
A classificação semântica da área glótica a partir de sequências de vídeo videoendoscópicas de alta velocidade (HSV) apresenta um desafio importante na imagem laríngea. A área enfrenta uma grave escassez de conjuntos de dados anotados de alta qualidade para treinar modelos de classificação robustos. Portanto, o desenvolvimento da tecnologia de segmentação automática é dificultado por esta limitação e a criação de ferramentas de diagnóstico como as Reproduções Facilitativas (FPs) são essenciais para avaliar a dinâmica vibracional nas pregas vocais. A disponibilidade limitada de conjuntos de dados abrangentes é um desafio para os médicos quando tentam encontrar um diagnóstico preciso e um tratamento adequado dos problemas de voz, o que cria uma enorme lacuna tanto nas atividades de investigação como nas práticas clínicas.
As técnicas atuais de segmentação glótica incluem técnicas clássicas de processamento de imagens, incluindo contornos ativos e transições de água. A maioria dessas técnicas geralmente requer uma grande quantidade de entrada manual e não pode lidar com diferentes condições de iluminação ou condições complexas de fechamento da glote. Por outro lado, os modelos de aprendizagem profunda, embora promissores, são limitados pela necessidade de grandes conjuntos de dados e anotações de alta qualidade. Conjuntos de dados como o BAGLS, que estão disponíveis publicamente, fornecem gravações em escala de cinza, mas são menos distintos e granulares, o que também reduz sua capacidade de produzir tarefas de classificação complexas. Esses fatores enfatizam a necessidade urgente de conjuntos de dados que ofereçam melhor flexibilidade, recursos mais complexos e relevância clínica mais ampla.
Pesquisadores da Universidade de Brest, da Universidade de Patras e da Universidade Politécnica de Madrid apresentaram o conjunto de dados GIRAFE para abordar as limitações dos recursos existentes. GIRAFE é um arquivo robusto e abrangente que inclui 65 registros de HSV de 50 pacientes, cada um cuidadosamente anotado com máscaras de classificação. Ao contrário de outros conjuntos de dados, a vantagem do GIRAFE é que ele fornece registros de HSV em cores, tornando visíveis características anatômicas e patológicas sutis. Este recurso permite aos pesquisadores realizar experimentos de alta resolução envolvendo métodos clássicos de classificação, como InP e Loh, bem como as mais recentes estruturas neurais profundas, como UNet e SwinUnetV2. Além da segmentação de alta resolução, este trabalho também facilita a reprodução assistida, incluindo GAW, GVG e PVG, que são mídias muito importantes onde os padrões modais de vibração na prega vocal podem ser identificados para aprender mais sobre a dinâmica da voz. dobrar.
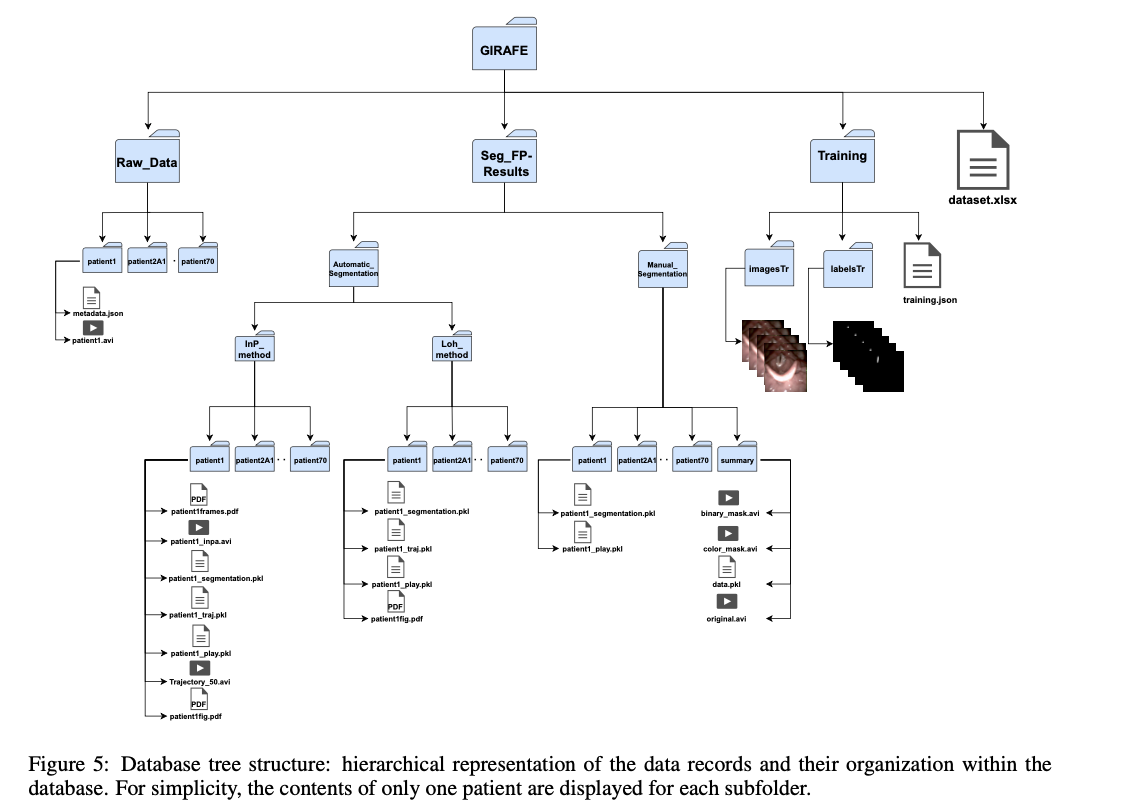
O conjunto de dados GIRAFE cobre uma ampla gama de recursos dignos de extensa pesquisa. Inclui 760 quadros certificados e anotados; tal configuração permite treinamento e testes adequados usando a máscara de separação adequada. Este conjunto de dados inclui técnicas tradicionais de processamento de imagens, como InP e Loh, e arquiteturas avançadas de aprendizagem profunda. As gravações HSV são capturadas com alta resolução temporal de 4.000 quadros por segundo com resolução espacial de 256×256 pixels, o que garante análise detalhada da dinâmica da fala. O conjunto de dados é organizado em arquivos estruturados, incluindo \Raw_Data, \Seg_FP-Results e \Training, facilitando o acesso e integração em pipelines de pesquisa. Esta combinação de registro sistemático e colorido facilita a visualização das características glóticas e permite a avaliação de padrões de vibração complexos em muitas situações clínicas.
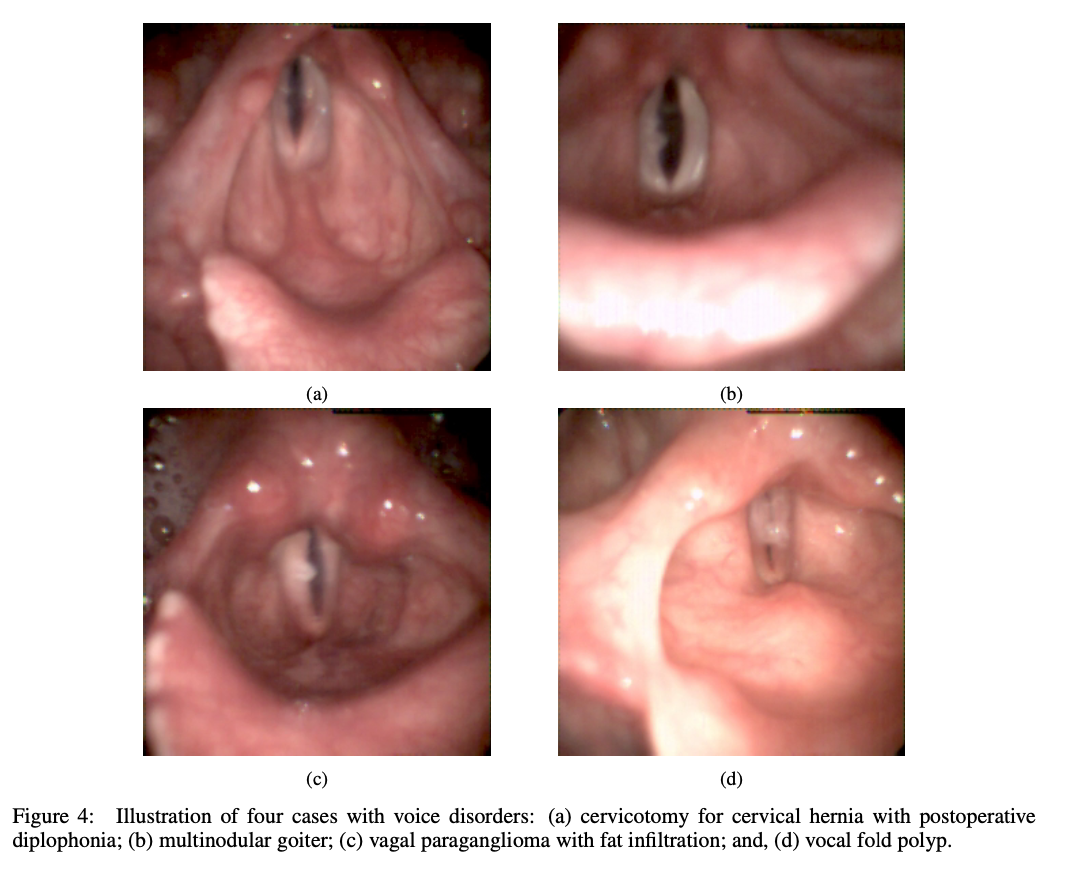
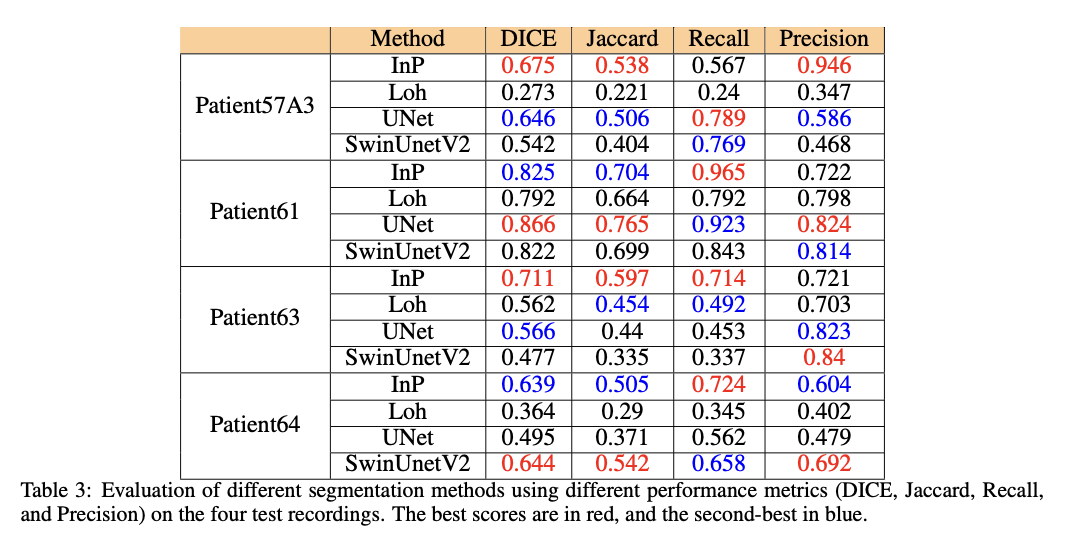
O conjunto de dados GIRAFE demonstrou a sua eficácia no desenvolvimento de técnicas de classificação com validação abrangente utilizando métodos convencionais e aprendizagem profunda. Os métodos de classificação convencionais, como o método InP, tiveram um bom desempenho numa variedade de condições desafiadoras, indicando que são robustos e podem lidar com casos complexos. Modelos de aprendizagem profunda como UNet e SwinUnetV2 também mostraram bom desempenho; No entanto, o UNet teve um desempenho melhor do que outros na precisão da segmentação em casos simples. A diversidade do conjunto de dados, contendo diversas doenças, condições de luz e variações anatômicas, tornou-o um marcador útil. Estes resultados confirmam que o conjunto de dados pode contribuir para o melhor desenvolvimento e avaliação de métodos de classificação e para apoiar o estabelecimento de aplicações clínicas de imagem laríngea.
O conjunto de dados GIRAFE representa um marco importante no campo da pesquisa de imagens da laringe. Com a inclusão de gravações de cores HSV, várias anotações e a integração de métodos tradicionais e de aprendizagem profunda, este conjunto de dados aborda as limitações dos conjuntos de dados atuais e estabelece uma nova referência dentro do domínio. Este conjunto de dados ajuda a integrar ainda mais os métodos tradicionais e modernos, ao mesmo tempo que fornece uma base confiável para o desenvolvimento de métodos sofisticados de classificação e ferramentas de diagnóstico. Suas contribuições podem revolucionar o diagnóstico e o manejo dos distúrbios da voz e, como tal, podem ser um excelente recurso para médicos e pesquisadores que buscam avançar no campo da dinâmica das pregas vocais e diagnósticos relacionados.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


