: melhora a geração de áudio em tempo real")
Modelos autorregressivos são usados para gerar sequências de tokens diferentes. O próximo token possui o status dos tokens anteriores na ordem indicada no caminho. Estudos recentes mostraram que a geração automática de sequências de incorporação contínua também é possível. No entanto, os Modelos Autoregressivos Contínuos (CAMs) geram esses embeddings na mesma sequência, mas enfrentam desafios como uma diminuição na qualidade da saída em sequências estendidas. Essa redução ocorre devido ao acúmulo de erros durante o processo de predição, onde pequenos erros de predição se somam à medida que o comprimento da sequência aumenta, resultando em saída degradada.
Os modelos automáticos tradicionais de imagem e áudio dependem da segmentação dos dados em tokens usando VQ-VAEs para que os modelos operem dentro do espaço de probabilidades discretas. Tal abordagem apresenta desvantagens significativas, incluindo perdas adicionais no treinamento de VAEs e complexidade adicional. Embora a incorporação contínua seja mais eficiente, ela tende a acumular erros durante a inferência, causando mudanças na distribuição e reduzindo a qualidade do resultado gerado. Tentativas recentes de calibração cruzada com treinamento de incorporação contínua não conseguiram produzir resultados satisfatórios devido aos difíceis métodos de mascaramento não linear e métodos de programação que dificultam a eficiência e limitam o uso contínuo na comunidade de pesquisa.
Para resolver isso, um grupo de pesquisadores da Queen Mary University e do Sony Computer Science Laboratories conduziu um estudo detalhado e propôs um método para combater o acúmulo de erros e treinar modelos automáticos na sequência ordenada de incorporação contínua sem adicionar complexidade. Para superar as limitações dos AMs convencionais, o CAM introduziu uma estratégia de amplificação de ruído durante o treinamento para simular os erros que ocorrem durante a previsão. Este método combinou potência de Fluxo Retificado (RF) e AMs com incorporação contínua.
A ideia principal por trás do CAM proposto era injetar ruído sequencialmente durante o treinamento para simular cenários de detecção de erros. Em seguida, usou uma distribuição iterativa para gerar sequências automaticamente, melhorando continuamente as previsões enquanto corrigia erros. O CAM foi pré-treinado para ser robusto ao acúmulo de erros durante a execução de sequências longas por treinamento de sequências ruidosas. Esta técnica melhorou a qualidade geral das sequências geradas, especialmente para tarefas como a produção musical, onde a qualidade de cada elemento previsto provou ser importante para o resultado geral.
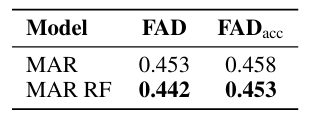
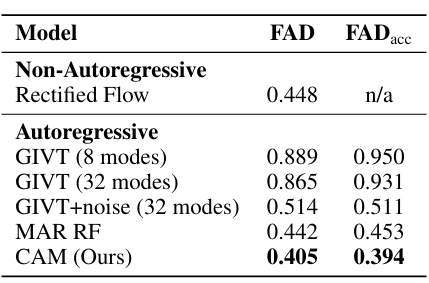
O método foi testado em um conjunto de dados musicais e comparado com bases de testes automatizadas e não automatizadas. Os pesquisadores usaram um conjunto de dados de quase 20.000 gravações de um único instrumento com som estéreo de 48 kHz para treinamento e teste. Eles processaram os dados com Music2Latent para criar uma incorporação latente contínua a uma taxa de amostragem de 12 Hz. Baseado em um transformador com 16 camadas e 150 milhões de parâmetros, o CAM foi treinado utilizando AdamW para 400k iterações. O CAM teve melhor desempenho que outros modelos, com FAD de 0,405 e FADacc de 0,394, em comparação com bases como GIVT ou MAR. O CAM forneceu bases de melhor qualidade para reconstruir o espectro sonoro e evitar o acúmulo de erros de sequência longa; o método de amplificação de ruído também ajudou a melhorar o escore GIVT.
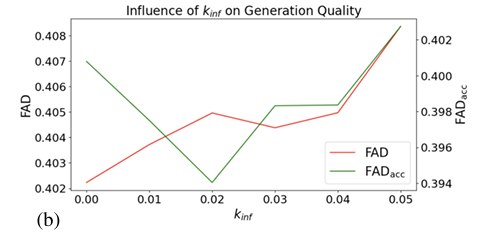
Em resumo, o método proposto treina modelos independentes em incorporação contínua que aborda diretamente o problema de acumulação de erros. Uma estratégia de injeção de ruído cuidadosamente calibrada durante a previsão também minimiza o acúmulo de erros. Esta abordagem abre caminho para aplicações de áudio interativas e em tempo real que se beneficiam da eficiência e da natureza linear dos modelos automatizados e podem ser usadas como base para pesquisas futuras no domínio!
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 [Must Attend Webinar]: 'Transforme provas de conceito em aplicativos e agentes de IA prontos para produção' (Promovido)
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🚨🚨 WEBINAR DE IA GRATUITO: 'Acelere suas aplicações LLM com deepset e Haystack' (promovido)


