 que aproveita conteúdo de vídeo para respostas de consulta envelopadas")
As tecnologias baseadas em vídeo tornaram-se ferramentas importantes para aquisição de informações e compreensão de conceitos complexos. Os vídeos incluem dados visuais, temporais e contextuais, proporcionando uma representação mais visual do que imagens estáticas e texto. Com a crescente popularidade das plataformas de partilha de vídeos e dos vastos repositórios de vídeos educativos e informativos disponíveis na Internet, vídeos eficazes como fontes de informação oferecem oportunidades sem precedentes para responder a questões que requerem contexto detalhado, compreensão espacial e processo representacional.
Os sistemas de produção aumentada, que incluem recuperação e processamento de feedback, muitas vezes ignoram todo o potencial dos dados de vídeo. Esses sistemas geralmente dependem de informações textuais ou ocasionalmente incluem imagens estáticas para apoiar respostas a perguntas. No entanto, eles não conseguem capturar a riqueza dos vídeos, que incluem flexibilidade visual e dicas multimodais que são importantes para tarefas complexas. Os métodos convencionais descrevem os vídeos relacionados à questão sem recuperar ou converter os vídeos em formatos de texto, perdendo informações importantes como contexto visual e dinâmica temporal. Esta inadequação interfere no fornecimento de respostas precisas e informativas a questões do mundo real e multimétodos.
Os métodos atuais exploraram a detecção baseada em texto ou imagem, mas ainda não exploraram totalmente os dados de vídeo. Nos sistemas RAG convencionais, o conteúdo do vídeo é apresentado como legendas ou legendas, focando apenas nos recursos textuais ou reduzido a quadros pré-selecionados para análise do alvo. Ambos os métodos limitam a riqueza multimodal dos vídeos. Além disso, a falta de técnicas de recuperação dinâmica e de integração de vídeo relacionada a consultas limita a eficácia desses sistemas. A falta de integração completa de vídeo deixa uma oportunidade inexplorada para desenvolver um paradigma para geração de recuperação estendida.
Equipes de pesquisa da KaiST e DeepAuto.ai propuseram uma nova estrutura chamada VideoRAG para enfrentar os desafios associados ao uso de dados de vídeo em sistemas de produção com recuperação aumentada. VideoRAG recupera dinamicamente vídeos relacionados a consultas de um grande corpus e integra informações visuais e textuais ao processo de produção. Ele aproveita o poder dos Large Video Language Models (LVLMs) para integração perfeita de dados multimodais. Este método representa uma grande melhoria em relação aos métodos anteriores, garantindo que os vídeos retornados sejam relevantes para as consultas do usuário e mantendo a riqueza temporal do conteúdo do vídeo.
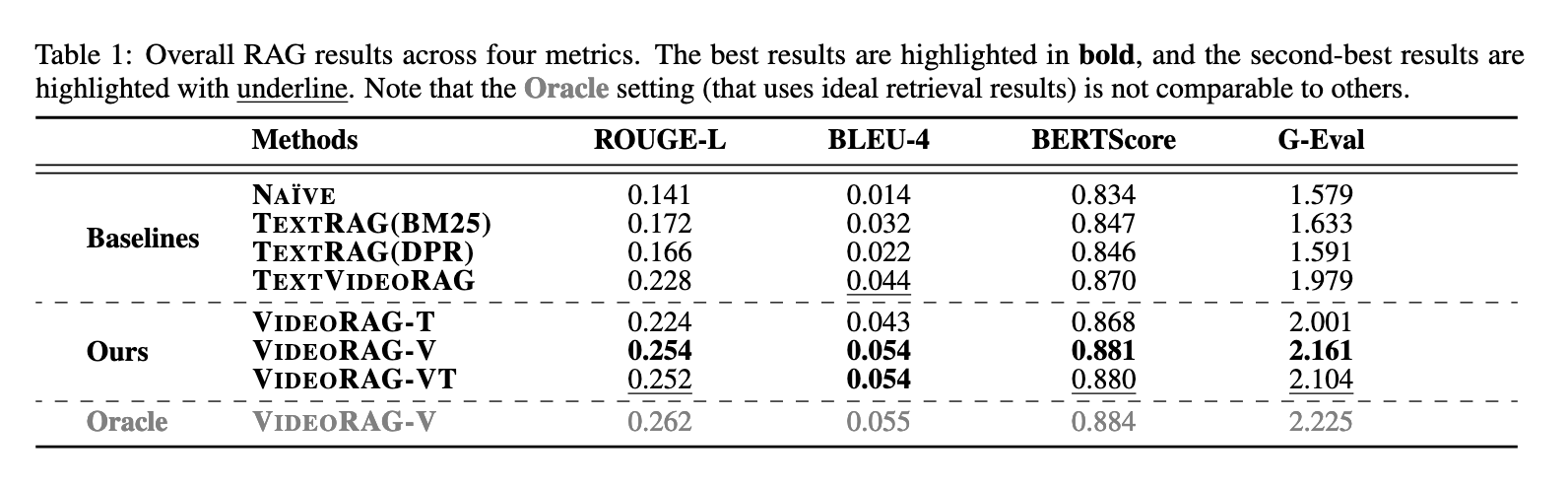
A metodologia proposta envolve duas etapas principais: recuperação e produção. Em seguida, identifica os vídeos por suas características visuais e textuais semelhantes em relação à consulta durante a recuperação. VideoRAG usa reconhecimento automático de fala para gerar dados textuais para vídeo que não estão disponíveis com legendas. Esta seção garante que a geração de respostas a todos os vídeos receba contribuições valiosas de cada vídeo. Os vídeos relevantes retornados são então alimentados no módulo de produção da estrutura, onde são combinados dados multimodais, como frames, legendas e texto de consulta. Essa entrada é totalmente processada em LVLMs, permitindo-lhes produzir respostas longas, ricas, precisas e contextualmente apropriadas. O foco do VideoRAG na integração visual e textual torna possível representar objetos complexos em processos e interações complexas que não podem ser explicadas por métodos estáticos.
VideoRAG foi extensivamente testado em conjuntos de dados como WikiHowQA e HowTo100M. Esses conjuntos de dados incluem uma ampla variedade de perguntas e conteúdo de vídeo. Em particular, o método revela uma melhor qualidade de resposta, de acordo com diversas métricas, como ROUGE-L, BLEU-4 e BERTScore. Portanto, para o método VideoRAG, a pontuação foi de 0,254 de acordo com o ROUGE-L, enquanto para os métodos baseados em texto, o RAG relatou 0,228 como a pontuação mais alta. O mesmo também é mostrado com BLEU-4, sobreposição de n gramas: para VideoRAG; isso é 0,054; com base no texto, era apenas 0,044. A variante da estrutura, que utilizou quadros de vídeo e texto, melhorou ainda mais o desempenho, atingindo um BERTScore de 0,881, em comparação com 0,870 para os métodos de linha de base. Estes resultados destacam a importância da integração multimodal na melhoria da precisão das respostas e sublinham o potencial transformador do VideoRAG.

Os autores demonstraram que a capacidade do VideoRAG de combinar dados visuais e escritos leva a respostas mais ricas e precisas. Comparado aos sistemas RAG tradicionais que dependem apenas de dados textuais ou de imagens estáticas, o VideoRAG é mais eficaz em situações que exigem compreensão espacial e temporal detalhada. Incluir a produção de vídeos assistida por texto sem legendas garante um desempenho consistente em vários conjuntos de dados. Ao permitir a recuperação e o processamento com base no corpus de vídeo, a estrutura aborda as limitações dos métodos existentes e estabelece uma referência para futuros sistemas de recuperação aumentada multimodal.
Resumindo, VideoRAG representa um grande avanço em sistemas avançados de produção de recuperação porque utiliza conteúdo de vídeo para melhorar a qualidade da resposta. Este modelo combina técnicas avançadas de recuperação com o poder dos LVLMs para fornecer respostas ricas e precisas. Funcionalmente, aborda eficazmente as deficiências dos sistemas actuais, proporcionando assim um quadro robusto para incorporar dados de vídeo em canais de produção de informação. Com seu alto desempenho em diversas métricas e conjuntos de dados, o VideoRAG está se mostrando uma nova maneira de incluir vídeos em sistemas de produção estendidos para recuperação.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 Plataforma de IA de código aberto recomendada: 'Parlant é uma estrutura que muda a maneira como os agentes de IA tomam decisões em situações voltadas para o cliente.' (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)


")