
Avanços recentes em Grandes Modelos de Linguagem (LLMs) remodelaram o cenário da inteligência artificial (IA), abrindo caminho para a criação de Modelos Multimodais de Grandes Linguagens (MLLMs). Esses modelos avançados estendem o poder da IA além do texto, permitindo a compreensão e o processamento de conteúdos como imagens, áudio e vídeo, representando um grande avanço no desenvolvimento da IA. Apesar do notável progresso dos MLLMs, as atuais soluções de código aberto apresentam muitas deficiências, especialmente nas capacidades de muitas coisas e na qualidade da experiência de interação do usuário. As impressionantes capacidades multimodais e a experiência prática de novos modelos de IA, como o GPT-4o, destacam o seu importante papel em aplicações práticas, mas exigem um parceiro eficiente de código aberto.
Os MLLMs de código aberto têm demonstrado um potencial crescente, com esforços tanto da academia como da indústria alimentando o rápido desenvolvimento de modelos. LLMs como LLaMA, MAP-Neo, Baichuan, Qwen e Mixtral são treinados em grandes quantidades de dados de texto, demonstrando fortes habilidades em processamento de linguagem natural e resolução de tarefas usando capacidade de geração de texto. Os modelos de linguagem de visão (VLMs) mostraram grande potencial no tratamento de problemas orientados à visão, com modelos incluindo LLaVA, DeepSeek-VL]a série Qwen-VL, as famílias InternVL e MiniCPM. Da mesma forma, os modelos de linguagem de áudio (ALMs) funcionam com dados de áudio e texto, usam dados de áudio para compreender sons e vozes e usam modelos como Qwen-Audio, SALMONN e SpeechGPT.
No entanto, os modelos de código aberto ainda estão atrás de modelos proprietários como o GPT-4o quando se trata de lidar com diferentes tipos de dados, como imagens, texto, etc., e muito poucos modelos de código aberto fazem isso bem. Para resolver este problema, os pesquisadores introduziram Baichuan-Omnium modelo de código aberto que pode lidar com dados como áudio, imagens, vídeos e texto de uma só vez.
Pesquisadores de Universidade Westlake de novo Universidade de Zhejiang lançou um LLM omnimodal Baichuan-Omni juntamente com um esquema de treinamento multimodal projetado para facilitar um melhor processamento multimodal e uma melhor interação do usuário. Também oferece suporte multilíngue para idiomas como inglês e chinês. A estrutura de treinamento inclui um pipeline abrangente que inclui geração de dados de treinamento omnimodal, pré-treinamento de alinhamento multimodal e planejamento supervisionado multimodal, com foco particular no desenvolvimento de habilidades instrucionais omnimodais. O modelo primeiro aprende a associar diferentes tipos de dados e recursos, como imagens com legendas, texto de documentos (OCR) e áudio semelhante a texto. Esta etapa ajuda o modelo a compreender e trabalhar com recursos visuais e sonoros. Em seguida, o modelo é treinado em mais de 200 tarefas para melhorar sua capacidade de seguir instruções detalhadas envolvendo diversos tipos de informações e dados.
O treinamento de modelo omnimodal usa diversos conjuntos de dados, incluindo texto, imagens, vídeos e áudio de fontes artificiais e de código aberto. Para imagens, são utilizados dados como legendas, OCR e gráficos, enquanto os dados de vídeo vêm de tarefas como classificação e detecção de movimento, com algumas legendas geradas pelo GPT-4. Os dados de áudio coletados de diferentes locais, sotaques e idiomas são processados por meio de reconhecimento de fala e testes de qualidade, refinando vários scripts para melhor precisão. Os dados textuais vêm de fontes como sites, blogs e livros, com foco na variedade e qualidade. Os dados intermodais incluem imagem, áudio e texto, usando tecnologia de conversão de texto em fala para melhorar a capacidade do modelo de compreender as interações entre diferentes tipos de dados. Um processo de pré-treinamento de alinhamento multimodal combina imagens, vídeos, áudio e linguagem para melhorar a compreensão do modelo. No ramo da linguística de imagens, um modelo é treinado em etapas para melhorar as operações de texto de imagem, como legendagem e resposta visual a perguntas (VQA). O ramo de linguagem de vídeo se baseia nisso combinando quadros de vídeo com texto, enquanto o ramo de linguagem de áudio usa técnicas avançadas para preservar informações de áudio ao mapeá-las para texto. Finalmente, “Alinhamento Omni”A plataforma integra dados de imagem, vídeo e áudio para aprendizagem multidimensional. O estudo também examina o desempenho de modelos avançados de IA projetados para processar diferentes tipos de mídia, com foco particular em Modelo Baichuan-Omni. Este modelo mostra capacidades incríveis em tarefas que vão desde Reconhecimento Automático de Fala (ASR) na compreensão de vídeo, supera outros modelos líderes em áreas como transcrição chinesa e tradução de fala para texto. Pesquisas mostram a importância de coisas como essas configuração do codificador virtual de novo contagem de quadros no processamento de vídeo, obtendo uma melhoria significativa ao usar resoluções dinâmicas. A fim de melhorar a diversidade dos modelos, os dados de treinamento foram expandidos para incluir mais tarefas, incluindo raciocínio matemático e interpretação de vídeo, etc.

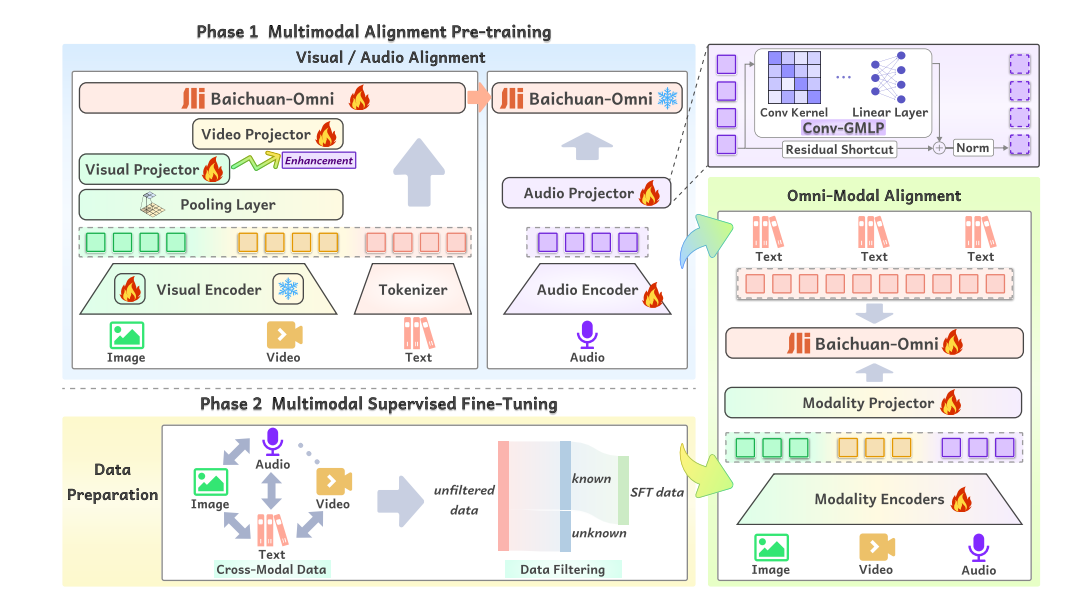
Como conclusão, o código aberto Baichuan-Omni é um passo em direção ao estabelecimento de um LLM verdadeiramente omnimodal que integra todos os sentidos humanos. Com pré-treinamento omnimodal e ajuste fino usando dados omnimodais de alta qualidade, esta versão do Baichuan-Omni atingiu os melhores níveis na integração de inteligência em vídeo, imagem, texto e áudio.
Apesar do seu desempenho promissor, ainda há espaço significativo para melhoria das competências básicas em cada método. Isso inclui melhorar os recursos de extração de texto, apoiar a compreensão de vídeos longos, desenvolver um sistema TTS de ponta a ponta integrado com LLMs e melhorar a capacidade de compreender não apenas vozes humanas, mas também sons naturais, como água corrente, cantos de pássaros e colisão. sons, entre outros. Mostrando um forte desempenho em vários benchmarks omnimodais e multimodais, este artigo pode servir como uma base competitiva para a comunidade de código aberto no desenvolvimento da compreensão multimodal e da interação em tempo real e como base para o desenvolvimento futuro!
Confira Papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


