
Pesquisadores da Projeção de Arte Multimodal (MAP) lançaram o FineFineWeb, um grande sistema de código aberto para classificação automática de dados finos da web. Este projeto divide o Fineweb extraído em 67 classes distintas com dados iniciais abundantes. Além disso, é realizada uma análise abrangente da relação entre categorias verticais e benchmarks padrão, bem como uma análise detalhada de URL e distribuição de conteúdo. O programa oferece conjuntos de testes especiais para o teste PPL, incluindo opções de validação de “copo pequeno” e “copo médio”. Materiais completos de treinamento para uso de FastText e Bert são compatíveis com o conjunto de dados, com sugestões futuras para medição dos dados com base no método RegMix.
O processo de criação do banco de dados FineFineWeb segue um fluxo de trabalho de várias etapas. A primeira versão do FineWeb usa técnicas pull-down e MinHash. A rotulagem de URL usa GPT-4 para processar mais de um milhão de URLs raiz, separando-os em URLs de domínio de interesse (DoI) e URLs de domínio de não interesse (DoNI). Além disso, a fase de recuperação grosseira envolve amostragem específica de domínio com base em URLs raiz rotulados, com a instrução Qwen2-7B lidando com a rotulagem de 500 mil pontos de dados positivos ou negativos. Os modelos FastText, treinados nesses dados rotulados, executam operações de recuperação de granulação grossa no FineWeb para gerar dados DoI grosseiros.
O estágio de ajuste fino otimiza o processo de refinamento de dados usando a instrução Qwen2-72B para rotular os dados DoI grosseiros, criando pontos de dados positivos de 100K Dol e negativos de 100K Dol. Em seguida, o modelo BERT, treinado nesses dados rotulados, realiza o ajuste fino para gerar um subconjunto de DoI para FineFineWeb. Além disso, todas as iterações grosseiras e finas ocorrem em três rodadas com alguns ajustes:
- FastText é treinado novamente usando os dados iniciais atualizados, que incluem amostras lembradas pelo BERT, amostras descartadas pelo BERT e dados iniciais previamente rotulados.
- O modelo BERT é mantido congelado durante a próxima iteração.
- As etapas de treinamento FastText, recuperação forte e recuperação positiva são repetidas sem renomear os dados com modelos Qwen2-Instruct.
A análise de similaridade de domínio usa um método de análise complexo usando amostras igualmente ponderadas em subconjuntos de domínio, analisando um bilhão de tokens de subconjuntos de domínio. Em seguida, o modelo BGE-M3 é usado para gerar dois tipos de embeddings: embeddings de domínio a partir de amostras de subconjuntos de domínio e embeddings de benchmark a partir de amostras de benchmark. A análise conclui calculando as distâncias MMD e Wasserstein entre embeddings de domínio e embeddings de benchmark para medir relacionamentos de domínio.
A análise de similaridade revela vários padrões importantes nas relações domínio-benchmark. Os benchmarks relacionados ao código (MBPP e HumanEval) mostram uma distância significativa da maioria dos domínios sem estatísticas, indicando uma representação limitada do código no conjunto de dados. Os benchmarks de conhecimento comum (Hellaswag, ARC, MMLU, BoolQ) mostram uma relação estreita com muitos domínios, sugerindo uma ampla distribuição de conhecimento, ao mesmo tempo que excluem conteúdo de jogos de azar. Além disso, GSM8K e TriviaQA mostram diferenças significativas específicas de domínio, especialmente em estatísticas e conteúdo factual. Finalmente, o domínio do jogo destaca-se claramente, mostrando pouca sobreposição com outros domínios e benchmarks.
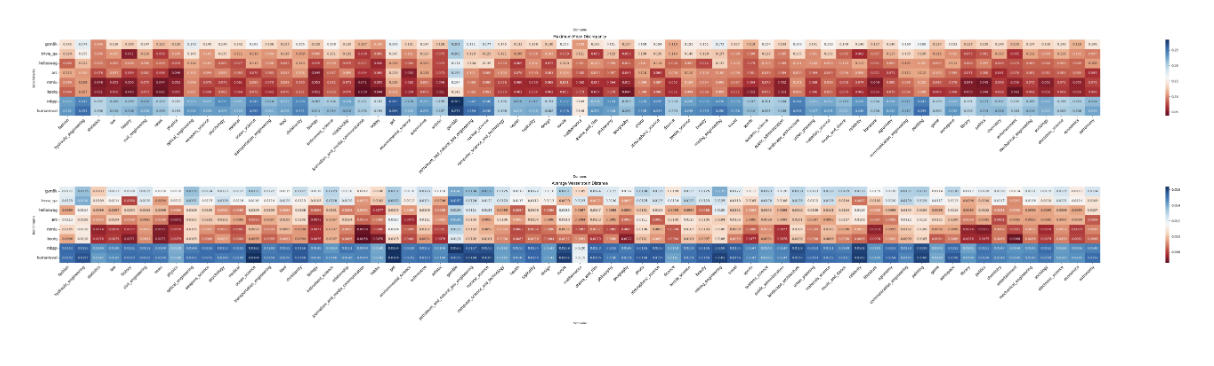
A análise de replicação domínio a domínio examina a variação de URL entre domínios usando valores TF-IDF. Pontuações altas do TF-IDF indicam URLs exclusivos para um domínio específico, enquanto valores baixos sugerem URLs comuns para todos os domínios. A análise revela pouca sobreposição em todos os domínios, exceto nas categorias assunto, animal de estimação e espiritualidade. Um estudo de correlação de referência de domínio, realizado em 28 modelos, compara o desempenho específico de domínio (BPC) com níveis de desempenho de referência usando a correlação de Spearman. Os domínios relacionados a STEM mostram fortes correlações com benchmarks orientados ao raciocínio (ARC, MMLU, GSM8K, HumanEval, MBPP), enquanto domínios intensivos em conhecimento, como literatura e história, correlacionam-se altamente com benchmarks baseados em fatos, como TriviaQA.
Confira eu Conjunto de dados de novo Tuitar. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


