
A tecnologia Natural Language to SQL (NL2SQL) emergiu como um elemento revolucionário do processamento de linguagem natural (PNL), permitindo aos usuários converter consultas de linguagem humana em instruções de linguagem estruturada (SQL). Esse desenvolvimento tornou mais fácil para indivíduos que precisam de muito conhecimento técnico interagir com bancos de dados complexos e encontrar informações importantes. Ao preencher a lacuna entre os sistemas de banco de dados e a linguagem natural, o NL2SQL abriu as portas para análises precisas de dados, especialmente em grandes bancos de dados de vários setores, melhorando a eficiência e a capacidade de tomada de decisões.
O principal problema do NL2SQL reside na compensação entre precisão e flexibilidade da consulta. Muitos métodos não conseguem gerar consultas SQL precisas e consistentes em diferentes bancos de dados. Outros dependem fortemente de modelos de linguagem em larga escala (LLMs) desenvolvidos através da engenharia da informação, que geram múltiplos resultados para selecionar a melhor consulta. No entanto, esta abordagem aumenta a carga computacional e limita as aplicações em tempo real. Por outro lado, a depuração supervisionada (SFT) fornece uma geração guiada de SQL, mas precisa de ajuda com aplicações entre domínios e operações complexas de banco de dados, deixando uma lacuna para novas estruturas.
Os pesquisadores já usaram diferentes abordagens para enfrentar os desafios do NL2SQL. A engenharia ágil se concentra na otimização de entradas para produzir resultados SQL com ferramentas como GPT-4 ou Claude 3.5 Sonnet, mas isso geralmente resulta em desempenho insatisfatório. SFT ajusta pequenos modelos para tarefas específicas, fornecendo resultados gerenciáveis, mas com diversidade limitada de consultas. Métodos híbridos como ExSL e Granite-34B-Code melhoram os resultados com treinamento aprimorado, mas enfrentam limitações na flexibilidade de grandes quantidades de informações. Esses métodos existentes enfatizam a necessidade de soluções que combinem precisão, flexibilidade e versatilidade na geração de consultas SQL.
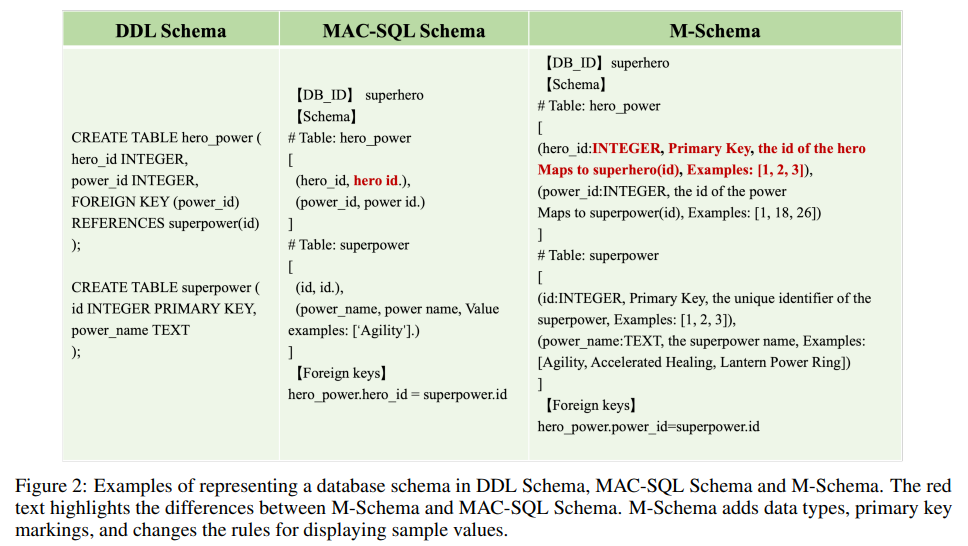
Pesquisadores do Grupo Alibaba presentes XiYan-SQLa estrutura básica do NL2SQL. Abrange múltiplas técnicas de integração de geradores e combina os recursos de engenharia rápida e SFT. Uma inovação importante no XiYan-SQL é o M-Schema, um método de representação de esquema semiestruturado que melhora a compreensão do sistema sobre estruturas sequenciais de banco de dados. Esta apresentação aborda conceitos-chave, como tipos de dados, chaves primárias e valores de instância, para aprimorar a capacidade do sistema de gerar consultas SQL precisas e apropriadas ao contexto. Essa abordagem permite que o XiYan-SQL gere candidatos SQL de alta qualidade enquanto otimiza a utilização de recursos.
XiYan-SQL usa um processo de três estágios para gerar e refinar consultas SQL. Primeiro, o esquema de ligação identifica os elementos relevantes do banco de dados, reduz informações estranhas e concentra-se em estruturas importantes. O programa então gera candidatos SQL usando geradores baseados em ICL e SFT. Isso garante diversidade na sintaxe e adaptabilidade a consultas complexas. Cada SQL gerado é refinado usando um modelo de depuração para eliminar erros lógicos ou estruturais. Finalmente, o modelo de seleção, ajustado para distinguir diferenças sutis entre os candidatos, seleciona a melhor pergunta. O XiYan-SQL vai além dos métodos tradicionais, combinando essas etapas em um pipeline compacto e eficiente.
O desempenho da estrutura foi verificado através de testes rigorosos em vários benchmarks. O XiYan-SQL alcançou uma precisão de implementação de 89,65% no conjunto de testes Spider, superando os modelos líderes anteriores por uma margem significativa. Ele obteve 69,86% no SQL-Eval, superando o SQL-Coder-8B em mais de oito pontos percentuais. Mostrou adaptabilidade excepcional a conjuntos de dados não relacionados, obtendo uma precisão de 41,20% em NL2GQL, que é a mais alta entre todos os modelos testados. O XiYan-SQL obteve uma pontuação competitiva de 72,23% no desafiador benchmark de desenvolvimento Bird, competindo de perto com o método de melhor desempenho, que obteve uma pontuação de 73,14%. Esses resultados destacam a compatibilidade e precisão do XiYan-SQL em diversas situações.
As principais conclusões do estudo incluem o seguinte:
- Nova representação de esquema: A introdução do M-Schema melhora muito a compreensão do banco de dados, incluindo estruturas hierárquicas, tipos de dados e chaves primárias. Essa abordagem reduz a duplicação e melhora a precisão da consulta.
- Geração avançada de candidatos: XiYan-SQL usa geradores bem ajustados e baseados em ICL para gerar vários candidatos SQL. O método de treinamento multitarefa melhora a qualidade das consultas em vários estilos sintáticos.
- Correção e seleção robusta de erros: a estrutura usa um filtro SQL para otimizar consultas e um modelo de seleção para garantir que o melhor candidato seja selecionado. Este método substitui técnicas de estabilidade ineficazes.
- Versatilidade comprovada: testes em benchmarks como Spider, Bird, SQL-Eval e NL2GQL demonstram a capacidade do XiYan-SQL de se adaptar a bancos de dados relacionais e não relacionais.
- Desempenho de última geração: XiYan-SQL supera consistentemente os modelos líderes, alcançando pontuações impressionantes como 89,65% em Spider e 41,20% em NL2GQL, estabelecendo novos padrões para estruturas NL2SQL.


Concluindo, XiYan-SQL aborda desafios persistentes em operações NL2SQL combinando representação de esquema avançada, várias técnicas de geração de SQL e métodos intuitivos de seleção de consultas. Alcança uma abordagem equilibrada em termos de precisão e adaptabilidade, superando as estruturas tradicionais na maioria dos benchmarks. Esta pesquisa enfatiza a importância da inovação em sistemas NL2SQL e abre caminho para uma adoção mais ampla de ferramentas de interação com bancos de dados. XiYan-SQL é um exemplo de como a integração estratégica de tecnologia pode redefinir sistemas de consulta complexos, fornecendo uma base sólida para desenvolvimentos futuros no acesso a dados.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Conferência Virtual GenAI gratuita com. Meta, Mistral, Salesforce, Harvey AI e mais. Junte-se a nós em 11 de dezembro para este evento de visualização gratuito para aprender o que é necessário para construir grande com pequenos modelos de pioneiros em IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face e muito mais.
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
🐝🐝 Evento do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar o modelo de suas equipes – a IA está mudando o jogo, rápido.


