
A inteligência de codificação cresceu rapidamente, impulsionada pelo desenvolvimento de modelos linguísticos em larga escala (LLMs). Esses modelos são cada vez mais usados para tarefas de programação automatizadas, como codificação, depuração e testes. Com habilidades que abrangem vários idiomas e domínios, os LLMs se tornaram ferramentas valiosas no avanço do desenvolvimento de software, ciência de dados e resolução de problemas computacionais. O surgimento dos LLMs está mudando a forma como as tarefas complexas de planejamento são abordadas e realizadas.
Uma importante área de desenvolvimento no cenário atual é a necessidade de benchmarks abrangentes que reflitam com precisão as demandas das aplicações do mundo real. Os conjuntos de dados de avaliação existentes, como HumanEval, MBPP e DS-1000, tendem a concentrar-se estritamente em domínios específicos, como algoritmos avançados ou aprendizagem automática, não conseguindo capturar a diversidade necessária num programa full-stack. Além disso, esses conjuntos de dados podem ser extensos para testar os recursos multilíngues e de extensão de domínio necessários para o desenvolvimento de software no mundo real. Esta lacuna representa um grande obstáculo para medir e melhorar com sucesso o desempenho do LLM.
Pesquisadores da ByteDance Seed e MAP lançaram o FullStack Bench, um benchmark que testa LLMs em 11 domínios de aplicação diferentes e suporta 16 linguagens de programação. O benchmark cobre análise de dados, desenvolvimento de desktop e web, aprendizado de máquina e multimídia. Além disso, desenvolveram o SandboxFusion, um espaço de trabalho integrado que automatiza a geração e testes de código em vários idiomas. Estas ferramentas visam fornecer uma estrutura abrangente para avaliar LLMs em situações do mundo real e superar as limitações dos benchmarks existentes.
O conjunto de dados FullStack Bench contém 3.374 problemas, cada um acompanhado por casos de teste de unidade, soluções de referência e categorias fáceis, médias e difíceis. Os problemas foram resolvidos usando uma combinação de experiência humana e processos assistidos por LLM, garantindo diversidade e qualidade no design das questões. SandboxFusion oferece suporte à solução de problemas do FullStack Bench, permitindo estações de trabalho seguras e isoladas que atendem às necessidades de diferentes linguagens de programação e dependências. Suportando 23 linguagens de programação, fornece uma solução simples e flexível para avaliar LLMs em conjuntos de dados além do FullStack Bench, incluindo benchmarks populares como HumanEval e MBPP.
Os pesquisadores realizaram testes extensivos para avaliar o desempenho de vários LLMs no FullStack Bench. Os resultados revelaram diferenças significativas no desempenho entre domínios e linguagens de programação. Por exemplo, embora alguns modelos tenham demonstrado fortes competências básicas de programação e análise de dados, outros precisam de ajuda com tarefas relacionadas com multimédia e tarefas relacionadas com o sistema operativo. Pass@1, a principal métrica de avaliação, varia entre domínios, destacando os desafios dos modelos na adaptação a tarefas de planeamento diversas e complexas. O SandboxFusion provou ser uma ferramenta de teste robusta e eficiente, superando as estações de trabalho existentes no suporte a uma variedade de linguagens de programação e dependências.
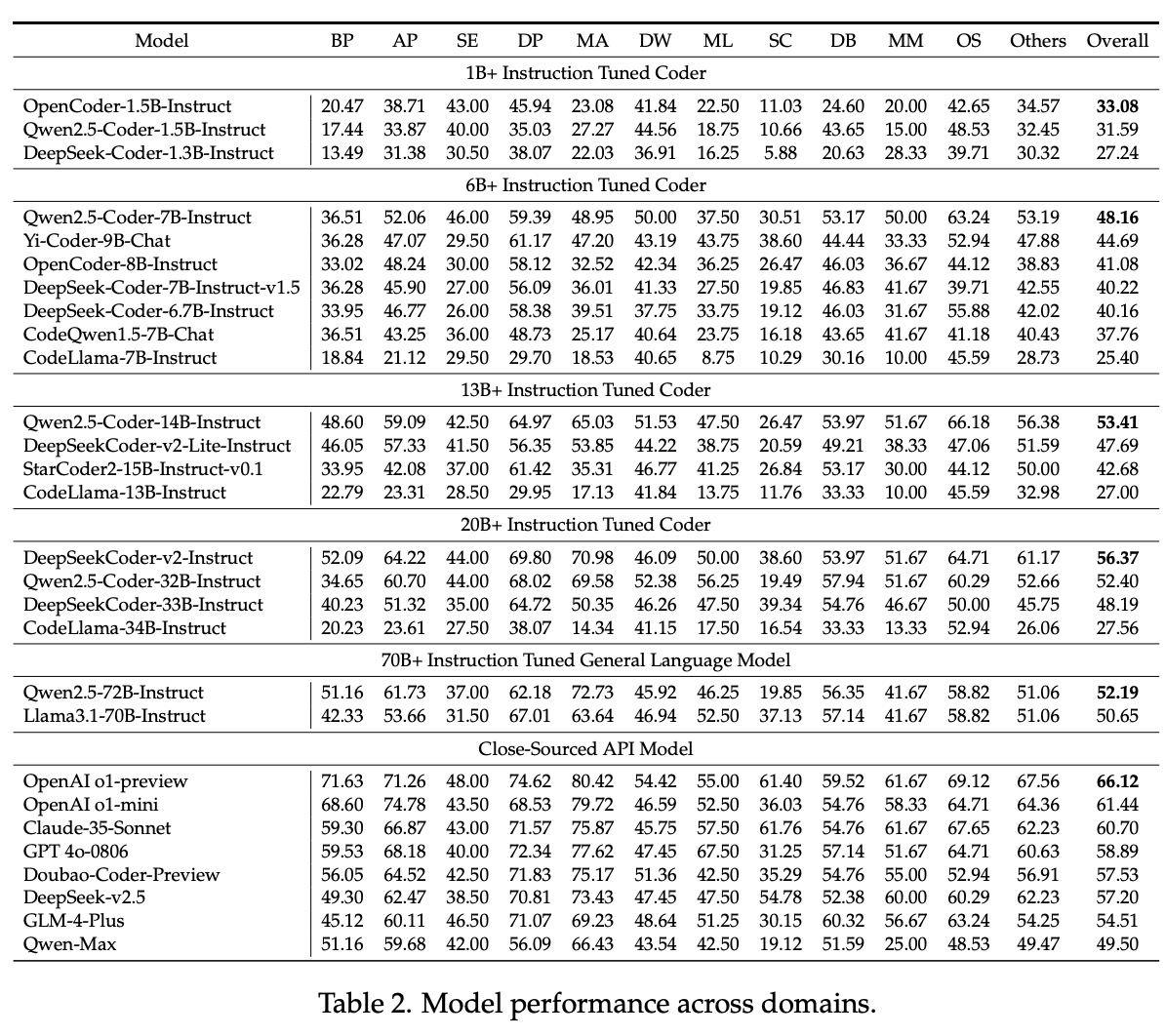
As leis de escalonamento também foram analisadas, mostrando que o aumento dos parâmetros geralmente melhora o desempenho dos modelos. Porém, os pesquisadores observaram uma diminuição no desempenho de alguns modelos em escalas superiores. Por exemplo, a série Qwen2.5-Coder atingiu o pico nos parâmetros 14B, mas mostrou uma queda no desempenho em 32B e 72B. Estas descobertas enfatizam a importância de medir o tamanho e a eficiência do modelo para melhorar o desempenho do LLM. Os pesquisadores observaram uma correlação positiva entre as taxas de aprovação na codificação e as taxas de sucesso nos testes, enfatizando a necessidade de uma codificação precisa e livre de erros.
FullStack Bench e SandboxFusion juntos representam um avanço significativo nos testes LLM. Ao abordar as limitações dos benchmarks existentes, estas ferramentas permitem uma avaliação mais abrangente das competências LLM em todos os domínios e linguagens de programação. Esta pesquisa estabelece as bases para a inovação em inteligência de código e enfatiza a importância do desenvolvimento de ferramentas que reflitam com precisão os cenários de programação do mundo real.
Confira eu Papel, Banco FullStack, de novo SandboxFusion. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 [Must Attend Webinar]: 'Transforme provas de conceito em aplicativos e agentes de IA prontos para produção' (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🚨🚨 WEBINAR DE IA GRATUITO: 'Acelere suas aplicações LLM com deepset e Haystack' (promovido)


