
Lançamento de Conjunto de dados FC-AMF-OCR com LightOn representa um marco significativo no reconhecimento óptico de caracteres (OCR) e no aprendizado de máquina. Este conjunto de dados é um avanço técnico e é a base para futuras pesquisas em Inteligência Artificial (IA) e visão computacional. A introdução de tal conjunto de dados abre novas oportunidades para pesquisadores e desenvolvedores, permitindo-lhes desenvolver modelos de OCR, que são essenciais para converter imagens de texto em formatos de texto legíveis por máquina.
Fundo LightOn e conjunto de dados FC-AMF-OCR
A LightOn, uma empresa conhecida por seu papel pioneiro em IA e aprendizado de máquina, tem expandido continuamente os limites da tecnologia. O conjunto de dados FC-AMF-OCR é um de seus projetos mais recentes, projetado para facilitar operações de OCR mais precisas e eficientes. É bem sabido que a tecnologia OCR tem uma ampla gama de aplicações, desde a digitalização de livros impressos até a habilitação do reconhecimento de texto em tempo real em dispositivos do dia a dia. Apesar de muitos avanços, o OCR continua a ser um desafio, especialmente no tratamento de fontes complexas, imagens com ruído e idiomas diferentes.
O conjunto de dados FC-AMF-OCR visa preencher essas lacunas, fornecendo um conjunto grande e diversificado de dados de treinamento. Esses dados ajudam os modelos de IA a aprender e se adaptar a vários desafios relacionados ao reconhecimento de texto. Ao incluir uma extensa lista de fontes, formatos e condições de imagem, LightOn garante que o conjunto de dados seja abrangente o suficiente para resolver muitas das limitações atuais da tecnologia OCR.
Importância do conjunto de dados
O lançamento do conjunto de dados FC-AMF-OCR é muito importante devido ao seu foco em AMF ou Meta-Fontes Amorfas. Essas metafontes são caracterizadas por sua natureza abstrata e fluida, o que pode apresentar grandes desafios aos modelos tradicionais de OCR. Ao integrar essas fontes exclusivas ao conjunto de dados, LightOn incentiva o desenvolvimento de modelos de IA capazes de lidar até mesmo com as tarefas mais complexas de reconhecimento de texto.
A tecnologia OCR desempenha um papel importante em vários campos. Por exemplo, o OCR digitaliza e classifica grandes quantidades de documentos impressos nas indústrias jurídica e médica. Na indústria editorial, permite a conversão de livros físicos em formatos digitais, tornando os livros mais acessíveis a um público global. A precisão da tecnologia OCR pode ter um impacto direto na produtividade e na acessibilidade nestas áreas. O conjunto de dados FC-AMF-OCR permite que os desenvolvedores construam modelos de OCR robustos e versáteis, o que pode melhorar muito esses campos.
Características técnicas do conjunto de dados
As características técnicas do conjunto de dados FC-AMF-OCR demonstram sua flexibilidade e usabilidade para pesquisadores. O banco de dados inclui milhares de imagens, cada uma contendo uma variedade de formatos, desde texto digital limpo e nítido até fontes artísticas e manuscritas mais complexas. A LightOn projetou o conjunto de dados para atender a uma variedade de casos de uso, incluindo reconhecimento de texto em ambientes barulhentos, imagens distorcidas e documentos multilíngues.
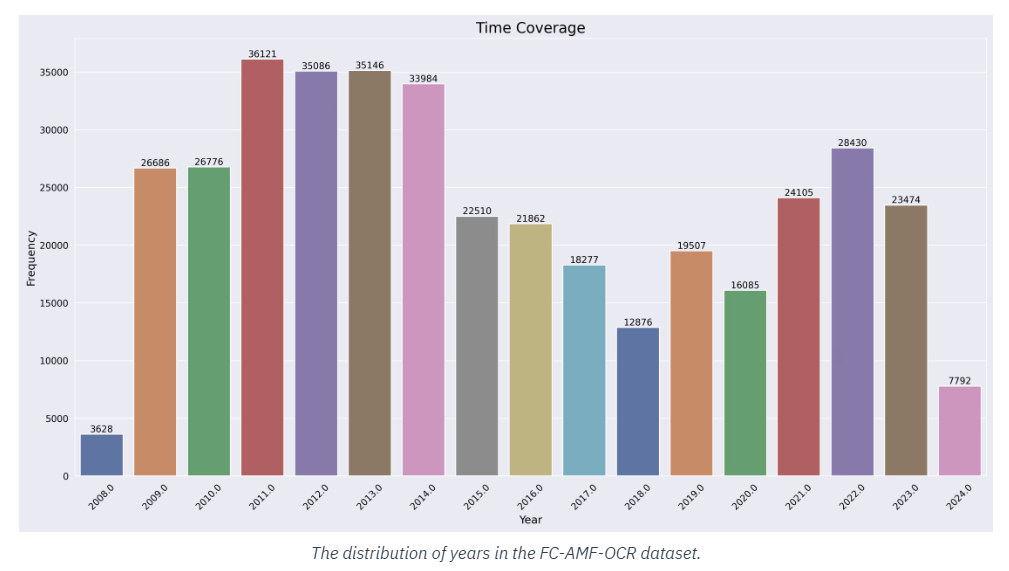
Uma das partes mais importantes do conjunto de dados é a inclusão de Amorphous Meta-Fonts (AMF), que fornece um alto grau de variação nos estilos de texto. Essas fontes raramente são encontradas em conjuntos de dados comuns, tornando o conjunto de dados FC-AMF-OCR único em sua capacidade de treinar modelos de OCR para reconhecer formas de texto menos estruturadas e mais fluidas. Isto é especialmente benéfico para aplicações de IA em indústrias criativas, onde o texto muitas vezes assume uma forma artística ou incomum.
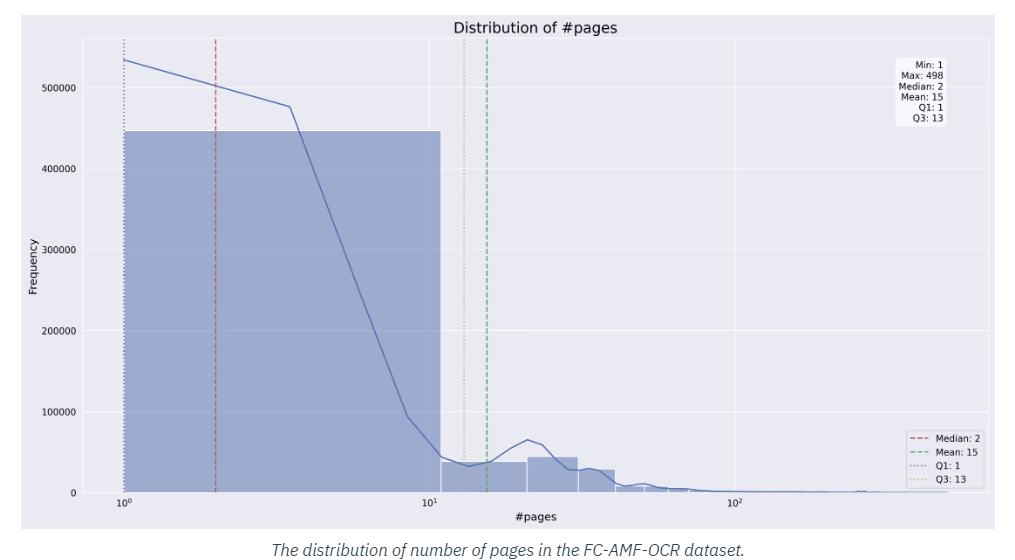
O conjunto de dados foi projetado para ser altamente acessível e facilmente integrado aos fluxos de trabalho de aprendizado de máquina existentes. Os pesquisadores podem baixar e usar o conjunto de dados em seus projetos com o mínimo de atrito, permitindo que se concentrem no desenvolvimento de seus modelos de OCR. O conjunto de dados é compatível com muitas estruturas populares de aprendizado de máquina, incluindo TensorFlow e PyTorch.
Possíveis aplicações
O lançamento do conjunto de dados FC-AMF-OCR tem o potencial de impactar diversos setores e aplicações. Por exemplo, o OCR reconhece sinais de trânsito e outros indicadores baseados em texto em sistemas de condução automatizados. Ao adicionar fontes e critérios complexos ao conjunto de dados FC-AMF-OCR, os desenvolvedores podem melhorar a precisão do reconhecimento de texto nessas áreas, tornando os veículos autônomos mais seguros e confiáveis. Outra área onde os conjuntos de dados podem ter um impacto significativo na acessibilidade dos conteúdos digitais é a tecnologia OCR. A tecnologia OCR torna os materiais impressos acessíveis a pessoas com deficiência visual. Ao melhorar os modelos de OCR com o conjunto de dados FC-AMF-OCR, os desenvolvedores podem construir sistemas de conversão de texto em fala mais precisos que convertem texto impresso em fala audível.
O conjunto de dados também promete melhorar a precisão do reconhecimento de texto em aplicações de realidade aumentada (AR). AR depende fortemente da tecnologia OCR para sobrepor informações digitais em objetos do mundo real. Por exemplo, os aplicativos de AR geralmente exibem traduções ou contexto adicional para texto do ambiente do usuário. A capacidade do conjunto de dados FC-AMF-OCR de lidar com várias fontes e estilos de texto pode melhorar muito a precisão e a confiabilidade desses aplicativos de AR, resultando em uma experiência de usuário perfeita.
Desafios e oportunidades
Embora o conjunto de dados FC-AMF-OCR represente um avanço significativo, ele também destaca os desafios contínuos no campo do OCR. Um dos principais desafios enfrentados pelos pesquisadores é garantir que os modelos de OCR possam acomodar vários estilos e contextos de texto. Embora o conjunto de dados FC-AMF-OCR cubra muitas fontes e termos, novos desafios sempre surgirão à medida que os estilos e formatos de texto mudam. Os pesquisadores devem modificar continuamente seus modelos para lidar eficazmente com estilos textuais novos e emergentes.
Além disso, a complexidade das fontes AMF apresenta um desafio em termos de recursos computacionais. O treinamento de modelos de IA em conjuntos de dados diversos e complexos requer capacidade de processamento e memória significativas. No entanto, este desafio também apresenta uma oportunidade para o desenvolvimento de hardware e infraestrutura de IA. O lançamento do conjunto de dados FC-AMF-OCR pela LightOn também abre a porta para colaboração e inovação. Ao disponibilizar gratuitamente o conjunto de dados para pesquisadores e desenvolvedores, a LightOn incentiva a comunidade mais ampla de IA a participar no desenvolvimento da tecnologia OCR.
A conclusão
O lançamento do conjunto de dados FC-AMF-OCR da LightOn é um marco no desenvolvimento da tecnologia OCR e IA. Ao fornecer um conjunto de dados amplo e diversificado que inclui formas de texto desafiadoras, como meta-fontes amorfas, o LightOn permite que os pesquisadores criem modelos de OCR mais precisos e versáteis. As aplicações potenciais para o conjunto de dados abrangem muitos setores, desde veículos autônomos até acessibilidade digital, tornando-o um recurso importante para futuras pesquisas em IA.
Confira Conjunto de dados e detalhes. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


