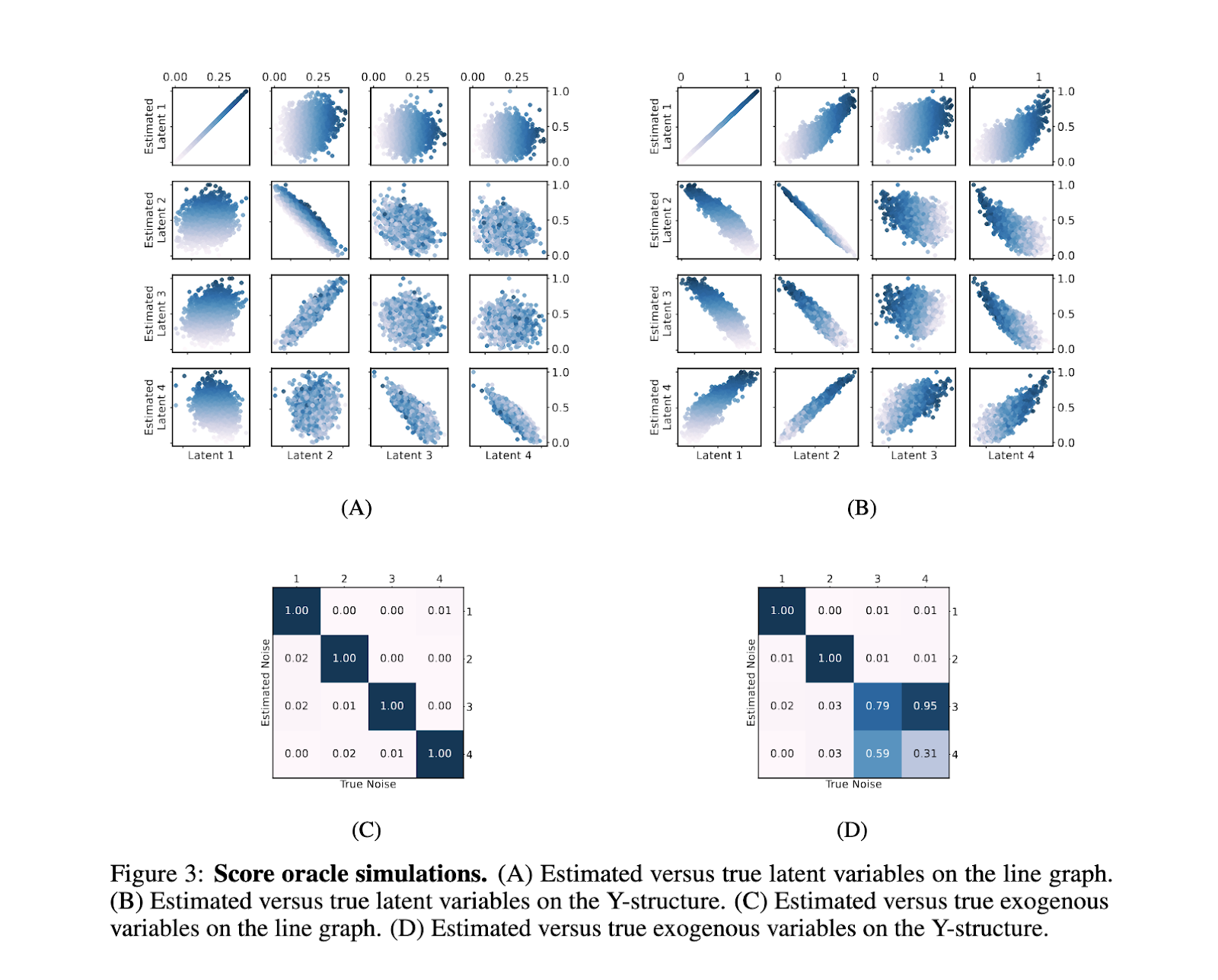
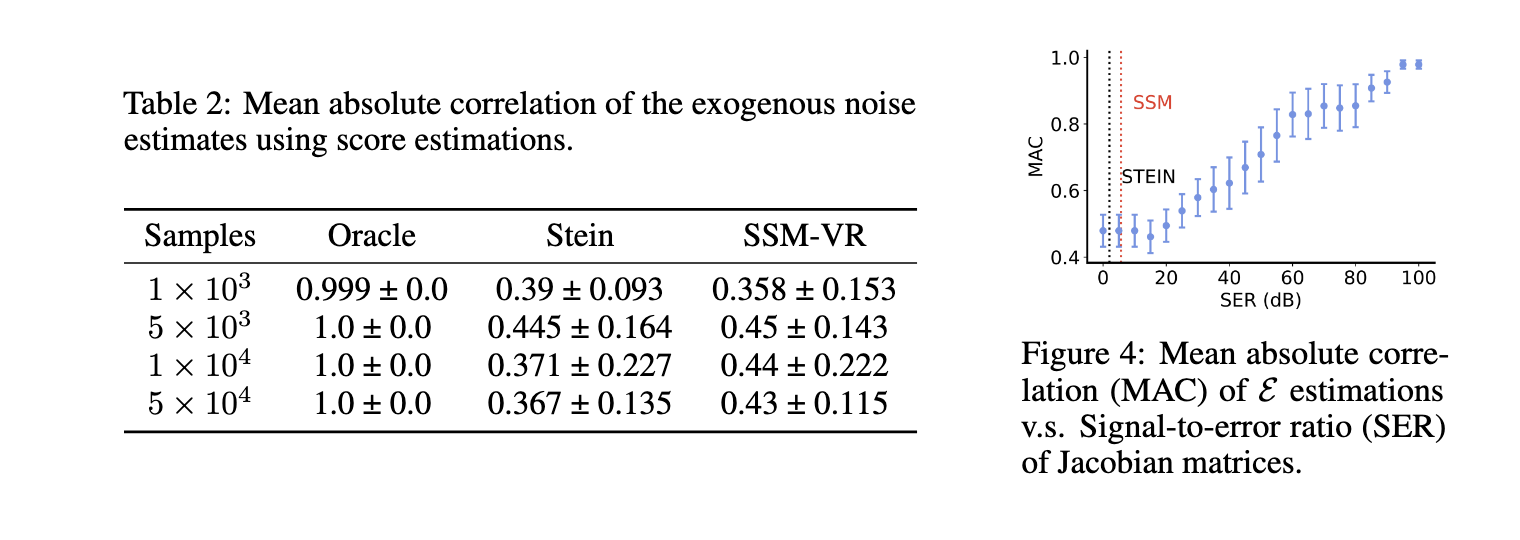
Um teste limitado do método apresentou resultados promissores, demonstrando sua praticidade e confiabilidade. Por exemplo, usando um gráfico causal de quatro nós em duas configurações – um gráfico de linha e uma estrutura Y, os pesquisadores geraram 2.000 amostras visuais e pontuações de computador com uma função de correlação de verdade. No gráfico de linhas, o algoritmo conseguiu uma separação completa de todas as variáveis, enquanto no gráfico Y separou com precisão as variáveis E1 e E2, embora tenha ocorrido alguma mistura com E3 e E4. Os valores da Correlação Média Absoluta (MAC) entre as variáveis de ruído verdadeiras e estimadas destacam a eficácia do modelo em representar com precisão as estruturas causais. O algoritmo manteve alta precisão em testes com estimativas pontuais ruidosas, confirmando sua robustez frente às condições de dados do mundo real. Estes resultados enfatizam a capacidade do modelo de distinguir estruturas causais de dados observacionais, confirmando as previsões teóricas do estudo.
Este estudo marca um grande avanço na inferência causal ao permitir a identificação de fatores causais sem depender de dados de intervenção. Esta abordagem aborda o problema contínuo de conseguir a identificação em dados observacionais, proporcionando uma forma flexível e eficiente de determinar a causalidade. Esta investigação abre novas possibilidades para a descoberta causal numa variedade de domínios, permitindo interpretações mais precisas e perspicazes em áreas onde a intervenção direta é desafiadora ou impossível. Ao melhorar o aprendizado de representação causal, a pesquisa abre caminho para aplicações mais amplas de aprendizado de máquina em campos que exigem análise e interpretação robusta de dados.
Confira Papel de novo Detalhes. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live LinkedIn event] 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão revitalizando o processo de desenvolvimento de dados para ajudar as equipes a construir modelos de IA multimodais revolucionários, rapidamente'
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


