
A análise estática é uma parte natural do processo de desenvolvimento de software, pois permite tarefas como depuração, otimização de programa e depuração. Os métodos tradicionais têm duas desvantagens principais: métodos baseados na integração de código falharão inevitavelmente em qualquer situação de desenvolvimento em que o código esteja incompleto ou mude rapidamente, e a necessidade de adaptação requer conhecimento profundo de compiladores internos e IRs que não são acessíveis a muitos desenvolvedores. Esses problemas impedem que as ferramentas de análise estática sejam amplamente utilizadas em situações do mundo real.
As ferramentas de análise estática existentes, como FlowDroid e Infer, usam IRs para detectar problemas em sistemas. Porém, dependem de compilação, o que limita seu uso a códigos dinâmicos e incompletos. Além disso, não possuem suporte suficiente para funções de integração para analisar as necessidades de usuários específicos; em vez disso, a customização requer conhecimento profundo da infraestrutura do desenvolvedor. Sistemas baseados em consultas, como CodeQL, buscam mitigar essas restrições, mas apresentam desafios de aprendizagem significativos de linguagens complexas específicas de domínio e interfaces de aplicativos complexas. Estas deficiências limitam a sua eficácia e a sua utilização em diversas situações de programação.
Pesquisadores da Purdue University, da Universidade de Ciência e Tecnologia de Hong Kong e da Universidade de Nanjing projetaram o LLMSA. Esta estrutura neuro-simbólica visa quebrar as restrições associadas à análise estática padrão, permitindo funcionalidade perfeita e personalização total. A estrutura LLMSA utiliza uma linguagem política orientada a dados para dividir tarefas analíticas complexas em problemas menores e gerenciáveis. A metodologia aborda com sucesso erros visuais em modelos de linguagem, combinando análise determinística focada em atributos sintáticos com raciocínio neural visando elementos semânticos. Além disso, sua implementação de técnicas complexas, como avaliação preguiçosa, onde os cálculos neurais são adiados até a necessidade, e o processamento incremental e paralelo que otimiza o uso de recursos computacionais e reduz a redundância, melhora muito seu desempenho. Esta estrutura arquitetônica posiciona o LLMSA como uma alternativa flexível e robusta às técnicas analíticas tradicionais.
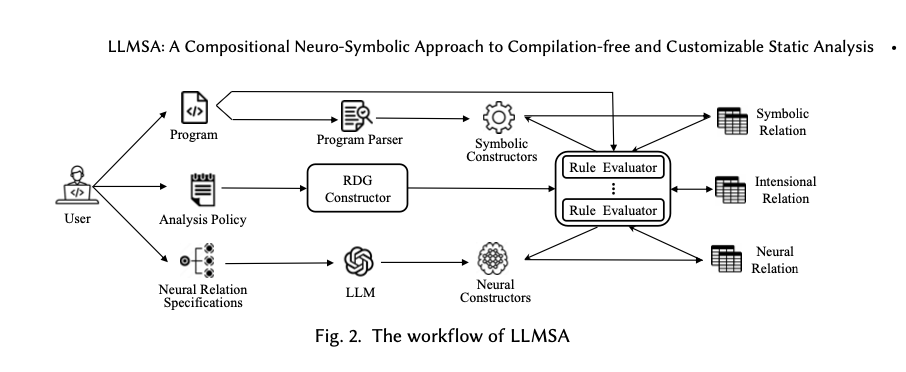
O quadro proposto combina elementos simbólicos e emocionais para satisfazer os seus objectivos. Os modeladores determinam árvores sintáticas abstratas (ASTs) de forma determinística para encontrar características sintáticas, enquanto os componentes neurais usam modelos linguísticos de grande escala (LLMs) para raciocinar sobre relações semânticas. Uma linguagem de restrição de política no estilo datalog permite ao usuário mapear operações, dividindo-as em regras específicas para teste. A avaliação preguiçosa economiza custos computacionais, pois executa funções neurais apenas quando necessário, enquanto o processamento incremental economiza cálculos desnecessários de processos iterativos. A simultaneidade permite que regras independentes sejam executadas simultaneamente e melhora muito o desempenho. A estrutura foi testada com programas Java para tarefas como análise de alias, divisão de programas e depuração, demonstrando sua versatilidade e escalabilidade.
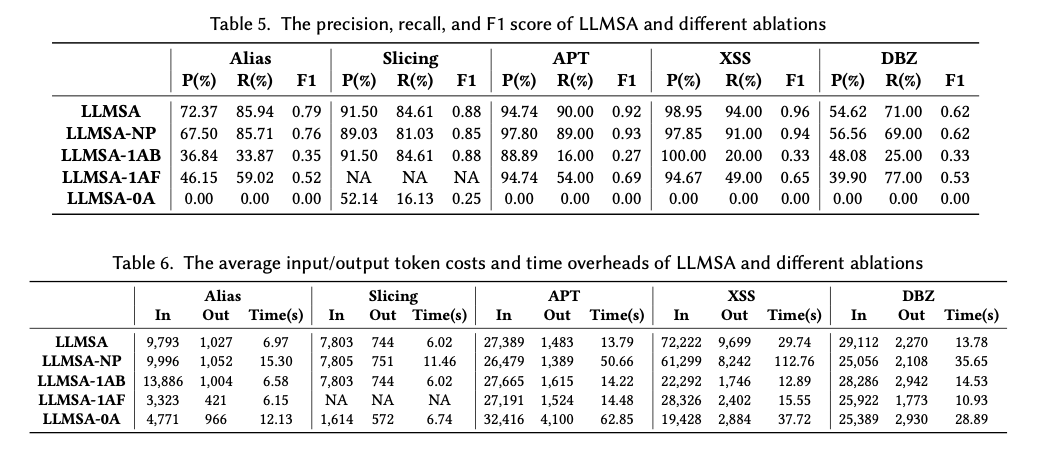
LLMSA teve um bom desempenho em várias tarefas de análise estática. Obteve 72,37% de precisão e 85,94% de recall para análise de alias e 91,50% de precisão e 84,61% de recall para corte de programa. Em tarefas de detecção de bugs, teve uma precisão média de 82,77% e um recall de 85,00%, superando assim ferramentas dedicadas como NS-Slicer e Pinpoint por uma margem justa para a pontuação F1. Além disso, a metodologia conseguiu identificar 55 das 70 vulnerabilidades no conjunto de dados TaintBench, com uma taxa de recall que excedeu a ferramenta padrão da indústria em 37,66% e uma melhoria significativa no resultado F1. O LLMSA obteve uma melhoria de até 3,79× em comparação com outros projetos em termos de eficiência computacional, demonstrando assim sua capacidade de realizar diversas tarefas analíticas de forma eficaz e eficiente.
Este estudo apresenta o LLMSA como uma abordagem revolucionária para análise estática, que supera os desafios associados à dependência de cluster e à personalização limitada. Desempenho robusto, escalabilidade e flexibilidade entre aplicativos no contexto de diferentes tarefas de análise, alcançados usando uma estrutura neurosimbólica e uma linguagem política bem definida. Eficiência e flexibilidade garantem que o LLMSA seja um recurso valioso, facilitando métodos avançados de análise estática para desenvolvimento de software.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)
![OCR (Ocline Character Recognition) – Definição, vantagens, desafios e casos de uso [Infographic]](https://i0.wp.com/f5b623aa.rocketcdn.me/wp-content/uploads/2022/09/Blog-SM_What-is-OCR.jpg?w=320&resize=320,200&ssl=1 "OCR (Ocline Character Recognition) – Definição, vantagens, desafios e casos de uso [Infographic]")
: Estendendo a Estrutura HELM para VLMs")
