
Principais modelos de pensamento eles são desenvolvidos para resolver problemas complexos, dividindo-os em etapas pequenas e gerenciáveis e resolvendo cada etapa individualmente. Modelos são usados para reforçar a aprendizagem para desenvolver suas habilidades de pensamento e desenvolver soluções mais detalhadas e lógicas. No entanto, embora este método seja bem sucedido, tem os seus desafios. Pensar demais e errar por informações ausentes ou insuficientes vêm de um processo de pensamento prolongado. Lacunas na compreensão podem perturbar toda a cadeia de raciocínio, dificultando a obtenção de conclusões precisas.
As abordagens tradicionais para grandes modelos de inferência visam melhorar o desempenho aumentando o tamanho dos modelos ou aumentando os dados de treinamento durante a fase de treinamento. Embora as escalas de tempo experimentais mostrem potencial, os métodos atuais dependem fortemente de modelos estáticos e parametrizados que podem utilizar informações externas quando a compreensão interna é insuficiente. Estratégias como combinações de recompensas políticas e Pesquisa de árvore de Monte CarloA compilação deliberada de erros e a abstração de dados melhoram o pensamento, mas não conseguem internalizar ou desenvolver totalmente as habilidades de pensamento. Recuperação de geração avançada (RAG) sistemas que enfrentam algumas limitações ao integrar a recuperação externa de informações, mas se esforçam para integrar as capacidades robustas de raciocínio vistas em modelos avançados. Essas lacunas reduzem a capacidade de resolver eficazmente tarefas complexas e que exigem muito conhecimento.

Para resolver o desafio das tarefas de raciocínio em várias etapas que requerem conhecimento externo, pesquisadores de Universidade Renmin da China de novo Universidade Tsinghua propôs que eu Quadro Pesquisa-o1. A estrutura integra instruções de tarefas, perguntas e informações retornadas em uma cadeia coerente de pensamento para encontrar soluções e respostas lógicas. Ao contrário dos modelos tradicionais que combatem a perda de informação, Pesquisa-o1 estende o método de produção com recuperação aumentada adicionando um módulo Reason-to-documents. Este módulo compila as longas informações retornadas em etapas precisas, garantindo um fluxo lógico. O processo iterativo continua até que uma cadeia completa de raciocínio e uma resposta final sejam formadas.
A estrutura foi comparada à lógica vanilla e aos métodos básicos aprimorados de recuperação. O raciocínio básico tende a falhar quando surgem lacunas de conhecimento, enquanto os métodos básicos avançados encontram documentos demasiado detalhados e redundantes, perturbando a coerência do raciocínio. A estrutura Search-o1 evita isso criando pesquisas dinamicamente sempre que necessário, extraindo documentos e convertendo-os em etapas de pensamento claras e relacionadas. O método do agente é outro servidor que garante a integração de informações relevantes, e o Reason-Within-Documents parece ser compatível, por isso mantemos o pensamento mais preciso e estável.
Os pesquisadores testaram a estrutura em duas categorias de atividades: tarefas desafiadoras de pensamento de novo atividades de perguntas e respostas (QA) de domínio aberto. Tarefas de pensamento desafiadoras estão incluídas GPQAConjunto de dados de controle de qualidade para nível de doutorado em ciências de múltipla escolha; parâmetros de referência estatísticos, como MATEMÁTICA500, AMC2023de novo AIME2024; de novo LiveCodeBench para testar habilidades de codificação. As atividades de controle de qualidade de código aberto foram testadas usando conjuntos de dados semelhantes Perguntas naturais (NQ), CuriosidadesQA, HotpotQA, 2WikiMultihopQA, MuSiQuede novo Bambu. A avaliação envolveu uma comparação com métodos básicos, incluindo métodos de raciocínio direto, raciocínio de aumento de recuperação aumentada e a estrutura Search-o1 proposta pelos pesquisadores. Os testes foram realizados sob diferentes condições usando uma configuração fixa, incluindo QwQ–32B– Visualize o modelo como uma lombada e API de pesquisa na Web do Bing para recuperar.
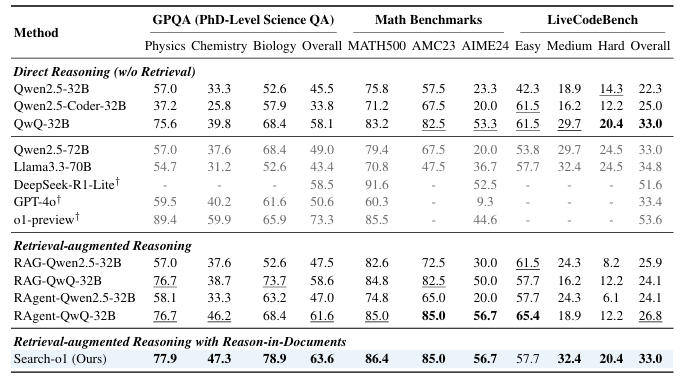
Resultados ele mostrou isso QwQ-32B-Visualização ele se destacou em todas as tarefas de pensamento, superando grandes modelos como Q2.5-72B de novo Lhama3.3-70B. Search-o1 métodos de recuperação menos eficazes, como RAgente-QwQ-32B com benefícios significativos de compatibilidade e integração de informações. Por exemplo, em média, Search-o1 é ignorado RAgente-QwQ-32B de novo QwQ-32B com 4,7% de novo 3,1%respectivamente, e alcançar um 44,7% melhor do que modelos menores semelhantes Q2.5-32B. Comparação com especialistas humanos em GPQA O conjunto expandido revelou a superioridade do Search-o1 na integração de estratégias de raciocínio, especialmente em tarefas relacionadas à ciência.
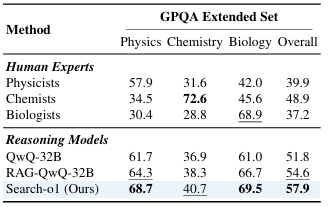
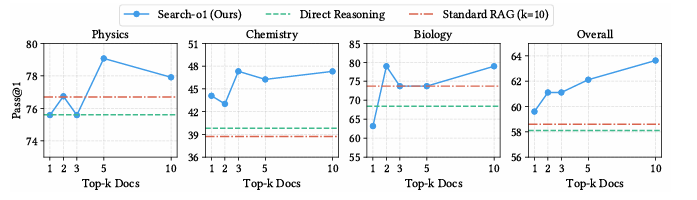
Concluindo, a estrutura proposta abordou o problema da falta de conhecimento em modelos de raciocínio em larga escala, incorporando um módulo Reason-in-Documents de geração aumentada para permitir um melhor uso do conhecimento externo. Esta estrutura pode ser a base para pesquisas futuras para desenvolver sistemas de recuperação, análise de documentos e resolução inteligente de problemas em todos os domínios complexos.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
✅ [Recommended Read] Nebius AI Studio se expande com modelos de visão, novos modelos de linguagem, incorporados e LoRA (Aprimorado)


: um método de aprendizagem por reforço on-line para o desenvolvimento de consultoria LLM em várias etapas")