
Os modelos de distribuição de produção revolucionaram a produção de fotos e vídeos, tornando-se a base de software de produção de alta qualidade. Embora esses modelos tenham um desempenho muito bom no tratamento de distribuições complexas de dados de grandes dimensões, eles enfrentam um sério desafio: o risco de treinamento completo do head set em situações de poucos dados. Esta capacidade de lembrar levanta questões legais, tais como leis de direitos de autor, uma vez que estes modelos podem reproduzir cópias exactas dos dados de formação em vez de gerar novos conteúdos. O desafio está em entender quando esses modelos realmente generalizam quando são memorizados, principalmente considerando que imagens naturais muitas vezes têm sua variância limitada a uma pequena área de possíveis valores de pixels.
Esforços de pesquisa recentes examinaram vários aspectos do comportamento e dos modelos de distribuição. Métodos de medição de Dimensionalidade Intrínseca Local (LID) são desenvolvidos para entender como esses modelos aprendem múltiplas estruturas de dados, com foco na análise das características dimensionais de pontos de dados individuais. Outros métodos examinam como a normalidade evolui com base no tamanho do conjunto de dados e na variação de várias dimensões ao longo dos caminhos de distribuição. Além disso, métodos de física estatística são usados para analisar o processo de regressão de modelos de distribuição, à medida que a transformação de fase e a análise de lacuna espectral são usadas para estudar os processos reprodutivos. No entanto, estas abordagens podem focar-se em pontos específicos ou não conseguirem explicar a interação entre recordação e generalização em modelos distributivos.
Pesquisadores da Universidade de Bocconi, OnePlanet Research Center Donders Institute, RPI, JADS Tilburg University, IBM Research e Radboud University Donders Institute estenderam a teoria da cabeça de transmissão gerada para mais baseada em dados usando técnicas de física matemática. O seu estudo revelou um fenómeno inesperado onde subáreas distintas são mais comuns nos resultados principais sob certas condições, levando a uma redução nas dimensões selecionadas onde as principais características dos dados são preservadas sem colapsarem totalmente em áreas de formação individuais. A teoria apresenta uma nova compreensão de como diferentes subáreas da tangente são afetadas pela recuperação em momentos críticos e tamanhos de conjuntos de dados, com o resultado dependendo da variação dos dados espaciais ao longo de certas direções.
A validação experimental da teoria proposta concentra-se em redes de distribuição treinadas em dados lineares discretos dispostos em dois subespaços diferentes: um com alta variância (1,0) e outro com baixa variância (0,3). A análise espectral da rede revela padrões comportamentais que coincidem com previsões teóricas para vários tamanhos de conjuntos de dados e parâmetros de tempo. A rede mantém uma grande lacuna que mantém até mesmo pequenos valores de tempo em grandes conjuntos de dados, sugerindo uma tendência natural à generalização. Os espectros mostram preservação seletiva da lacuna de baixa variância enquanto perdem a sub-região de alta variância, o que corresponde às previsões teóricas para tamanhos médios do conjunto de dados.
A análise exploratória nos conjuntos de dados MNIST, Cifar10 e Celeb10 revela padrões distintos em como as dimensões latentes variam com o tamanho do conjunto de dados e o tempo de propagação. As redes MNIST mostram lacunas espectrais claras, com dimensões aumentando de 400 pontos de dados para um máximo de cerca de 4.000 pontos de dados. Embora Cifar10 e Celeb10 mostrem espaçamentos espectrais ligeiramente diferentes, eles mostram mudanças previsíveis nas pontuações de deslocamento espectral conforme o tamanho do conjunto de dados varia. Além disso, uma descoberta significativa é o aumento no tamanho incompleto do Cifar10, o que sugere efeitos persistentes de recuperação geométrica mesmo com um conjunto de dados completo. Estes resultados confirmam as previsões teóricas sobre a relação entre o tamanho do conjunto de dados e a memorização geométrica para todos os tipos de dados de imagem.
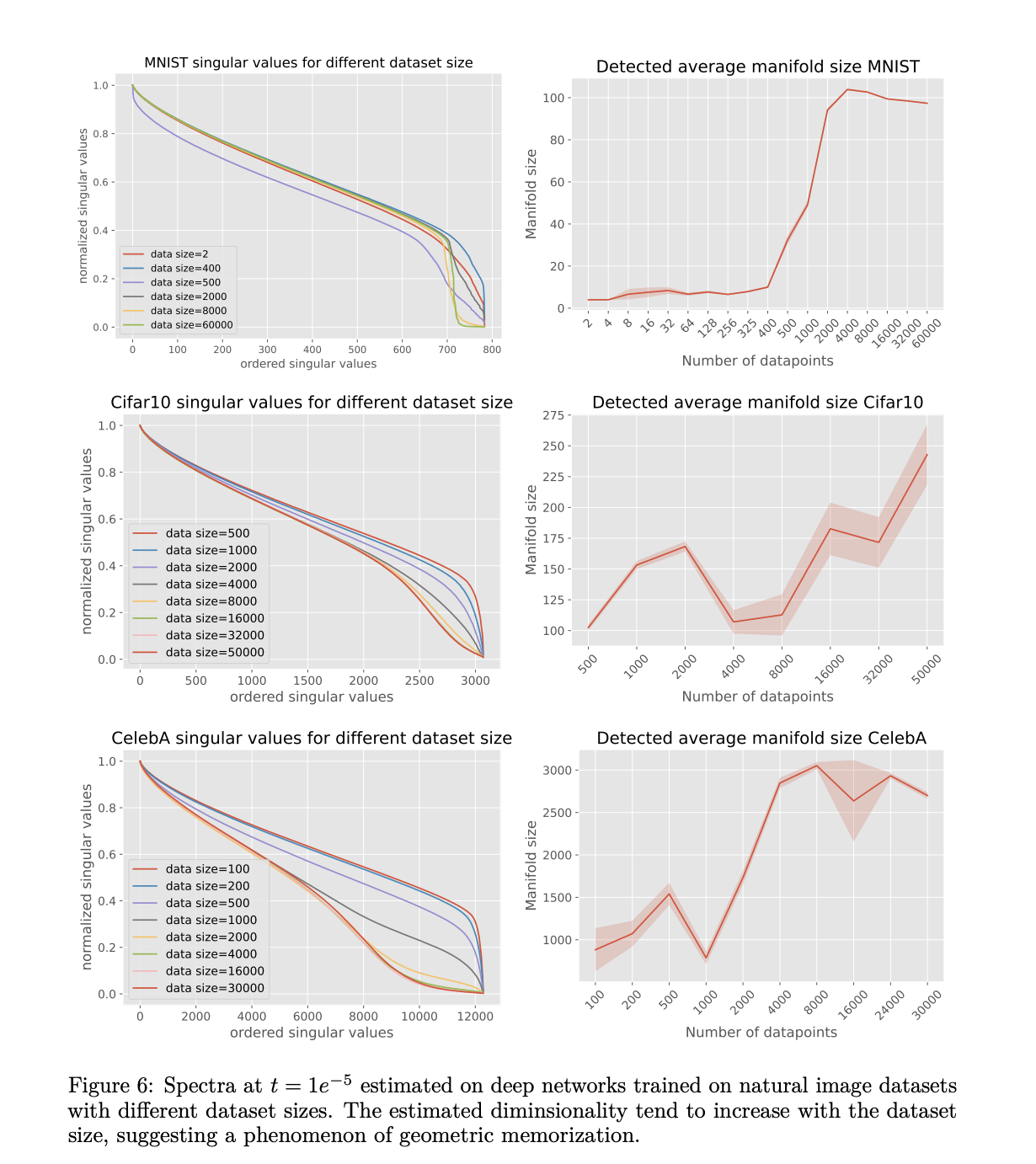
Concluindo, os pesquisadores apresentaram uma estrutura teórica para a compreensão dos modelos de distribuição reprodutiva através das lentes da física matemática, da geometria diferencial e da teoria da matriz aleatória. O artigo contém informações importantes sobre como esses modelos equilibram a recuperação e a generalização, especialmente para o tamanho do conjunto de dados e os padrões de variabilidade dos dados. Embora a análise atual se concentre em funções pontuais empíricas, o quadro teórico estabelece as bases para futuras investigações sobre os espectros Jacobianos de modelos treinados e seus desvios das previsões empíricas. Estas descobertas são importantes para desenvolver uma compreensão das capacidades de produção dos modelos de distribuição, o que é essencial para o seu desenvolvimento contínuo.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


