")
Os modelos linguísticos multimodais de grande escala (MLLMs) representam uma área líder em inteligência artificial, combinando várias modalidades de dados, como texto, imagens e vídeo, para construir uma compreensão unificada entre domínios. Esses modelos estão sendo desenvolvidos para lidar com tarefas cada vez mais complexas, como resposta visual a consultas, geração de texto para imagem e interpretação de dados multimodais. O objetivo final dos MLLMs é permitir que os sistemas de IA pensem e raciocinem com habilidades semelhantes às humanas, compreendendo simultaneamente múltiplas formas de dados. Este campo tem tido um rápido desenvolvimento, mas ainda existe um desafio na criação de modelos que possam integrar estas diversas entradas, mantendo ao mesmo tempo alto desempenho, escalabilidade e generalidade.
Uma das questões críticas enfrentadas pelo desenvolvimento de MLLMs é conseguir uma forte interoperabilidade entre diferentes tipos de dados. Os modelos existentes geralmente exigem ajuda para equilibrar o processamento de texto e as informações visuais, levando à degradação do desempenho ao lidar com imagens ricas em texto ou tarefas visuais básicas com letras miúdas. Além disso, esses modelos precisam de ajuda para manter um alto nível de compreensão do contexto ao trabalhar com múltiplas imagens. À medida que aumenta a procura por modelos multivariados, os investigadores procuram novas formas de melhorar a capacidade do MLLM para enfrentar estes desafios, tornando assim os modelos capazes de lidar com situações complexas sem sacrificar a eficiência ou a precisão.
Os métodos tradicionais em MLLMs dependem fortemente de treinamento unilateral e não utilizam todo o potencial de combinação de dados visuais e textuais. Isso resulta em um modelo que pode funcionar bem em qualquer linguagem ou tarefa virtual, mas tem dificuldades em contextos multimodais. Embora os métodos recentes tenham integrado grandes conjuntos de dados e estruturas complexas, ainda sofrem de ineficiências na combinação dos dois tipos de dados. Há uma necessidade crescente de modelos que possam ter um bom desempenho em tarefas que exigem interação entre imagens e texto, como referência de objetos e raciocínio visual, ao mesmo tempo que permanecem computacionalmente viáveis e utilizáveis em escala.
Os pesquisadores da Apple desenvolveram um MM1.5 O modelo familiar também introduz diversas inovações para superar essas limitações. Os modelos MM1.5 melhoram as capacidades do seu antecessor, o MM1, melhorando a compreensão de imagens ricas em texto e o raciocínio multi-imagens. Os pesquisadores adotaram uma nova abordagem orientada a dados, combinando dados OCR de alta resolução com legendas artificiais em uma fase de treinamento contínuo. Isso permite significativamente que os modelos MM1.5 tenham um desempenho melhor que os modelos anteriores em direção visual e tarefas de posicionamento. Além dos MLLMs de uso geral, a família de modelos MM1.5 inclui duas variantes especiais: MM1.5-Vídeo para entender o vídeo e MM1.5-UI para entender a interface do usuário móvel. Esses modelos de destino fornecem soluções projetadas para casos de uso específicos, como interpretação de dados de vídeo ou análise de layouts de telas móveis.
MM1.5 usa uma estratégia de treinamento única que envolve três fases principais: pré-treinamento em larga escala, pré-treinamento de alta resolução e ajuste fino supervisionado (SFT). A primeira fase utiliza um grande conjunto de dados que inclui 2 mil milhões de pares imagem-texto, 600 milhões de documentos imagem-texto encriptados e 2 biliões de tokens de dados apenas de texto, proporcionando uma base sólida para a compreensão multimodal. A segunda fase envolve treinamento contínuo adicional usando 45 milhões de pontos de dados de OCR de alta qualidade e 7 milhões de legendas artificiais, o que ajuda a melhorar o desempenho do modelo em tarefas de imagem baseadas em texto. O estágio final, SFT, desenvolve o modelo usando uma combinação bem escolhida de dados de imagem única, multiimagem e somente texto, tornando-o capaz de lidar com referência visual bem refinada e raciocínio multiimagem.

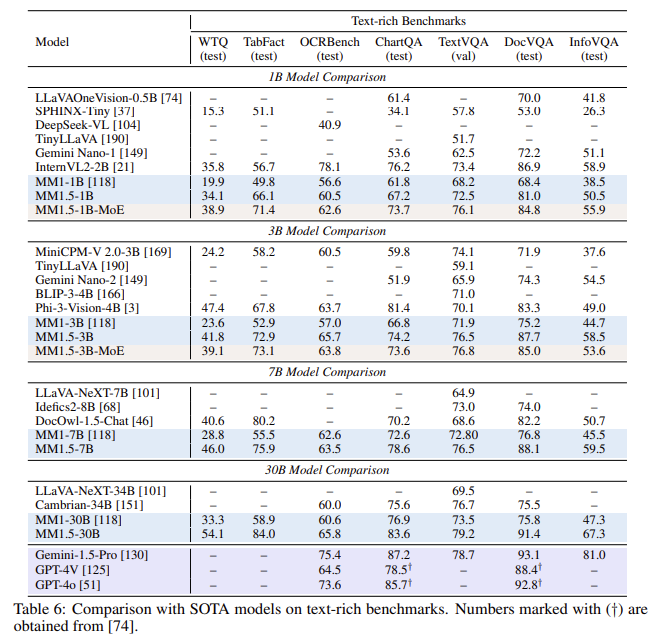
Os modelos MM1.5 foram testados em diversos benchmarks, apresentando desempenho superior aos modelos de código aberto e proprietários em diversas tarefas. Por exemplo, a variante densa MM1.5 e o MoE variam de 1 a 30 bilhões de parâmetros, obtendo resultados competitivos mesmo em pequenas escalas. A melhoria de desempenho é particularmente evidente na compreensão de imagens ricas em texto, onde os modelos MM1.5 apresentam uma melhoria de 1,4 pontos em relação aos modelos anteriores em alguns benchmarks. Além disso, o MM1.5-Video, treinado apenas em dados de imagem sem dados específicos de vídeo, alcançou resultados de última geração em tarefas de reconhecimento de vídeo usando seus fortes recursos multimodais de uso geral.
Extensos estudos de pesquisa conduzidos em modelos MM1.5 revelaram muitos insights importantes. Os pesquisadores demonstraram que o processamento de dados e técnicas de treinamento apropriadas podem produzir um desempenho robusto mesmo em escalas de parâmetros baixos. Além disso, a combinação de dados de OCR com legendas realizadas durante a fase avançada de pré-treinamento aumenta muito a compreensão do texto em diversas resoluções de imagem e proporções de aspecto. Esses insights abrem caminho para o desenvolvimento de MLLMs eficientes no futuro, que podem fornecer resultados de alta qualidade sem exigir modelos muito grandes.
Principais conclusões do estudo:
- Especificações do modelo: Isto inclui modelos densos e MoE com parâmetros que variam de 1B a 30B, garantindo durabilidade e flexibilidade.
- Dados de treinamento: Ele usa um par de texto de imagem 2B, documentos de texto de imagem 600M e tokens somente texto 2T.
- Recursos especiais: MM1.5-Video e MM1.5-UI fornecem soluções complementares para compreensão de vídeo e análise de UI móvel.
- Melhoria de desempenho: Alcançou um ganho de 1,4 pontos em benchmarks com foco na clareza de imagem com texto em comparação aos modelos anteriores.
- Integração de dados: O uso de dados OCR de alta resolução de 45 milhões e legendas sintéticas de 7 milhões aumenta muito o poder do modelo.

Concluindo, a família de modelos MM1.5 estabelece uma nova referência para grandes modelos multilíngues, oferecendo compreensão aprimorada de imagens ricas em texto, suporte visual e recursos de processamento multi-imagem. Com suas estratégias de dados cuidadosamente selecionadas, variantes específicas de tarefas e arquitetura incontrolável, o MM1.5 está preparado para enfrentar os principais desafios da IA multimodal. Os modelos propostos mostram que a combinação de métodos de treinamento robustos com técnicas de aprendizagem contínua pode levar a um MLLM altamente eficiente e flexível em uma variedade de aplicações, desde a compreensão geral de texto de imagem até a compreensão especializada de vídeo e UI.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
 para geração eficiente de dados incorporados em grande escala")

: um novo método prático projetado para melhorar as habilidades de compreensão de imagens para modelos de linguagem visual em larga escala (LVLMs)")