
Os modelos linguísticos de grande escala (LLMs) revolucionaram o cenário do processamento de linguagem natural, tornando-se ferramentas essenciais em setores como saúde, educação e tecnologia. Esses modelos executam tarefas complexas, incluindo interpretação de linguagem, análise de sentimento e geração de código. No entanto, o seu crescimento exponencial em escala e adoção apresentou desafios computacionais significativos. Cada tarefa geralmente requer versões ajustadas desses modelos, resultando em altos requisitos de memória e energia. Gerenciar adequadamente o processo de direcionamento em áreas com questões semelhantes para trabalhos diferentes é importante para manter seu uso em sistemas de produção.
Clusters conceituais que funcionam para LLMs abordam problemas importantes de variabilidade de tarefas e ineficiências de memória. Os sistemas atuais apresentam alta latência devido ao carregamento frequente do adaptador e às ineficiências de agendamento. Métodos de otimização baseados em adaptação, como Adaptação de baixo nível (LoRA), permitem que os modelos executem tarefas específicas ajustando pequenos subconjuntos dos parâmetros do modelo subjacente. Embora o LoRA reduza significativamente os requisitos de memória, ele apresenta novos desafios. Isso inclui maior contenção na largura de banda da memória durante o carregamento do adaptador e atrasos no bloqueio do cabeçalho da fila quando solicitações de complexidade variável são processadas sequencialmente. Essa ineficiência limita a escalabilidade e a capacidade de resposta dos clusters de virtualização sob carga pesada.
As soluções existentes tentam enfrentar estes desafios, mas precisam de atingir pontos críticos. Por exemplo, métodos como S-LoRA armazenam parâmetros do modelo na memória da GPU e adaptadores carregáveis são mais exigentes na memória do host. Essa abordagem leva a penalidades de desempenho devido aos tempos de download do adaptador, especialmente em situações de alta carga, onde a largura de banda do link PCIe se torna um gargalo. Políticas de agendamento como FIFO (First-In, First-Out) e SJF (Shortest-Job-First) foram testadas para lidar com tamanhos variados de solicitações, mas ambos os métodos falham sob carga excessiva. O FIFO tende a causar gargalos para solicitações pequenas, enquanto o SJF leva a gargalos para solicitações longas, resultando na perda de objetivos de nível de serviço (SLOs).
Pesquisadores da Universidade de Illinois Urbana-Champaign e IBM Research apresentaram Um camaleãoum novo programa de inferência LLM projetado para desenvolver ambientes multiadaptadores específicos para tarefas. Chameleon combina cache dinâmico e um mecanismo de programação sofisticado para minimizar ineficiências. Ele usa a memória da GPU com mais eficiência, armazenando em cache os adaptadores usados com frequência, reduzindo assim o tempo necessário para carregar um adaptador. Além disso, o sistema usa uma política de enfileiramento multinível que prioriza trabalhos com base nos requisitos de recursos e no tempo de execução.
Chameleon usa memória GPU inativa para armazenar em cache adaptadores populares, ajustando dinamicamente o tamanho do cache com base na carga do sistema. Esse cache dinâmico elimina a necessidade de transferências frequentes de dados entre CPU e GPU, reduzindo bastante a contenção no link PCIe. O método de agendamento divide as solicitações em filas com base no tamanho e aloca recursos igualmente, garantindo que nenhum trabalho fique sem trabalho. Essa abordagem permite tamanhos variados de trabalhos e evita que solicitações pequenas bloqueiem solicitações grandes. O agendador reequilibra as prioridades e cotas das filas, melhorando o desempenho sob diversas cargas de trabalho.
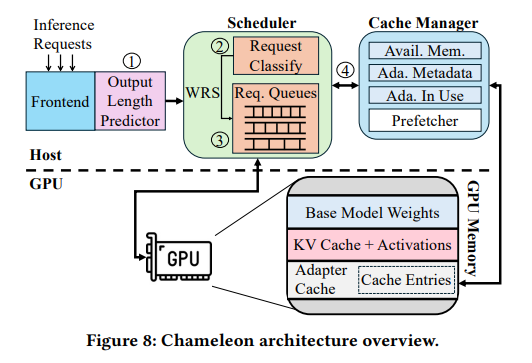
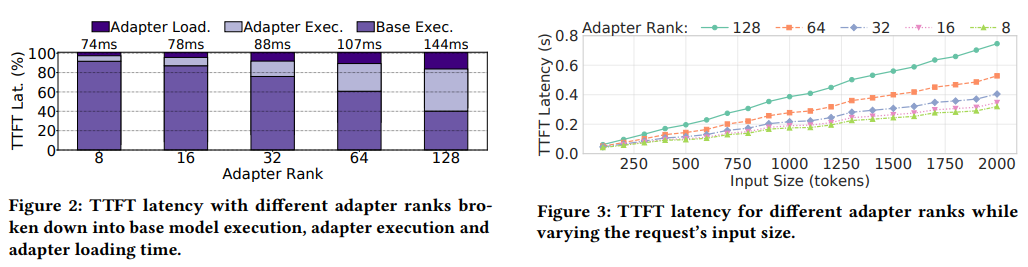
O sistema foi testado usando uma carga de produção real com LLMs de código aberto, incluindo o modelo Llama-7B. Os resultados mostram que o Chameleon reduz a latência do P99 time-to-first-token (TTFT) em 80,7% e a latência do P50 TTFT em 48,1%, sistemas básicos que funcionam tão bem quanto o S-LoRA. O desempenho foi melhorado 1,5 vezes, permitindo que o sistema lide com volumes de solicitações maiores sem violar SLOs. Notavelmente, o Chameleon demonstrou robustez, lidando com sucesso com níveis de adaptador de 8 a 128 e minimizando o impacto de latência de adaptadores maiores.
Principais conclusões do estudo:
- Benefícios Funcionais: O Chameleon reduziu a latência da cauda (P99 TTFT) em 80,7% e a latência mediana (P50 TTFT) em 48,1%, melhorando significativamente os tempos de resposta sob carga pesada.
- Instalação avançada: O sistema alcançou 1,5x mais desempenho que os métodos básicos, permitindo múltiplas solicitações ao mesmo tempo.
- Gerenciamento poderoso de recursos: O cache dinâmico aproveita efetivamente a memória ociosa da GPU, alterando dinamicamente o tamanho do cache com base na demanda do sistema para minimizar recarregamentos do adaptador.
- Nova edição: Um agendador de filas multinível eliminou gargalos e garantiu a alocação eficiente de recursos, evitando a privação de grandes solicitações.
- Escalabilidade: O Chameleon suporta com sucesso níveis de adaptador de 8 a 128, o que mostra sua adequação para uma variedade de tarefas complexas em configurações de vários adaptadores.
- Implicações amplas: Este estudo dá o exemplo para projetar um pensamento sistêmico que equilibre eficiência e medição, para enfrentar os desafios de produtividade do mundo real no fornecimento de grandes LLMs.

Concluindo, Chameleon apresenta uma melhoria significativa na interpretação do LLM em ambientes multi-adaptadores. O uso de cache dinâmico e um agendador de filas não otimizado de alto nível otimiza o uso de memória e o agendamento de tarefas. O sistema lida de forma eficaz com o carregamento do adaptador e com os problemas de tratamento de diversas solicitações, trazendo melhorias significativas de desempenho.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


 para resposta a consultas de contexto longo aprimorada com modelos de linguagem grande (LLMs)")