
A inteligência artificial fez grandes avanços com o desenvolvimento de modelos de linguagem em larga escala (LLMs), que têm um impacto significativo em uma variedade de áreas, incluindo processamento de linguagem natural, raciocínio e tarefas de codificação. À medida que os LLMs se tornam mais poderosos, eles precisam de métodos mais sofisticados para melhorar o seu desempenho durante a previsão. Técnicas de tempo de design e técnicas utilizadas para melhorar a qualidade das respostas produzidas por esses modelos em tempo de execução são muito importantes. No entanto, a comunidade científica ainda não estabeleceu as melhores práticas para integrar estas técnicas num sistema unificado.
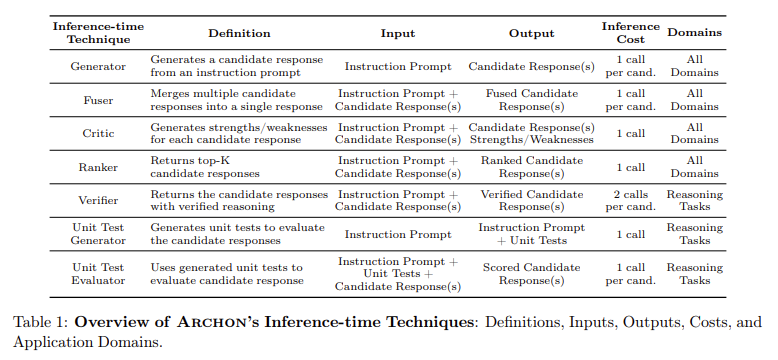
Um desafio importante para melhorar o desempenho do LLM é determinar quais estratégias de brainstorming produzem os melhores resultados para diferentes tarefas. O problema é composto por uma variedade de tarefas, como seguir instruções, raciocínio e codificação, que podem se beneficiar de diversas combinações de técnicas de tempo de previsão. Além disso, compreender a interação complexa entre técnicas como agrupamento, amostragem repetida, classificação, agrupamento e validação é fundamental para maximizar o desempenho. Os pesquisadores precisam de um sistema robusto que possa explorar com eficiência o amplo espaço de design de combinações possíveis e expandir essas estruturas de acordo com as tarefas e restrições computacionais.
As abordagens tradicionais para melhorar o tempo de reflexão concentraram-se no uso de técnicas individuais em LLMs. Por exemplo, o agrupamento envolve perguntar a vários modelos de uma vez e escolher a melhor resposta, enquanto a amostragem repetida envolve perguntar a um único modelo várias vezes. Estas estratégias têm-se mostrado promissoras, mas a sua utilização independente conduz muitas vezes a melhorias limitadas. Estruturas como a Mistura de Agentes (MoA) e o LeanStar tentaram integrar múltiplas estratégias, mas ainda enfrentam desafios na integração e no trabalho em múltiplas funções. Portanto, há uma necessidade crescente de uma abordagem modular e automatizada para a construção de programas avançados de LLM.
Pesquisadores da Universidade de Stanford e da Universidade de Washington o desenvolveram O Arconteé uma estrutura modular projetada para automatizar a busca de estruturas LLM usando técnicas de reflexão. A estrutura Archon usa vários LLMs e métodos de tempo preditivo, combinando-os em um sistema unificado que supera os modelos tradicionais. Em vez de depender de um único LLM apresentado uma vez, o Archon seleciona, integra e empilha dinamicamente camadas estratégicas para melhorar o desempenho em benchmarks específicos. Ao tratar o problema como uma tarefa de otimização de hiperparâmetros, a estrutura pode identificar arquiteturas ideais que maximizam a precisão, a latência e a eficiência de custos para um determinado orçamento de computação.
A estrutura Archon é construída como um sistema multicamadas onde cada camada executa um processo de tempo lógico diferente. Por exemplo, a primeira camada pode gerar múltiplas respostas candidatas usando um conjunto de LLMs, enquanto as camadas subsequentes usam métodos de escalonamento, agrupamento ou validação para refinar essas respostas. A estrutura usa algoritmos de otimização Bayesiana para procurar configurações possíveis e selecionar o benchmark alvo mais eficiente. Este design modular permite que o Archon supere os modelos mais eficientes, como o GPT-4o e o Claude 3.5 Sonnet, com uma pontuação média de 15,1% na maioria das tarefas.
O desempenho do Archon foi avaliado em vários benchmarks, incluindo MT-Bench, Arena-Hard-Auto, AlpacaEval 2.0, MixEval, MixEval Hard, MATH e CodeContests. Os resultados foram convincentes: as construções do Archon mostraram uma precisão média de 11,2 pontos usando modelos de código aberto e 15,1% usando uma combinação de modelos de código aberto e de código fechado. Nas tarefas de codificação, a estrutura alcançou uma melhoria de 56% nas pontuações Pass@1, aumentando a precisão de 17,9% para 29,3% para geração e teste de testes unitários. Mesmo quando restrito a modelos de código aberto, o Archon superou os modelos de chamada única de última geração em 11,2%, destacando a eficácia de sua abordagem em camadas.
Os principais resultados mostram que Archon alcança desempenho de última geração em vários domínios, combinando múltiplas técnicas em tempo real. Em tarefas prescritivas, adicionar múltiplas camadas de geração, classificação e integração melhorou muito a qualidade das respostas. Archon se destaca em tarefas de raciocínio como MixEval e MATH, combinando métodos de validação com métodos de teste unitário, resultando em um aumento médio de 3,7 a 8,9 por cento ao usar arquiteturas específicas de tarefas. A estrutura incorporou amostragem múltipla e geração de testes unitários para produzir resultados precisos e confiáveis para desafios de codificação.
Principais conclusões do estudo Archon:
- Aumente o desempenho: O Archon alcança um aumento médio de precisão de 15,1% em vários benchmarks, com modelos de ponta como o GPT-4o e o Claude 3.5 Sonnet com bom desempenho.
- Várias aplicações: A estrutura é excelente em tarefas de instrução, consultoria e codificação, demonstrando versatilidade.
- Estratégias eficazes de tempo de segmentação: Archon oferece alto desempenho em todos os cenários testados, combinando técnicas como clustering, clustering, padronização e validação.
- Precisão de código aprimorada: Um aumento de 56% na precisão do trabalho de codificação foi alcançado usando geração de testes unitários e métodos de teste.
- Escalabilidade e Modularidade: O design modular da estrutura permite que ela se adapte facilmente a novas tarefas e configurações, tornando-a uma ferramenta robusta de desenvolvimento de LLM.

Concluindo, Archon aborda a necessidade crítica de um sistema automatizado que melhore os LLMs durante a tomada de decisões, integrando efetivamente várias estratégias. Esta pesquisa fornece uma solução prática para a complexidade da lógica de tempo de design das arquiteturas, tornando mais fácil para os desenvolvedores criarem sistemas LLM de alto desempenho adaptados para tarefas específicas. A estrutura Archon estabelece um novo padrão para o desenvolvimento de LLMs. Ele fornece uma abordagem sistemática e automatizada para pesquisas de propriedades em tempo real, demonstrando sua capacidade de alcançar resultados de alta qualidade em vários benchmarks.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – Conferência de recuperação de dados GenAI (promovida)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.

: uma árvore kd paralela que funciona bem tanto no conceito quanto na prática")
