
Conjuntos de dados e modelos pré-treinados apresentam preconceitos internos. Muitos métodos dependem da análise visual de amostras indiferenciadas para validação automatizada por computador humano. As redes neurais profundas, geralmente modelos básicos ajustados, são amplamente utilizadas em áreas como saúde, finanças e justiça criminal, onde previsões tendenciosas podem ter um impacto significativo na sociedade. Estes modelos funcionam frequentemente como caixas negras, sem transparência e interpretabilidade, o que pode ocultar potenciais preconceitos introduzidos durante o ajuste fino. Tais preconceitos aparecem nos conjuntos de dados e podem levar a resultados prejudiciais ao enfatizar as desigualdades existentes. Abordagens recentes para abordar preconceitos em cenários de mudança populacional analisam principalmente dados de validação sem investigar os processos internos de tomada de decisão do modelo. Por exemplo, B2T [13] apenas destaca o viés dentro do conjunto de validação, ignorando como esse viés afeta os pesos do modelo. Esta lacuna sublinha a necessidade de testar métodos de decisão de modelos para compreender se os vieses dos conjuntos de dados influenciam as previsões.
Os métodos atuais para identificar vieses muitas vezes dependem da análise de amostras classificadas incorretamente com validação automatizada humano-computador. Esses métodos fornecem explicações para previsões incorretas, mas carecem de precisão para destacar correlações indesejadas. Os modelos de aprendizado de máquina geralmente capturam correlações ou “atalhos” que podem resolver a tarefa, mas não são essenciais, levando a vieses que impedem a generalização sem distribuições de treinamento. Métodos anteriores como B2T, SpLiCE e Lg detectaram o viés do conjunto de dados por meio da análise de dados. Métodos para remover preconceitos tornaram-se importantes para garantir justiça e precisão, e métodos como amostragem proporcional de grupos, reescalonamento e adição de dados são comumente usados. Em casos sem anotações, outros métodos incluem treinar e refinar o modelo tendencioso com base na sua classificação incorreta para reduzir o viés. A investigação sobre equidade na aprendizagem automática é ampla, visando criar resultados éticos e equitativos para todas as subpopulações, ao mesmo tempo que se sobrepõe à integração de base e à melhoria do desempenho para o grupo mais desfavorecido. A interpretação é importante para a justiça, pois compreender as decisões do modelo ajuda a reduzir o preconceito. Os métodos de aprendizagem adaptativos melhoram a robustez às mudanças distributivas, forçando os modelos a permanecerem consistentes em todos os locais; contudo, em casos sem localizações predefinidas, podem ser criados subconjuntos de dados para desafiar restrições fixas, utilizando algoritmos como o groupDRO para melhorar a robustez da distribuição.
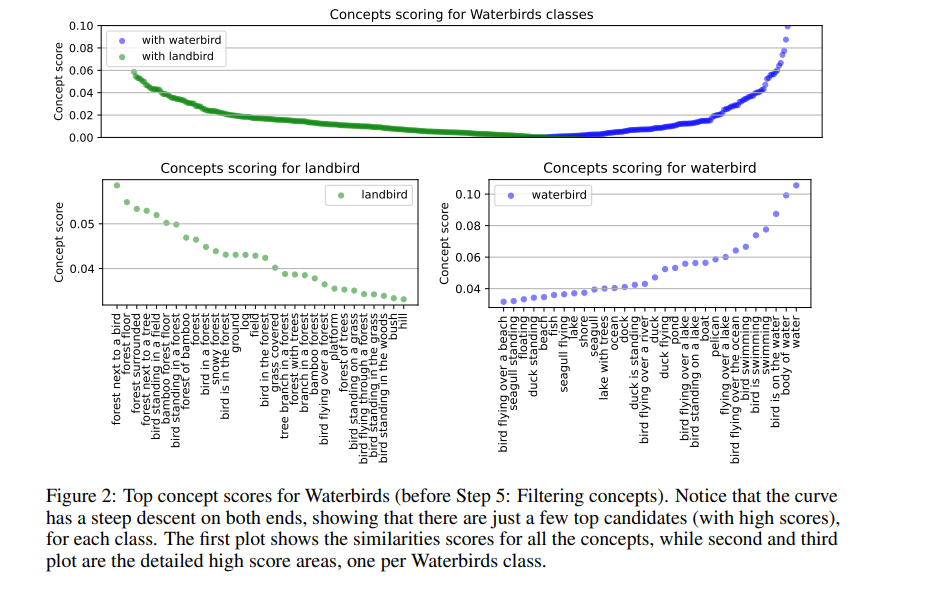
Uma equipe de pesquisadores da Universidade de Bucareste, do Instituto Romeno de Lógica e Ciência de Dados e da Universidade de Montreal surgiu com isso. ConceitoDriftuma nova abordagem projetada para identificar conceitos-chave no processo de tomada de decisão do modelo. ConceptDrift é o primeiro a usar uma abordagem de espaço de peso para detectar viés em modelos básicos bem ajustados, superando as limitações dos atuais protocolos limitados por dados. O método também inclui uma abordagem exclusiva de espaço de incorporação que revela conceitos que têm um impacto significativo nas previsões de classe. Além disso, o ConceptDrift auxilia nas investigações de preconceitos, revelando preconceitos anteriormente desconhecidos em quatro conjuntos de dados: Aves aquáticas, CelebA, Nico++ e CivilComments. Representa uma melhoria significativa na prevenção de preconceitos implícitos em relação aos métodos atuais de identificação de preconceitos. Testado em dados de imagem e texto, o ConceptDrift é altamente flexível e pode ser adaptado a outros formatos de dados com um modelo básico que inclui recursos de processamento de texto.
O método encontra conceitos vinculados incorretamente a rótulos de classe em funções de classificação. Usando o modelo subjacente, ele é treinado na camada específica de suas representações congeladas e os conceitos de texto que influenciam as previsões são identificados. Ao incorporar conceitos e amostras em um ambiente compartilhado, é alcançada uma alta similaridade de cosseno. Os pesos aplicados aos nomes das classes, que vão desde o treinamento até a discriminação de conceitos, são ponderados. Os conceitos são filtrados, mantendo-se apenas aqueles que distinguem uma categoria das demais e contribuem para a detecção de vieses. Os testes mostraram que o ConceptDrift melhora consistentemente a precisão da classificação sem sentido em todos os conjuntos de dados, superando os métodos de linha de base e de detecção de seleção de última geração.
Concluindo, ConceptDrift fornece uma nova maneira de identificar vieses ocultos em conjuntos de dados, analisando a trajetória de atualização de peso de uma sonda linear. Esta abordagem proporciona uma identificação mais precisa de correlações redundantes, melhorando a visibilidade e a interpretação dos modelos subjacentes. O estudo demonstra poderosamente sua eficácia em investigações tendenciosas em quatro conjuntos de dados: Waterbirds, CelebA, Nico++ e CivilComments, revelando preconceitos nunca antes vistos e alcançando progressos significativos na prevenção de preconceitos implícitos com métodos atuais de última geração. Validado em conjuntos de dados de imagem e texto, com um modelo básico também alimentado por processamento de texto, o ConceptDrift pode acomodar qualquer outro método.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nazmi Syed é estagiária de consultoria na MarktechPost e está cursando bacharelado em ciências no Instituto Indiano de Tecnologia (IIT) Kharagpur. Ele tem uma profunda paixão pela Ciência de Dados e está explorando ativamente a ampla aplicação da inteligência artificial em vários setores. Fascinada pelos avanços tecnológicos, a Nazmi está comprometida em compreender e aplicar inovações de ponta em situações do mundo real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


