
Compreender vídeos longos, como imagens de CFTV de 24 horas ou filmes completos, é um grande desafio no processamento de vídeo. Principais modelos de linguagem (LLMs) demonstraram grande potencial no tratamento de dados multimodais, incluindo vídeos, mas enfrentam dificuldades com grandes volumes de dados e elevados requisitos de processamento para conteúdos longos. Muitos métodos existentes para gerenciar vídeos longos perdem informações importantes, pois simplificar o conteúdo visual geralmente remove informações sutis, mas importantes. Isso limita a capacidade de interpretar e analisar com eficácia dados de vídeo complexos ou dinâmicos.
As técnicas atualmente usadas para compreender vídeos longos incluem a extração de quadros-chave ou a conversão de quadros de vídeo em texto. Esses métodos facilitam o processamento, mas levam a uma enorme perda de informações, pois detalhes sutis e nuances visuais são removidos. LLMs de vídeo avançados, como Video-LLaMA e Video-LLaVA, tentam melhorar a compreensão usando apresentações multimodais e módulos especializados. No entanto, esses modelos exigem muitos recursos computacionais, são específicos para cada tarefa e enfrentam vídeos longos ou irregulares. Os sistemas RAG multimodais, como iRAG e LlamaIndex, melhoram a aquisição e o processamento de dados, mas perdem informações valiosas ao converter dados de vídeo em texto. Estas limitações impedem que os métodos atuais capturem e explorem totalmente a profundidade e a complexidade do conteúdo de vídeo.
Para enfrentar os desafios da compreensão do vídeo, pesquisadores de Sobre pesquisa de IA de novo Instituto Binjiang da Universidade de Zhejiang foi introduzido Agentesmétodo de duas etapas: Video2RAG para pré-processamento e DnC Loop para processamento. No Video2RAG, os dados brutos de vídeo são capturados por cena, informações visuais e transcrição de áudio para criar um resumo das legendas da cena. Essas legendas são inseridas na máquina e armazenadas em um banco de dados enriquecido com informações adicionais sobre horário, local e detalhes do evento. Dessa forma, o processo evita a entrada de grandes contextos nos modelos de linguagem, evitando assim problemas como sobrecarga de tokens e complexidade conceitual. Para realizar a tarefa, as perguntas são codificadas e esses segmentos de vídeo são recuperados para análise posterior. Isso garante uma compreensão eficiente do vídeo, equilibrando a representação detalhada dos dados e a viabilidade computacional.
O DNC Loop usa uma estratégia de dividir e conquistar, dividindo iterativamente as tarefas em subtarefas gerenciáveis. O módulo Conquest verifica funções, direciona isolamento, manipulação de ferramentas ou manutenção direta. O módulo Divisor divide funções complexas e o Classificador lida com erros fatais. A estrutura iterativa da árvore de tarefas ajuda no gerenciamento e resolução eficiente de tarefas. A combinação do pré-processamento programado pelo Video2RAG e a estrutura robusta do DnC Loop permite que o OmAgent forneça um sistema completo de compreensão de vídeo que pode lidar com consultas complexas e gerar resultados precisos.
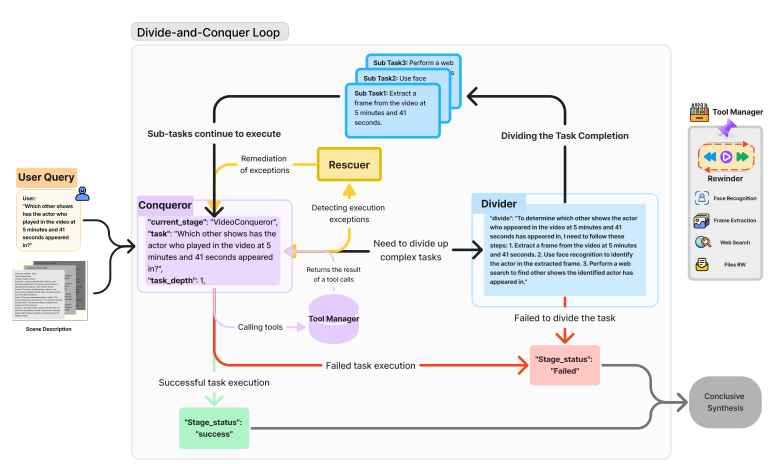
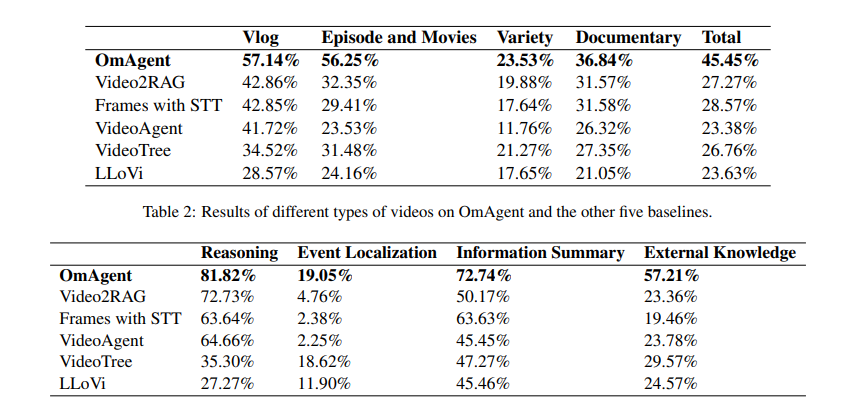
Os pesquisadores realizaram testes para verificar a capacidade do OmAgent de resolver problemas complexos e compreender vídeos longos. Eles usaram dois benchmarks, MBPP (976 funções Python) e FreshQA (perguntas e respostas dinâmicas do mundo real), para testar a resolução geral de problemas, com foco no planejamento, execução de tarefas e uso de ferramentas. Eles projetaram um benchmark com mais de 2.000 pares de perguntas e respostas para compreensão de vídeo com base em vários vídeos longos, testes de hipóteses, localização de eventos, resumo de informações e conhecimento externo. O OmAgent apresenta desempenho consistentemente inferior em todas as métricas. No MBPP e FreshQA, o OmAgent obteve pontuação de 88,3% e 79,7%, respectivamente, superando o GPT-4 e o XAgent. O OmAgent recebeu 45,45% do total de operações de vídeo em comparação com Video2RAG (27,27%), frames com STT (28,57%) e outras bases. Teve sucesso no raciocínio (81,82%) e no resumo das informações (72,74%), mas teve dificuldade para localizar os acontecimentos (19,05%). Os recursos de loop e feedback Divide-and-Conquer (DnC) do OmAgent melhoraram muito o desempenho em tarefas que exigem análise detalhada, mas a precisão na localização de eventos permaneceu um desafio.
Em suma, o que é proposto Agentes combina um RAG multimodal com uma estrutura geral de IA, que permite compreensão avançada de vídeo com poder cognitivo quase infinito, um mecanismo de memória secundário e um aplicativo independente de ferramenta. Alcançou forte desempenho em muitos benchmarks. Embora desafios como orientação de eventos, alinhamento de personagens e compatibilidade audiovisual permaneçam, este método pode servir como base para pesquisas futuras para melhorar a dissonância de caracteres, a sincronização audiovisual e a compreensão de pistas de áudio não-verbais, para melhorar o compreensão do vídeo de formato longo.
Confira eu Papel de novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 Recomendar plataforma de código aberto: Parlant é uma estrutura que muda a forma como os agentes de IA tomam decisões em situações voltadas para o cliente. (Promovido)
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)


