: AI Frame de melhoria da consulta LLM")
Grandes modelos de linguagem (LLMS) se convertem em inteligência artificial, mostrando habilidades notáveis na solução de texto e resolvendo problemas. No entanto, o limite crítico insiste em seu padrão “Pensamento rápido” Conseqüências produtivas da abordagem com base em uma pergunta sem o seu refinamento. Embora apenas o mais recente “Pensar um pouco” Os métodos como a cadeia de expressão promovem problemas em pequenos passos, são sempre pressionados com as primeiras informações sólidas e não podem montar essas novas informações durante a consulta. Essa lacuna é chamada de tarefas complexas que exigem a revisão de informações revisadas, como responder à pergunta multi-hop ou geração agradável.
As maneiras atuais de melhorar a consulta do LLM se enquadram em duas categorias. Geração de pano Sistemas de pré-carregamento, mas geralmente introduzem informações inadequadas que interferem na eficiência e precisão. Algoritmos suportados são baseados em árvores como Pesquisa de árvore de Monte Carlo (MCTS) Habilite a avaliação formal de formas de consultoria, mas sem métodos de integração do conteúdo. Por exemplo, quando os lats são medidos medindo medições para visualizar o intervalo, a conformidade contextual e o funcionamento computacional – geralmente produzem respostas muito amplas ou informais.
Neste artigo, os pesquisadores de uma equipe de segurança digital, Qhohoo 360 propostos Cadeia de associação-pensamentos (casaco) Uma estrutura para abordar essa restrição usando novos problemas. Primeiro, Método de memória de combinação Permite a integração de informações poderosas durante a consulta, imitando o entendimento humano. Diferentemente dos métodos estáticos do RAG para o conhecimento avançado, o preservativo usa informações de informações, respondendo a algumas medidas de raciocínio – iguais às memórias de matemática das necessidades. Segundo, Algoritmo MCTS preparado Inclui esse processo de se associar ao circuito da história no palco da seção quatro: opções, expansão do Oficial de Informações, Exame de Qualidade e Backpropagros de Valor. Isso cria um loop de feedback quando cada etapa de consultoria pode resultar em atualizações de informações, conforme mostrado na Figura 4 da implementação real.
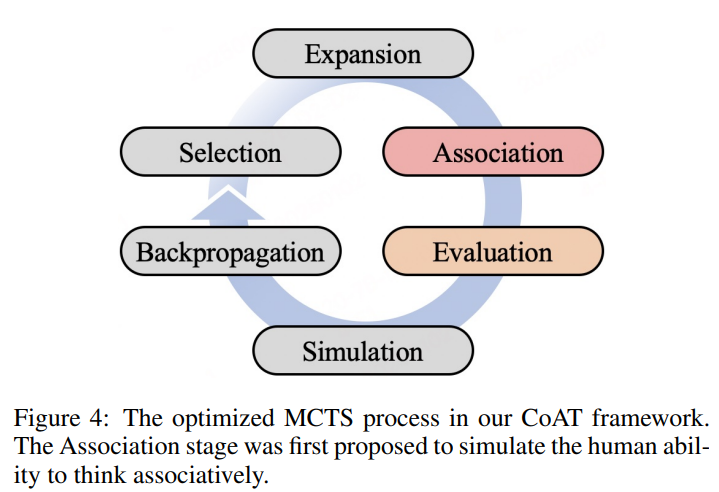
O casaco do casaco é a construção de dois pensamentos. Ao processar uma pergunta, o programa, ao mesmo tempo, examina os métodos de pensamento em potencial através da árvore MCTS, mantendo o banco de memória. Cada local na árvore de pesquisa (representando a etapa de consulta) produz o conteúdo (G (n))Informações relacionadas (Am (n)) incluindo
Alocação de pontos de qualidade de resposta (FImagensSelecionado e para cumprir com as informações (FumSelecionadopor β para controlar seu valor relacionado. Isso garante que as organizações permaneçam fortemente integradas ao processo de reforma, em vez de produzir informações tangenciais.
O casaco do casaco destaca sua altura nas estratégias de consulta existentes. A estrutura foi considerada considerada métrica qualificada e métricas de acessórios. O teste certo foi envolvido com as respostas a perguntas complexas, onde o casaco mostrou respostas ricas e respostas completas em comparação com modelos básicos como o PASS2.5-32B e o ChatGPT. Significativamente, ele apresenta alguns dos estágios da consulta, como moral e controle, que não estavam em outros modelos. O teste de valor é realizado em duas ações principais: a pergunta com os entrevistados e os membros da codificação. Com atividades de generagem (RAG) de Retreeval-Germented (RAG) em comparação com o conjunto de dados de Natirag, Ircot, Hipporag, Latis e 2Wimultimop. Métricas como o jogo exato (EM) e as pontuações de F1 verificadas pela F1, o que indica suas respostas específicas e inadequadas de produção de energia. Na produção de código, os modelos ativados de atividade actinada por revestimento prontos para o contador de Tur-Tuned (Qwen2.5-Coder-7b-7b) em Daterete, MBPP e HUMEval-X, enfatiza a consistência com suas circunstâncias.
Este trabalho estabelece um novo paradigma LLM para consultar integrando uma poderosa organização de informações com uma pesquisa formal. Diferentemente das formas anteriores de augustiação da augustiação, o Revio Monorial Geral permite que o pensamento – reconheça o pensamento que concorda com os requisitos das informações que aparecem. A renovação tecnológica no funcionamento dos MCTs e nos dois testes de conteúdo fornece o plano para integrar programas externos para programas LLM exportados. Enquanto as visões atuais dependem do cérebro padrão externo, a construção da construção está apoiando a integração integrada de equipamentos plug-and-play e emergentes, como agentes LLM e a pesquisa na web em tempo real. Essas melhorias sugerem que a seguinte limitação no raciocínio da IA pode não ser inserida em programas poderosos de acordo com as informações da exportação de destino – como os especialistas que se consultam com questões difíceis.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Plataforma de IA de código aberto recomendado: 'Interestagente Sistema de código aberto com várias fontes para testar o sistema de IA difícil (promovido)
Weneet Kumar é estudante de um consultor em Marktechpost. Atualmente, ele perseguiu seu BS do Instituto Indiano de Tecnologia (IIT), Kanpur. Ele é um entusiasmo de aprendizado de máquina. Ela é apaixonada pela pesquisa recente e raiva na aprendizagem mais profunda, na ideia de computador e nos campos relacionados.
✅ [Recommended] Junte -se ao nosso canal de telégrafo

")
