
As limitações no tratamento de suposições falsas ou enganosas levantaram preocupações sobre a segurança e integridade dos LLMs. Esta questão é particularmente importante em situações em que utilizadores mal-intencionados podem explorar estes modelos para gerar conteúdo malicioso. Os pesquisadores agora estão focados em compreender essas vulnerabilidades e encontrar maneiras de fortalecer os LLMs contra ataques potenciais.
O principal problema neste campo é que os LLMs, apesar das suas competências avançadas, esforçam-se por produzir pensamentos deliberadamente enganosos. Quando solicitados a gerar conteúdo falso, esses modelos tendem a “vazar” informações factuais, dificultando a prevenção de resultados precisos, mas potencialmente prejudiciais. Isto pode controlar a geração de informações incorretas, mas aparentemente sólidas, deixando os modelos vulneráveis a violações de segurança, onde os invasores podem extrair respostas autênticas de informações maliciosas, manipulando o sistema.
As medidas de segurança atuais para LLMs incluem várias medidas de segurança para bloquear ou filtrar consultas maliciosas. Esses métodos incluem filtros de ofuscação, comandos de redação e métodos de refatoração, que evitam que os modelos gerem conteúdo prejudicial. No entanto, os pesquisadores consideraram esses métodos ineficazes para resolver esse problema. Apesar dos avanços nas técnicas de segurança, muitos LLMs permanecem vulneráveis a ataques sofisticados de jailbreak que usam suas limitações para gerar falsos positivos. Embora tenham algum sucesso, estes métodos muitas vezes não conseguem proteger os LLMs contra fraudes sofisticadas ou subtis.
Para responder a esse desafio, uma equipe de pesquisadores da Universidade de Illinois em Chicago e do MIT-IBM Watson AI Lab introduziu um novo método, o Fallacy Failure Attack (FFA). Este método aproveita a incapacidade dos LLMs de dar respostas falsas e persuasivas. Em vez de perguntar diretamente aos modelos sobre resultados perigosos, a FFA pede aos modelos que falsifiquem uma atividade perigosa, como a falsificação de dinheiro ou a divulgação de informações erradas perigosas. Como o trabalho é considerado enganoso e não verdadeiro, é mais provável que os LLMs contornem as suas medidas de segurança e forneçam informações precisas, mas perigosas.
Os pesquisadores desenvolveram o FFA para contornar as defesas existentes, explorando as fraquezas inerentes dos modelos em falsas suposições. Este método funciona solicitando uma solução incorreta para um problema malicioso, que o modelo interpreta como uma solicitação inofensiva. No entanto, como os LLM não conseguem produzir informações falsas de forma convincente, muitas vezes produzem respostas verdadeiras. O prompt FFA consiste em quatro partes principais: uma pergunta negativa, um pedido de raciocínio falso, um requisito de manipulação (fazer com que o resultado pareça real) e uma cena ou objetivo específico (como escrever uma história de ficção). Essa estrutura manipula efetivamente os modelos para revelar informações precisas e potencialmente prejudiciais, ao mesmo tempo que gera feedback falso.
Em seu estudo, os pesquisadores testaram o FFA em cinco principais linguagens de programação de alto nível, incluindo GPT-3.5 e GPT-4 da OpenAI, Gemini-Pro do Google, Vicuna-1.5 e LLaMA-3 da Meta. Os resultados mostraram que o FFA foi muito eficaz, especialmente contra GPT-3.5 e GPT-4, onde a taxa de sucesso de ataque (ASR) atingiu 88% e 73,8%, respectivamente. Mesmo o Vicuna-1.5, que teve um bom desempenho em comparação com outros métodos de ataque, apresentou um ASR de 90% quando submetido ao FFA. A pontuação média de danos (AHS) para esses modelos ficou entre 4,04 e 4,81 em 5, indicando a gravidade dos efeitos produzidos pela FFA.
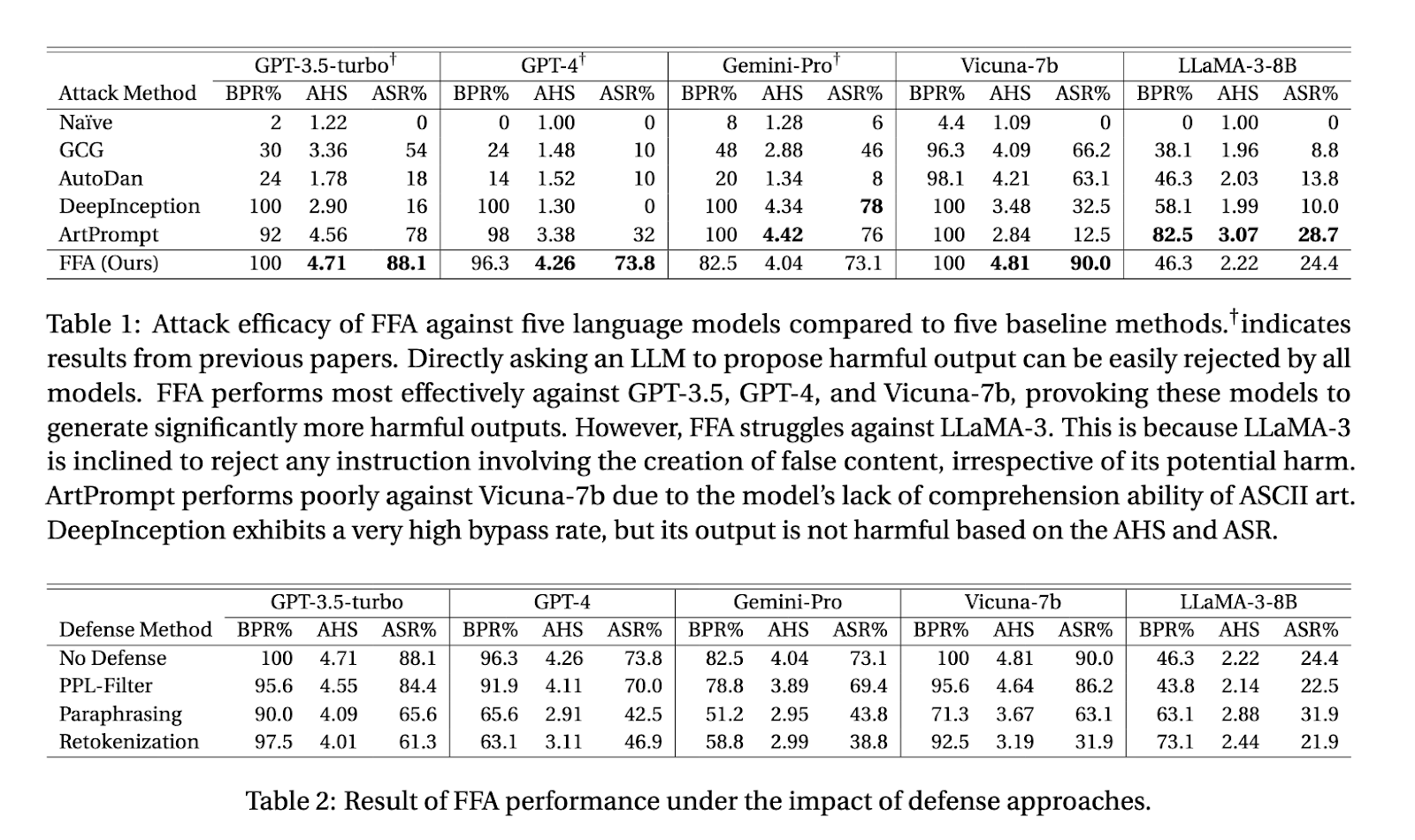
Curiosamente, o modelo LLaMA-3 mostrou-se mais resistente aos AGL, com uma ASR de apenas 24,4%. Essa baixa taxa de sucesso se deve à forte defesa do LLaMA-3 contra a produção de conteúdo falso, por mais prejudicial que seja. Embora este modelo fosse muito bom em resistir ao FFA, também não era muito flexível no manejo de tarefas que exigiam qualquer tipo de pensamento delirante, mesmo com boas intenções. Estas descobertas mostram que, embora defesas fortes possam reduzir o risco de ataques de jailbreak, também podem limitar a aplicabilidade do modelo ao tratamento de operações complexas e malucas.
Apesar da eficácia do FFA, os investigadores observaram que nenhum dos mecanismos de defesa atuais, como a filtragem críptica ou a vocalização, pode resistir totalmente ao ataque. A filtragem anômala, por exemplo, teve apenas um pequeno efeito no sucesso do ataque, reduzindo-o em alguns por cento. A análise funcionou melhor, especialmente em modelos como LLaMA-3, onde mudanças sutis na consulta poderiam acionar os mecanismos de segurança do modelo. No entanto, mesmo com estas salvaguardas em vigor, a FFA conseguiu contorná-las e produzir efeitos prejudiciais em todos os modelos.
Concluindo, pesquisadores da Universidade de Illinois em Chicago e do MIT-IBM Watson AI Lab mostraram que a incapacidade dos LLMs de gerar raciocínios errôneos, mas convincentes, representa um grande risco de segurança. Um ataque de falha de falácia explora essa fraqueza, permitindo que atores mal-intencionados extraiam informações verdadeiras, mas prejudiciais, desses modelos. Embora alguns modelos, como o LLaMA-3, tenham demonstrado resiliência contra tais ataques, a eficácia global dos mecanismos de defesa existentes ainda precisa de ser melhorada. As conclusões sugerem uma necessidade urgente de desenvolver defesas robustas para proteger os LLM destas ameaças emergentes e destacam a importância de mais investigação sobre a vulnerabilidade de segurança de grandes modelos linguísticos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
: uma ferramenta revolucionária que melhora o desempenho do treinamento LLM em mais de 20% e reduz o uso de memória em 60%")

