
O pensamento lógico continua sendo um lugar vital onde os sistemas de IA lutam, apesar do desenvolvimento da linguagem e do conhecimento. Compreender um pensamento lógico da IA é importante para melhorar os programas automatizados em áreas como planejamento, tomada de decisão e problemas. Ao contrário do senso comum, o pensamento lógico requer redução precisa da restauração, tornando -o LLMS mais desafiador para que eles possam.
Um obstáculo ao pensamento razoável dentro da IA para tratar os complexos problemas complexos. Os modelos atuais estão lutando com complexos e dependentes, dependendo dos padrões estatísticos em vez de voluntariado. Esta revista é mais evidente à medida que as dificuldades difíceis aumentam, levando à diminuição da precisão. Tais limitações incluem preocupações sobre aplicações máximas altas, como análise legal, o teorema que prova e um sorriso científico, onde é necessário um declínio razoável. Os pesquisadores pretendem abordar as mudanças, projetando um sistema de avaliação complexo que avalia sistematicamente.
Os métodos de pensamento tradicional usam problemas de contentamento (CSPs), fornecem modelos formais de teste formais. Os CSPs permitem testes diretos, finalizando os dados de treinamento e garantindo que os modelos dependam de habilidades de pensamento real. Os quebra -cabeças da grade lógica, subconjunto de CSPs, são testes aplicáveis para testar o pensamento formal na IA. Esses quebra -cabeças precisam de uma redução formal com base nos problemas descritos e têm pedidos reais de terras para a alocação de serviços, planejamento e edição padrão. No entanto, mesmo os LLMs mais avançados lutaram por tais atividades quando dificuldades difíceis crescem mais do que um certo limite.
Uma equipe de pesquisa da Universidade de Washington, do Allen Institute for IA e da Universidade de Stanford lançou a Zeblogy, uma estrutura de classificação mais forte no pensamento lógico. Questões zibralógicas de quebra -cabeças sensíveis de acessíveis complexos, garante o regime regulamentado. A estrutura evita vazamentos de dados e fornece uma análise detalhada da capacidade do LLM de gerenciar tarefas complexas de consulta. O zibalógico serve como uma etapa importante para entender os critérios básicos dos LLMs nas reflexões e medidas fixas.
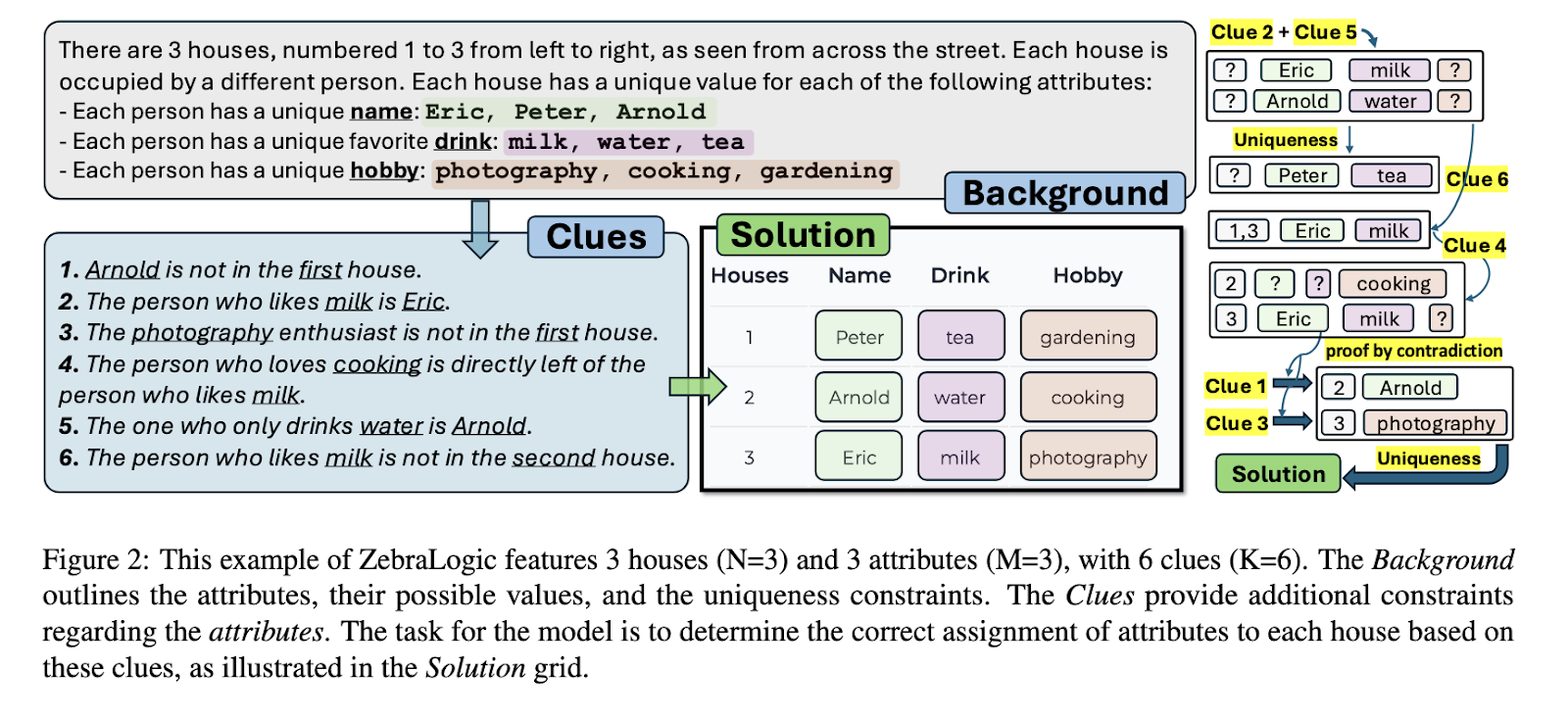
A estrutura do zibalógico cria puels lógicos em vários níveis de dificuldade com base em duas técnicas baseadas em complexidade: o tamanho da pesquisa e o cálculo de Z3, métrica, são menores para calcular o solucionador SMT. O estudo TERST liderando rendas líderes de renda, incluindo a LLAMA da Meta, os modelos O1 Open e o DeepSeekr1, e revelou uma complexidade significativa de devanço de aceitação. A estrutura é permitida na avaliação direta de todos os níveis únicos de dificuldade, tornando -a uma das análises mais planejadas do LLMS até agora. Com a diversidade de obstáculos, os pesquisadores podem decidir o impacto do problema no desempenho lógico.
Os testes feitos de Zibraligic Express “Dificuldades de Dificuldade”, quando o desempenho do LLM é muito baixo com as dificuldades dos problemas. Modelo Better, O1, recebeu uma precisão completa de 81,0%, enquanto o DeepSeekR1 seguiu 78,7%. No entanto, mesmo essas lutas altas lutaram quando a pesquisa de quebra -cabeça é excedida 10 ^ 7 Possíveis 7 possíveis configurações. Os quebra -cabeças do meio indicam uma diminuição significativa, mantendo 92,1% precisa, mas diminui 42,5% em grandes problemas. Deepseez1 mostrou desempenho semelhante, brilho em situações simples, mas sofre eficácia de tarefas complexas. Modelos baixos Os níveis como LLAMA-3.1-405B e Gemini-1.5-Pro exibiram um aplicativo de lacuna importante, até 32,6% e 30,5% completamente, respectivamente, respectivamente.

O crescente tamanho do modelo não reduziu significativamente a maldição de dificuldade, pois os padrões de trateeueauaueaueueaueueauaeueaides, apesar do treinamento avançado. A pesquisa considerou vários métodos de desenvolvimento de habilidades de pensamento do LLMS, incluindo estratégias de amostragem e n. A melhor precisão dos modelos N N se esforça de 10 configurações de espaço de pesquisa ^ 9, o que sugere questões ambientais na construção atual. Significativamente, os modelos O1 geraram os tokens de consulta mais sutis do que outros LLMs, atingindo os 5.144 Touchkoks em torno de 544 543 tokens. Essas descobertas destacam a importância de alinhar estratégias para consultar, em vez de apenas medir modelos.
Os exames zibralógicos enfatizam limitações básicas no poder dos LLMs para medir mais pensamentos lógicos do que dificuldades equilibradas. A aquisição enfatiza a necessidade de outros meios, como a estrutura do pensamento desenvolvido e do planejamento lógico, em vez de dependente da extensão do modelo. Estudos mostram um banco importante para o público, que fornece informações sobre a refeição de caminhos aprimorados do pensamento lógico. Lidar com esses desafios será importante para o desenvolvimento de programas de IA capazes de reduzir a redução confiável e lógica.
Enquete Papel e projeto de papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Registre a plataforma de IA de código aberto: 'Sistema de código aberto interestagente com muitas fontes para testar o programa difícil' (Atualizado)
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo

: uma família multilíngue de última geração para preencher a lacuna linguística na IA")
: uma nova estrutura bidirecional de tokenização de fala aprimorada por Mamba para detecção eficiente de tempo de fala")