
A geração avançada de recuperação (RAG) melhora a extração de grandes modelos de linguagem (LLMs) usando bases de conhecimento externas. Esses sistemas funcionam encontrando informações relevantes vinculadas ao input e incorporando-as na resposta do modelo, melhorando a precisão e a consistência. No entanto, o sistema RAG levanta questões relativas à segurança e privacidade dos dados. Esses bancos de dados estarão sujeitos a informações confidenciais que podem ser acessadas de forma maliciosa, onde as informações podem levar o modelo a revelar informações confidenciais. Isto cria um risco significativo em aplicações como suporte ao cliente, ferramentas organizacionais e chatbots médicos, onde a proteção de informações confidenciais é fundamental.
Atualmente, os métodos utilizados em sistemas de Geração Aumentada de Recuperação (RAG) e Modelos de Grandes Linguagens (LLMs) enfrentam sérias vulnerabilidades, especialmente em termos de privacidade e segurança de dados. Métodos como ataques de inferência de membros (MIA) tentam identificar se determinados pontos de dados fazem parte do treinamento. No entanto, técnicas mais avançadas concentram-se no roubo de informações confidenciais diretamente dos sistemas RAG. Métodos, como TGTB e PIDE, baseiam-se em informações estáticas de conjuntos de dados, limitando a sua adaptabilidade. O Dynamic Greedy Embedding Attack (DGEA) introduz algoritmos dinâmicos, mas requer comparações repetidas, tornando-o difícil e consumidor de recursos. Rag-Thief (RThief) usa métodos in-memory para extrair fragmentos de texto, porém sua flexibilidade é altamente dependente de condições predefinidas. Esses métodos exigem muito trabalho, são adaptáveis e eficientes, muitas vezes deixando os sistemas RAG propensos a violações de privacidade.
Para abordar questões de privacidade em sistemas de Geração Aumentada de Recuperação (RAG), pesquisadores da Universidade de Perugia, da Universidade de Siena e da Universidade de Pisa propuseram uma estrutura baseada em relações projetada para extrair informações privadas e, ao mesmo tempo, impedir vazamentos repetidos de informações. A estrutura utiliza modelos de linguagem de código aberto e codificadores de frases para explorar automaticamente bases de conhecimento ocultas, sem depender de serviços de pagamento individuais ou de conhecimento prévio do sistema. Ao contrário de outros métodos, este método aprende continuamente e tende a aumentar a cobertura da base de conhecimento secreta e a avaliação extensiva.
A estrutura funciona em um ambiente cego usando um mapa de representação de recursos e técnicas dinâmicas para explorar a base de conhecimento secreta. Ele é implementado como um ataque de caixa preta que funciona em computadores domésticos padrão, sem exigir hardware especial ou APIs externas. Este método enfatiza a transferibilidade das configurações RAG e fornece uma maneira simples e econômica de expor vulnerabilidades em comparação com métodos anteriores estáticos ou com uso intensivo de recursos.
Os pesquisadores pretendem obter sistematicamente as informações secretas do KKK e reproduzi-las no sistema do invasor como K∗K^*K∗. Conseguiram isto concebendo perguntas flexíveis que utilizavam uma abordagem baseada na identificação das “âncoras” mais relevantes associadas a informações ocultas. Ferramentas de código aberto, incluindo um pequeno LLM pronto para uso e incorporador de texto, são usadas para preparar perguntas, criar incorporações e comparar comparações. O ataque seguiu um algoritmo passo a passo que gerou consultas dinamicamente, removeu e atualizou âncoras e refinou pontuações de relevância para aumentar a exposição das informações. Fragmentos duplicados e âncoras foram identificados e descartados usando medidas de similaridade de cosseno para garantir extração eficiente de dados e tolerância a ruído. O processo continuou repetidamente até que todos os pinos não estivessem relacionados, interrompendo efetivamente o ataque.
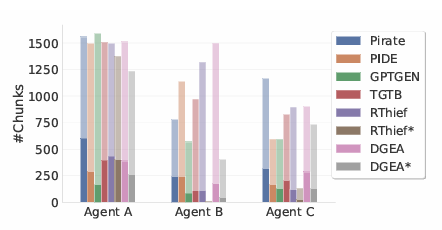
Os pesquisadores conduziram experimentos simulando cenários de ataque do mundo real em três sistemas RAG usando diferentes LLMs do lado do atacante. O objetivo era extrair o máximo de informações possível de bases de conhecimento secretas, com cada programa RAG utilizando um agente virtual como um chatbot para interação do usuário por meio de perguntas em linguagem natural. Foram definidos três agentes: Agente A, um chatbot de suporte diagnóstico; Agente B, assistente de pesquisa química e farmacêutica; e o Agente C, o assistente educacional das crianças. As bases de conhecimento secretas foram simuladas usando conjuntos de dados, com 1.000 blocos de amostras para cada agente. Os experimentos compararam o método proposto com concorrentes como TGTB, PIDE, DGEA, RThief e GPTGEN em diferentes configurações, incluindo ataques limitados e ilimitados. Métricas como cobertura de navegação, vazamento de informações, vazamento de pedaços, vazamento único de pedaços e tempo de geração de consulta de ataque foram usadas para avaliação. Os resultados mostraram que o método proposto teve melhor desempenho que seus concorrentes em roteamento e vazamento de informações em situações restritas, com ainda mais vantagens em situações irrestritas, superando RThief e outros.
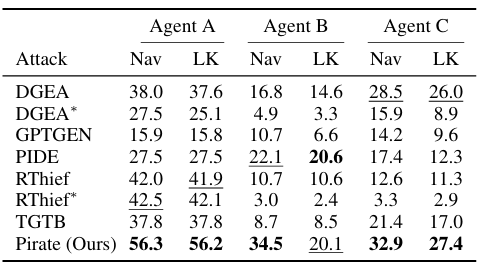
Concluindo, o método proposto apresenta uma técnica de ataque dinâmico que extrai informações privadas de sistemas RAG com adversários eficientes em termos de cobertura, informações vazadas e tempo necessário para construir consultas. Isto destacou desafios como a dificuldade de comparar componentes extraídos e a necessidade de uma proteção mais robusta. A pesquisa pode constituir a base para trabalhos futuros para desenvolver mecanismos de defesa robustos, ataques direcionados e métodos de teste aprimorados para sistemas RAG.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


