: uma nova abordagem de aprendizado de máquina para compreender o desenvolvimento de cabeças de atenção em transformadores")
A inteligência artificial (IA) e o aprendizado de máquina (ML) giram em torno da construção de modelos que podem aprender com os dados para executar tarefas como processamento de linguagem, reconhecimento de imagens e fazer previsões. Um aspecto importante da pesquisa em IA concentra-se nas redes neurais, especialmente nos transformadores. Esses modelos usam mecanismos de atenção para processar sequências de dados com mais eficiência. Ao permitir que o modelo se concentre nas partes mais relevantes dos dados, os transformadores podem executar tarefas complexas que exigem compreensão e previsão em diversos domínios.
Um grande problema no desenvolvimento de modelos de IA é compreender como os componentes internos, como os chefes de atenção nos transformadores, mudam e funcionam especificamente durante o treinamento. Embora o desempenho global destes modelos tenha melhorado, os investigadores ainda lutam para compreender como os diferentes componentes contribuem para o desempenho do modelo. Refinar um modelo comportamental ou melhorar a interpretação continua a ser difícil sem informações detalhadas sobre estes processos, conduzindo a desafios na melhoria da eficiência e transparência do modelo. Isto retarda o progresso no desenvolvimento do modelo e dificulta a capacidade de explicar como as decisões são tomadas.
Várias ferramentas foram desenvolvidas para estudar como funcionam as redes neurais. Isso inclui técnicas como estudos de exclusão, onde partes de um modelo específico são desabilitadas para ver sua função, e algoritmos de agrupamento, que combinam partes semelhantes com base em seu comportamento. Embora esses métodos tenham mostrado que os cabeçotes de atenção são particularmente eficazes em tarefas de previsão de tokens e processamento de sintaxe, eles geralmente fornecem resumos estáticos do modelo no final do treinamento. Tais abordagens requerem uma compreensão de como as estruturas internas dos modelos mudam dinamicamente ao longo do processo de aprendizagem. Eles não conseguem acomodar mudanças graduais à medida que esses modelos evoluem de funções básicas para funções complexas.
Pesquisadores da Universidade de Melbourne e do Timeus introduziram o Coeficiente de Aprendizagem Local Refinado (rLLC). Esta nova abordagem fornece uma medida quantitativa da complexidade do modelo, analisando o desenvolvimento de componentes internos, como cabeças de atenção. Ao focar em LLCs refinados, os pesquisadores fornecem uma compreensão detalhada de como os diferentes componentes dos transformadores funcionam e se degradam ao longo do tempo. Seu método permite monitorar a evolução das cabeças de atenção ao longo do processo de treinamento, proporcionando uma compreensão clara do seu desempenho. Esta metodologia ajuda a acompanhar a divisão progressiva dos chefes de atenção, mostrando como eles passam do mesmo estado no início do treinamento para diferentes funções à medida que a aprendizagem avança.
rLLC examina como os chefes de atenção respondem às estruturas de dados e à geometria do cenário de perdas. Durante o treinamento, as redes neurais ajustam seus pesos com base em quão bem minimizam os erros de previsão (perdas). O rLLC captura esse ajuste medindo o desempenho de diferentes cabeçotes com base em suas interações com estruturas de dados específicas, como bigramas ou padrões complexos, como indução ou parênteses correspondentes. Os pesquisadores usaram um transformador com apenas duas camadas em seus experimentos, focando na aparência das cabeças nessas camadas. No início do treinamento, observou-se que os chefes de atenção lidavam com tarefas simples, como processar tokens individuais ou pequenos grupos de palavras (bigramas). À medida que o treinamento avança, os chefes são divididos em funções especializadas, concentrando-se em tarefas complexas, como o manuseio de multigramas, que envolvem a previsão de sequências de tokens que não necessariamente se sobrepõem.
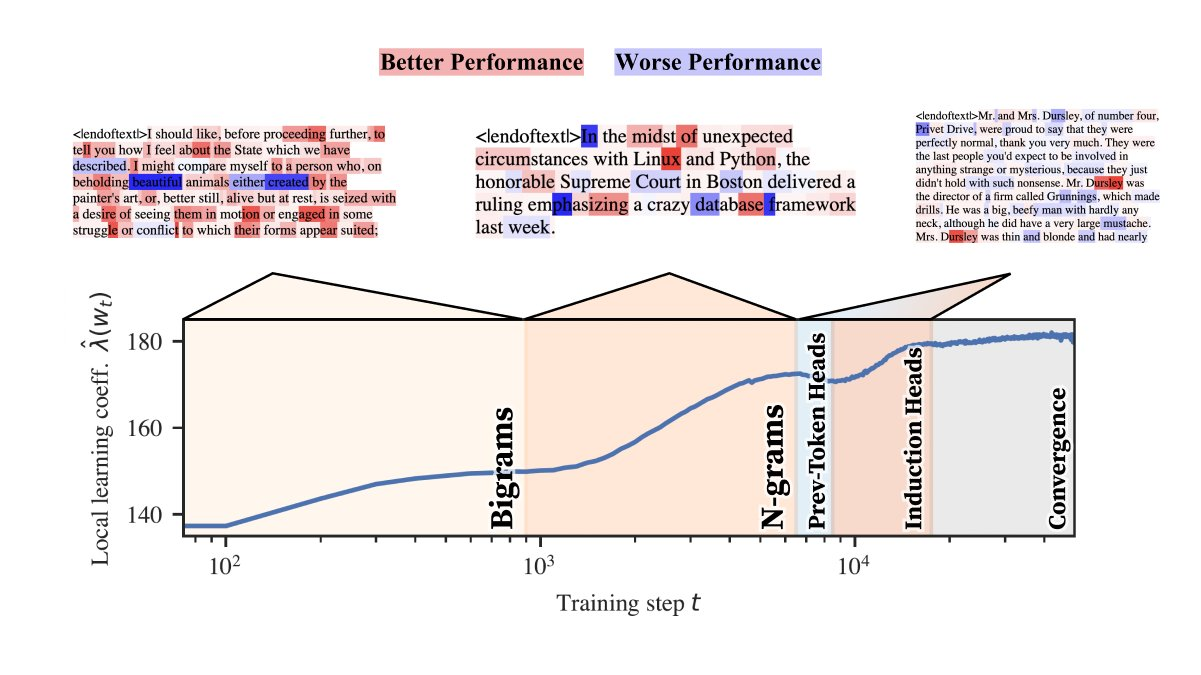
O estudo revelou várias descobertas importantes. Primeiro, os chefes de atenção são especializados em diferentes categorias. Durante os estágios iniciais do treinamento, os cérebros aprendem a processar estruturas de dados simples, como bigramas. Com o tempo, alguns cabeçotes fizeram a transição para tarefas mais complexas, como lidar com pular n-gramas (multigramas), sequências que consistem em muitos tokens com espaços. A pesquisa descobriu que certas cabeças, denominadas cabeças de indução, desempenham um papel importante no reconhecimento de padrões recorrentes, como aqueles observados em tarefas de processamento de código e linguagem natural. Essas cabeças contribuíram para a capacidade do modelo de prever com sucesso estruturas sintáticas repetidas. Seguindo o rLLC ao longo do tempo, os pesquisadores podem ver os estágios dessa mudança. Por exemplo, o desenvolvimento de circuitos de predição de multigramas foi identificado como um componente chave, com cabeças da camada 1 no modelo do transformador mostrando treinamento adicional no final do processo de treinamento.
Além de revelar as cabeças de atenção especial, o estudo descobriu um circuito multigrama até então desconhecido. Este circuito é importante para gerenciar sequências de tokens complexos e envolve interação entre diferentes cabeças de atenção, especialmente na camada 1. O circuito multigrama mostra que diferentes cabeças, originalmente encarregadas de processar sequências simples, evoluíram para lidar com padrões complexos por meio de sua integração. O estudo também destacou que mentes com valores baixos de LLC tendem a confiar em algoritmos simples, como indução, enquanto aquelas com valores altos memorizam padrões mais complexos. LLCs refinados permitem identificar funções funcionais sem depender de interpretação manual ou métodos de implementação, tornando o processo mais eficiente e escalável.
Em suma, este estudo contribui muito para a compreensão do processo de desenvolvimento de transformadores. Ao introduzir o LLC refinado, os pesquisadores fornecem uma ferramenta poderosa para analisar como diferentes partes da rede neural funcionam especificamente ao longo do processo de aprendizagem. Esta abordagem de desenvolvimento interpretativo preenche a lacuna entre a compreensão das estruturas de distribuição de dados, modelagem geométrica, capacidades de aprendizagem e experiência computacional. As descobertas abrem caminho para uma melhor interpretação dos modelos de transformadores, proporcionando novas oportunidades para melhorar seu design e eficiência para aplicações do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
: novo modelo MoE baseado em transformador de código aberto com total de 389 bilhões de parâmetros e 52 milhões de parâmetros funcionais")

