
A ciência atmosférica e a meteorologia fizeram recentemente progressos na caracterização do tempo e do clima locais, capturando a variabilidade em escala precisa que é essencial para previsões e planeamento precisos. A física atmosférica de pequena escala, incluindo os detalhes complexos de padrões de tempestades, gradientes de temperatura e eventos locais, exige que dados de alta resolução sejam representados com precisão. Esses detalhes desempenham um papel importante em aplicações que vão desde previsões meteorológicas diárias até planos regionais de resposta a desastres. As tecnologias emergentes em aprendizagem automática abriram caminho para a criação de simulações de alta resolução a partir de dados de baixa resolução, aumentando o poder preditivo de tais dados e melhorando a modelação atmosférica regional.
Outro grande desafio nesta área é a grande diferença entre a resolução de entradas de dados em grande escala e a alta resolução necessária para capturar dados atmosféricos finos. Os dados sobre padrões climáticos em grande escala vêm frequentemente em formatos grosseiros que não conseguem captar as nuances mais sutis necessárias para a previsão espacial. O contraste entre flutuações em grande escala, como mudanças de temperatura em grande escala, e características atmosféricas pequenas e estáveis, como tempestades ou precipitação localizada, complica o processo de modelagem. Além disso, a disponibilidade limitada de dados observacionais agrava estes desafios, limitando a capacidade dos modelos existentes e muitas vezes levando a um sobreajuste ao tentar representar um comportamento atmosférico complexo.
Os métodos tradicionais para enfrentar esses desafios incluíram distribuição condicional e modelos de fluxo, que alcançaram resultados significativos na produção de detalhes finos em tarefas de processamento de imagens. Estes métodos, no entanto, precisam ser melhorados em simulações atmosféricas, onde a coerência espacial e a dinâmica multiescala são particularmente complexas. Em esforços anteriores, técnicas de aprendizagem residual foram usadas para modelar primeiro os componentes determinísticos, seguidos por informações residuais de alta resolução para capturar menos energia. Esta abordagem em duas etapas, embora importante, introduz riscos de sobreajuste, especialmente com dados limitados, e requer métodos para otimizar as propriedades determinísticas e estocásticas dos dados atmosféricos. Portanto, muitos modelos existentes precisam de ajuda para estimar estes componentes de forma eficaz, especialmente quando se trata de dados grandes e inconsistentes.
Para superar essas limitações, uma equipe de pesquisadores da NVIDIA e do Imperial College London introduziu um novo método chamado Stochastic Flow Matching (SFM). O SFM foi projetado especificamente para atender às necessidades exclusivas de dados atmosféricos, como a falta de homogeneidade espacial e a física multiescala inerente aos dados climáticos. O método redefine os dados de entrada codificando-os em uma distribuição de base latente em torno dos dados alvo em escala precisa, permitindo um melhor alinhamento antes de aplicar a simulação de fluxo. A correspondência de fluxo cria recursos realistas em pequena escala, movendo amostras desta distribuição codificada para a distribuição alvo. Esta abordagem permite que o SFM mantenha a alta fidelidade enquanto reduz o overfitting, alcançando maior robustez em comparação com os modelos de distribuição existentes.
A metodologia SFM envolve um codificador que traduz dados de resolução grosseira em uma distribuição discreta que representa os dados alvo em escala precisa. Este processo captura padrões determinísticos, a base para adicionar informações estocásticas em pequena escala por meio da correspondência de fluxos. Para lidar com a incerteza e reduzir o sobreajuste, o SFM incorpora escala de ruído adaptativa – um mecanismo que ajusta dinamicamente o ruído em resposta às previsões de erros do codificador. Ao usar estimativas de máxima verossimilhança, o SFM equilibra efeitos determinísticos e estocásticos, refinando as capacidades do modelo para produzir informações refinadas com máxima precisão. Esta inovação fornece uma forma aperfeiçoada de acomodar a variabilidade nos dados, permitindo que o modelo responda dinamicamente e evite a dependência excessiva de informações determinísticas, o que poderia causar erros.
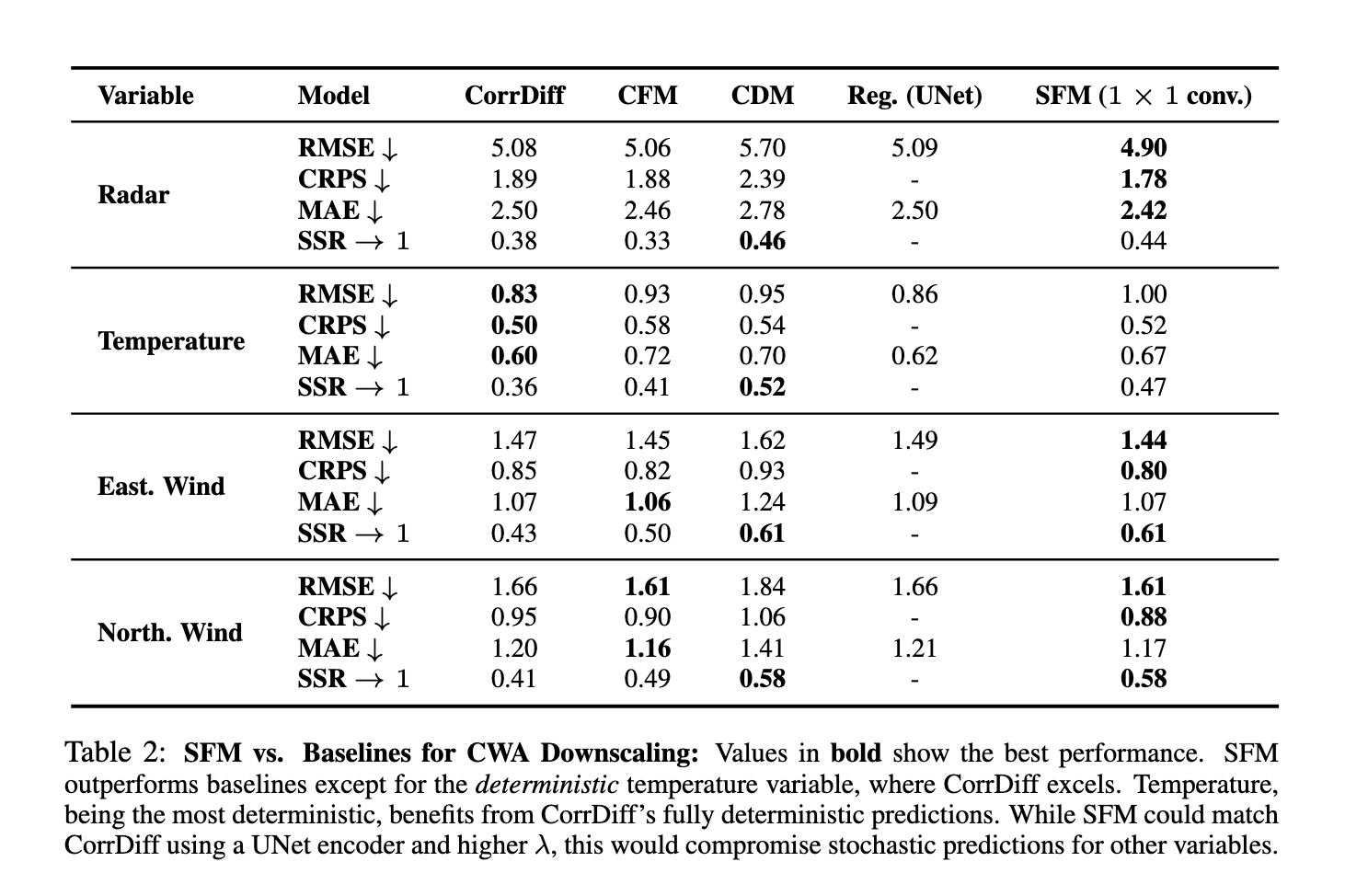
A equipe de pesquisa conduziu uma extensa pesquisa em conjuntos de dados sintéticos e do mundo real, incluindo conjuntos de dados meteorológicos da Administração Central de Meteorologia (CWA) de Taiwan. Os resultados mostraram uma melhoria significativa do SFM em relação aos métodos convencionais. Por exemplo, no conjunto de dados de Taiwan, que inclui variáveis climáticas grosseiras com alta resolução de 25 km a 2 km em escala, o SFM alcançou resultados elevados em todas as métricas múltiplas, como Root Mean Square Error (RMSE), Pontuação de Probabilidade Classificada Contínua (CRPS). ) e Spread Skill Ratio (SSR). Para a visibilidade do radar, que requer uma geração de dados completamente nova, o SFM superou as linhas de base por uma margem significativa, mostrando maior confiabilidade e captura de dados de alta frequência. Em relação ao RMSE, o SFM manteve erros inferiores às linhas de base, enquanto a métrica SSR destacou que o SFM foi melhor medido, atingindo valores próximos de 1,0, indicando um bom equilíbrio entre cobertura e precisão.
A superioridade do modelo SFM também foi demonstrada pela análise espectral, onde correspondeu estreitamente aos dados reais para todas as variáveis climáticas. Enquanto outros modelos, como distribuições condicionais e métodos de correspondência de fluxo, lutaram para alcançar alta fidelidade, o SFM produziu consistentemente representações precisas de dinâmicas de pequena escala. Por exemplo, o SFM reconstrói com sucesso dados de radar de alta frequência – ausentes de variáveis de entrada – demonstrando sua capacidade de gerar novos canais de dados fisicamente consistentes. Além disso, o SFM alcançou estes resultados sem perturbar a calibração, mostrando um conjunto bem calibrado que suporta a previsão de probabilidade em atmosferas incertas.
Com a sua estrutura inovadora, o SFM aborda com sucesso a questão contínua da harmonização de dados de baixa e alta resolução na modelagem atmosférica, alcançando um equilíbrio cuidadoso entre fatores determinísticos e estocásticos. Ao proporcionar uma redução de escala de alta fidelidade, o SFM abre novas oportunidades para uma melhor modelização climática, apoiando uma maior resiliência climática e previsões meteorológicas locais. O método SFM marca um avanço significativo na ciência atmosférica, estabelecendo um novo padrão para a precisão da modelagem de dados climáticos de alta resolução, especialmente quando os modelos convencionais enfrentam limitações devido à escassez de dados e à má resolução.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


: um novo método prático projetado para melhorar as habilidades de compreensão de imagens para modelos de linguagem visual em larga escala (LVLMs)")