 lança OLMo 2: uma nova família de modelos de linguagem 7B e 13B de código aberto treinados em tokens de até 5T")
O desenvolvimento da modelagem de linguagem concentra-se na criação de sistemas de inteligência artificial que possam processar e produzir texto com fluência semelhante à humana. Esses modelos desempenham um papel importante na tradução automática, geração de conteúdo e sistemas de conversação de IA. Eles contam com extensos conjuntos de dados e algoritmos de treinamento sofisticados para aprender padrões de linguagem, permitindo-lhes compreender o contexto, responder perguntas e criar textos coerentes. A rápida evolução neste campo destaca a crescente importância das contribuições de código aberto, que visam democratizar o acesso a poderosos sistemas de IA.
Um problema persistente neste campo tem sido o domínio de modelos proprietários, que tendem a superar os sistemas de código aberto devido aos seus extensos recursos e pipelines de treinamento avançados. Os sistemas proprietários geralmente usam grandes conjuntos de dados, poder computacional e métodos proprietários avançados, criando uma lacuna de desempenho que requer modelagem para ser preenchida. Esta diferença limita a acessibilidade e a inovação na IA, uma vez que apenas organizações bem financiadas podem desenvolver tais tecnologias.
Embora louváveis, os atuais métodos de código aberto ainda precisam enfrentar plenamente os desafios de robustez, estabilidade de treinamento e desempenho do modelo. Muitos modelos são parcialmente abertos, fornecendo apenas conjuntos de dados ou métodos limitados, ou são totalmente abertos, mas exigem uma vantagem competitiva sobre os seus homólogos proprietários. No entanto, os desenvolvimentos recentes abrem caminho para uma nova geração de modelos totalmente abertos e competitivos em termos de desempenho.
A equipe de pesquisa de IA do Allen Institute foi lançada OMO 2uma família básica de modelos de linguagem de código aberto. Esses modelos, disponíveis em configurações de parâmetros de 7 bilhões (7B) e 13 bilhões (13B), foram treinados com até 5 trilhões de tokens usando técnicas de última geração. Ao refinar a estabilidade do treinamento, adotando processos de treinamento em etapas e integrando diversos conjuntos de dados, os pesquisadores estão preenchendo a lacuna de desempenho com sistemas proprietários como o Llama 3.1. OLMo 2 melhora a normalização da camada, a incorporação posicional rotativa e a regularização da perda Z para melhorar a robustez do modelo.
A formação OLMo 2 utilizou uma abordagem curricular em duas fases. Na primeira etapa, que cobre 90% do orçamento de pré-treinamento, os modelos são treinados no conjunto de dados OLMo-Mix-1124, que inclui 3,9 bilhões de tokens retirados de vários repositórios de alta qualidade, como DCLM e Starcoder. A segunda fase envolveu o ajuste fino do Dolmino-Mix-1124, um conjunto de dados com curadoria de 843 bilhões de tokens com conteúdo baseado na web e específico de domínio. Técnicas como o modelo sopa, que combina pontos de controle para melhorar a eficiência, foram essenciais para a obtenção das versões finais dos modelos 7B e 13B.
A funcionalidade do OLMo 2 estabelece novos padrões de referência no campo da modelagem de linguagem de código aberto. Comparado ao seu antecessor, OLMo-0424, o OLMo 2 apresenta melhorias significativas em todas as funções de teste. OLMo 2 7B supera Llama-3.1 8B significativamente, e OLMo 2 13B supera Qwen 2.5 7B, apesar de usar menos FLOPs de treinamento. Os testes utilizando o Sistema Aberto de Avaliação de Modelagem de Linguagem (OLMES), uma série de 20 benchmarks, confirmaram esses benefícios, destacando os pontos fortes em recordação, raciocínio e habilidades linguísticas gerais.
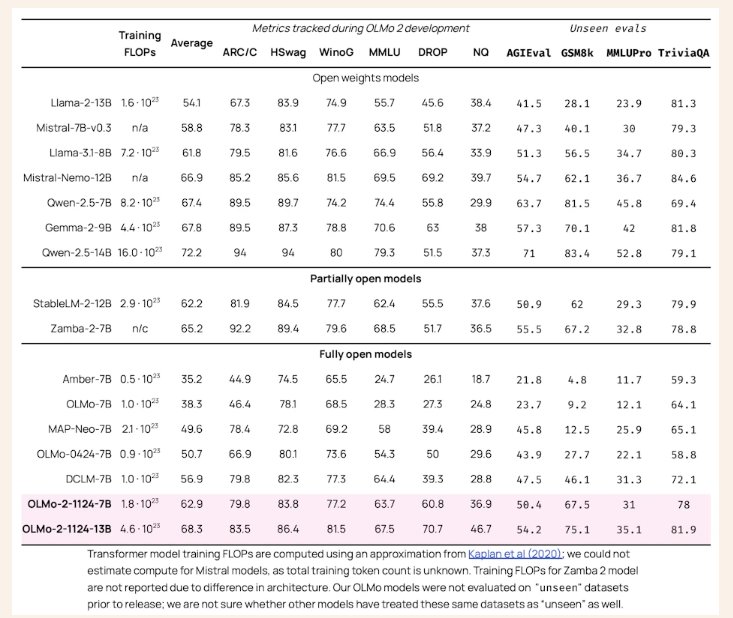
As principais conclusões do estudo incluem o seguinte:
- Desenvolvimento da estabilidade do treinamento: Técnicas como RMSNorm e taxa de aprendizagem reduzem picos de perdas durante o pré-treinamento, garantindo desempenho consistente do modelo.
- Novo estágio de treinamento: Intervenções recentes de formação, incluindo ajustes curriculares de dados, permitiram o desenvolvimento direcionado de competências de modelização.
- Estrutura de avaliação acionável: O lançamento do OLMES forneceu métricas sistemáticas para orientar o desenvolvimento do modelo e acompanhar eficazmente o progresso.
- Métodos pós-treinamento: O condicionamento positivo supervisionado, o ajuste de preferência e o aprendizado por reforço com recompensas garantidas melhoraram a capacidade dos modelos de seguir as instruções.
- Diversidade e qualidade do conjunto de dados: O pré-treinamento em conjuntos de dados como Dolmino-Mix-1124 garantiu que os modelos pudessem se adaptar a diferentes domínios.
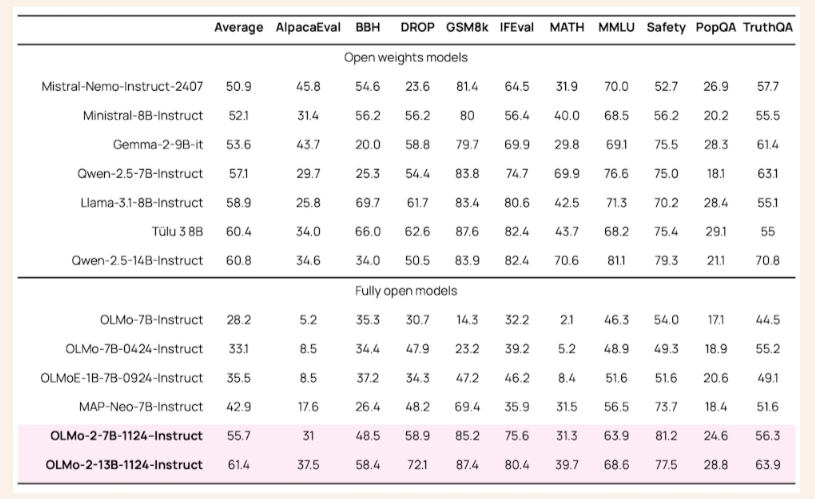

Concluindo, as conquistas do OLMo 2 significam uma mudança no cenário de modelagem de linguagem. Ao abordar desafios como a estabilidade da formação e a transparência dos testes, os investigadores estabeleceram um novo padrão para a IA de código aberto. Estes modelos preenchem a lacuna com sistemas proprietários e demonstram o poder da inovação colaborativa no desenvolvimento da inteligência artificial. O programa OLMo 2 enfatiza o poder transformador do acesso aberto a modelos de IA de alto desempenho, abrindo caminho para um desenvolvimento tecnológico equitativo.
Confira Modelos e detalhes de rosto eloquente. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


