
Modelos de linguagem em larga escala (LLMs) surgiram como ferramentas poderosas no processamento de linguagem natural, mas a compreensão de suas representações internas continua sendo um grande desafio. Avanços recentes usando codificadores automáticos discretos revelaram “recursos” ou conceitos interpretáveis dentro do espaço de abertura do modelo. Embora estas nuvens de características detectadas sejam agora acessíveis ao público, compreender a sua complexa organização estrutural em diferentes escalas apresenta um importante problema de investigação. A análise dessas estruturas envolve muitos desafios: identificar padrões geométricos em nível atômico, compreender a modularidade funcional em escala média e examinar a distribuição geral de características em grande escala. As abordagens tradicionais têm lutado para fornecer uma compreensão abrangente de como essas diferentes escalas interagem e contribuem para o comportamento do modelo, tornando imperativo o desenvolvimento de novos métodos para analisar essas estruturas multiescalares.
Tentativas anteriores de um método para compreender as propriedades características do LLM seguiram diversas abordagens diferentes, cada uma com suas próprias limitações. Autoencoders esparsos (SAE) surgiram como um método não supervisionado para detectar recursos descritivos, que primeiro revelam clusters de recursos relacionados baseados em vizinhança por meio de projeções UMAP. Os primeiros métodos de incorporação de palavras, como GloVe e Word2vec, descobriram relações lineares entre conceitos semânticos, mostrando padrões geométricos básicos semelhantes a relações de correspondência. Embora estes métodos forneçam informações importantes, eles foram limitados pelo seu foco na análise de medida única. As técnicas Meta-SAE tentaram decompor as características em componentes mais atômicos, sugerindo uma estrutura hierárquica, mas têm lutado para capturar toda a complexidade das interações em múltiplas escalas. A análise vetorial de funções em modelos lineares revelou representações lineares de vários conceitos, desde espaço de jogo até valor numérico, mas esses métodos são frequentemente focados em domínios específicos, em vez de fornecer uma compreensão completa da estrutura geométrica do espaço de características em todas as escalas diferentes.
Pesquisadores do Instituto de Tecnologia de Massachusetts propõem um método robusto para analisar estruturas geométricas em espaços de características SAE no sentido de “estruturas cristalinas” – padrões que mostram relações semânticas entre conceitos. Esta abordagem vai além de simples relações de paralelogramo (como masculino:feminino::rei:rainha) para incluir estruturas trapezoidais, que representam relações vetoriais de uma única função, como um mapa país-capital. Investigações preliminares revelaram que estes padrões geométricos são frequentemente obscurecidos por “fatores de distração” – medidas semanticamente irrelevantes, como o comprimento das palavras, que distorcem as relações geométricas esperadas. Para enfrentar esse desafio, o estudo apresenta um método refinado usando Análise Discriminante Linear (LDA) para usar dados em um subespaço de baixa dimensão, filtrando efetivamente esses recursos de bug. Este método permite a identificação clara de padrões geométricos significativos, concentrando-se nos modos próprios da relação sinal-ruído, onde o sinal representa a variabilidade dos grupos e o ruído representa a variabilidade intra-cluster.

A metodologia se estende à análise de estruturas de grande escala, investigando a modularidade funcional dentro do espaço de características SAE, semelhante a regiões especializadas do cérebro biológico. Este método identifica “lóbulos” funcionais através de um processo sistemático de análise de eventos de recursos no processamento de documentos. Usando uma camada SAE residual 12 com 16.000 recursos, o estudo processa documentos do conjunto de dados The Pile, considerando recursos como “disparar” quando sua função oculta excede 1 e registrando eventos correspondentes dentro de 256 blocos de token. A análise usa várias métricas de afinidade (coeficiente de similaridade simples, similaridade de Jaccard, coeficiente de dados, coeficiente de sobreposição e coeficiente Phi) para medir o relacionamento característico, seguido de agrupamento visual. Para confirmar a hipótese de modularidade espacial, a pesquisa utiliza dois métodos de medição: comparando as informações mútuas entre os resultados de agrupamento baseados em geometria e baseados em co-ocorrência e o treinamento de modelos de regressão logística para prever os lóbulos funcionais a partir das posições geométricas. Esta abordagem abrangente visa determinar se os fatores relacionados ao desempenho exibem convergência espacial no espaço de ativação.
A análise da grande estrutura “galáctica” da nuvem de características SAE revela padrões distintos de uma distribuição isotrópica gaussiana simples. O exame dos três primeiros componentes principais mostra que a nuvem de pontos apresenta uma forma assimétrica, com larguras variadas ao longo dos eixos principais. Essa estrutura é semelhante às organizações neurais biológicas, especialmente à estrutura assimétrica do cérebro humano. Esta descoberta sugere que o espaço de características mantém uma distribuição sistemática e aleatória, mesmo em uma grande escala de análise.
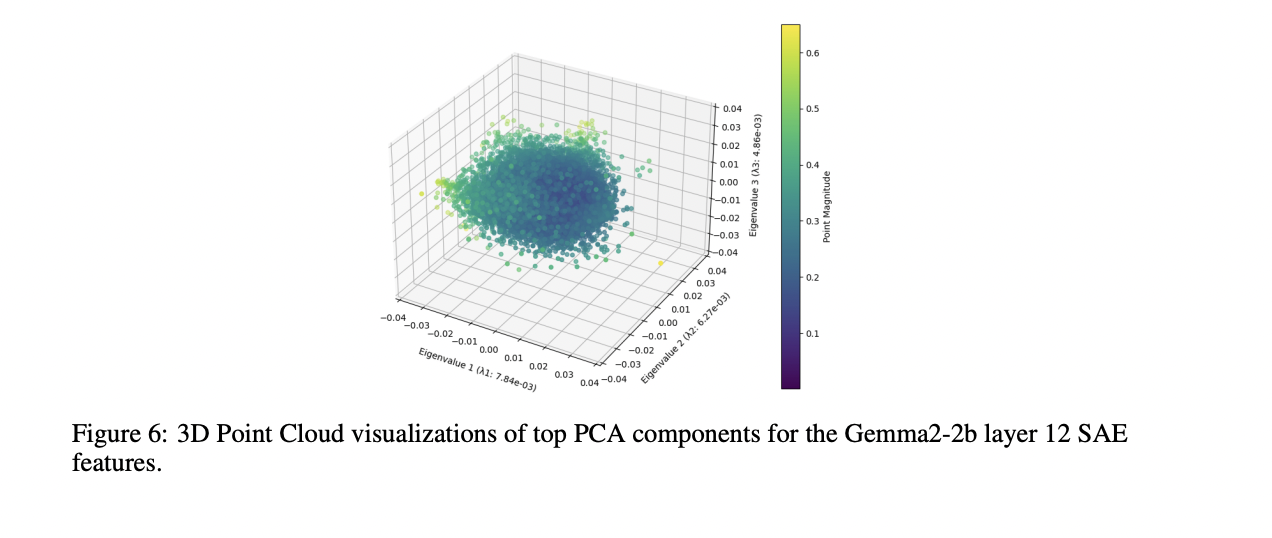
A análise multidimensional da nuvem de recursos SAE revela três níveis distintos de organização estrutural. No nível atômico, os padrões geométricos que aparecem na forma de paralelogramos e trapézios representam relações semânticas, principalmente quando os elementos distratores são removidos. O nível intermediário apresenta funcionalidade semelhante aos sistemas neurais biológicos, com regiões especializadas para tarefas específicas, como matemática e codificação. A estrutura em escala galáctica mostra uma distribuição não isotrópica com uma lei de potência característica de autovalores, que é mais pronunciada para as camadas centrais. Essas descobertas melhoram muito a compreensão de como os modelos de linguagem organizam e representam informações em diferentes escalas.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Trending] LLMWare apresenta Model Depot: uma coleção abrangente de modelos de linguagem pequena (SLMs) para PCs Intel
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


