")
Os Modelos Multimodais de Grandes Linguagens (MLLMs) fizeram progressos significativos em várias aplicações usando o poder dos modelos Transformer e seus mecanismos de atenção. No entanto, estes modelos enfrentam o desafio significativo de preconceitos inerentes aos seus parâmetros iniciais, conhecidos como modalidades anteriores, que podem impactar negativamente a qualidade da produção. O mecanismo de atenção, que determina como a informação de entrada é medida para produzir resultados, é particularmente propenso a este viés. Tanto a atenção do codificador visual quanto a atenção do backbone do Large Language Model (LLM) são afetadas por fatores críticos, que podem levar a problemas como detecção ilegal e degradação do desempenho do modelo. Os pesquisadores se concentraram em abordar esse viés sem alterar os pesos do modelo.
Avanços recentes em MLLMs levaram ao desenvolvimento de modelos sofisticados, como VITA e Cambrian-1, que podem processar vários métodos e alcançar funcionalidades de última geração. A pesquisa também se concentrou no desenvolvimento de plataformas de inferência não treinadas, como VCD e OPERA, que utilizam o conhecimento humano para melhorar o desempenho do modelo sem treinamento adicional. Os esforços para resolver questões processuais incluíram maneiras de superar problemas linguísticos, integrando módulos virtuais e desenvolvendo benchmarks como o VLind-Bench para medir problemas linguísticos em MLLMs. A importância percebida foi abordada através do aproveitamento de LLMs disponíveis no mercado para apoiar entradas e resultados multimodais com técnicas de formação rentáveis.
Pesquisadores da Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou), da Universidade de Ciência e Tecnologia de Hong Kong, da Universidade Tecnológica de Nanyang e da Universidade de Tsinghua propuseram CAUSALMM, uma estrutura causal projetada para enfrentar os desafios colocados pelas prioridades nos MLLMs. Este método constrói um modelo estrutural causal de MLLMs e utiliza métodos de intervenção e métodos de raciocínio contrafactual sob o paradigma de correção backdoor. Isto permite que o método proposto capte melhor o efeito causal da atenção activa no resultado do MLLM, mesmo na presença de factores de confusão, tais como prioridades críticas. Também garante que o resultado do modelo corresponda melhor ao input multimodal e minimiza os efeitos negativos das prioridades modais no desempenho.
O desempenho do CAUSALMM é avaliado usando os benchmarks VLind-Bench, POPE e MME. A estrutura é testada em MLLMs básicos, como LLaVa-1.5 e Qwen2-VL, bem como em técnicas não treinadas, como Visual Contrastive Decoding (VCD) e Over-trust Penalty and Retrospection-Allocation (OPERA). O VCD reduz a manipulação de objetos, enquanto o OPERA introduz uma penalidade de tempo durante a busca de feixe e inclui uma estratégia de seleção reversa de token. Além disso, a análise inclui estudos transversais de falsa atenção e uma série de camadas de intervenção, fornecendo uma análise detalhada do desempenho da CAUSALMM em diferentes condições e configurações.
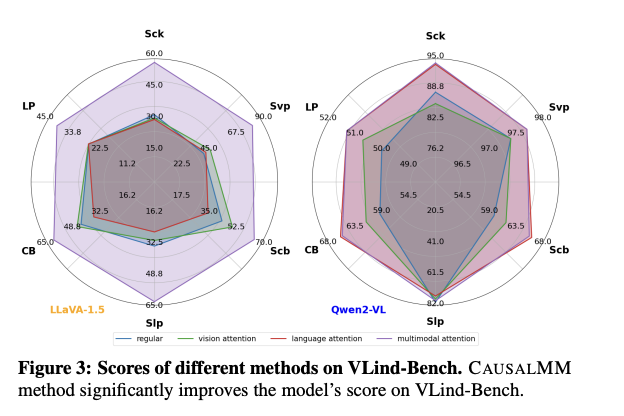
Os resultados dos testes em vários benchmarks demonstram a eficácia do CAUSALMM na estimativa de prioridades comportamentais e na redução de falsos positivos. No VLind-Bench, ele alcança melhorias significativas de desempenho para os modelos LLaVA1.5 e Qwen2-VL, equilibrando com sucesso recursos visuais e linguísticos. Nos testes de benchmark POPE, CAUSALMM superou as estruturas existentes na redução de falsos positivos em nível de item em configurações aleatórias, populares e conflitantes, com uma melhoria média de métrica de 5,37%. Os resultados do benchmark MME mostraram que o método proposto melhorou significativamente o desempenho dos modelos LLaVA-1.5 e Qwen2-VL, especialmente no tratamento de consultas complexas, como computação.
Em conclusão, os investigadores introduziram o CAUSALMM para enfrentar os desafios enfrentados pelas prioridades do MLLM. Ao tratar os factores processuais como factores de confusão e utilizar um modelo causal estrutural, CAUSALMM reduz eficazmente o preconceito de factores visuais e linguísticos. O uso de processamento backdoor e raciocínio contrafactual pela estrutura nos níveis de atenção visual e linguística mostrou uma redução nos preconceitos pré-linguísticos em vários benchmarks. Esta abordagem inovadora não só melhora o alinhamento de múltiplos insumos, mas também estabelece as bases para uma inteligência multimodal mais confiável, marcando uma direção promissora para futuras pesquisas e desenvolvimento no campo dos MLLMs.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – Conferência de recuperação de dados GenAI (promovida)

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.


