
Um dos desafios mais críticos para os LLMs é como alinhar esses modelos com valores e preferências humanísticas, especialmente em textos produzidos. Grande parte da saída de texto gerada pelos modelos é imprecisa, tendenciosa ou potencialmente prejudicial – por exemplo, alucinações. Esta discrepância limita o uso potencial de LLMs em aplicações do mundo real em domínios como educação, saúde e suporte ao cliente. Isto também é agravado pelo facto de o preconceito estar a aumentar nos LLMs; procedimentos de treinamento repetitivos exacerbaram inevitavelmente os problemas de alinhamento, por isso não está claro se o resultado será confiável. Este é um desafio realmente difícil para o dimensionamento e eficácia em larga escala dos processos LLM usados em aplicações do mundo real.
As soluções de alinhamento atuais incluem métodos como RLHF e otimização de preferência direta (DPO). O RLHF treina um modelo de recompensa que recompensa o LLM com aprendizagem por reforço baseada no feedback humano, enquanto o DPO treina o LLM diretamente com pares de preferências anotados e não requer um modelo separado para receber recompensas. Ambos os métodos dependem fortemente de grandes quantidades de dados rotulados por humanos, que são difíceis de medir. Os modelos de linguagem autônoma tentam reduzir essa dependência gerando dados preferenciais sem intervenção humana. Nas SRLMs, um modelo único normalmente serve tanto como modelo de política – que gera respostas – quanto como modelo de recompensa que mede essas respostas. Embora isto tenha tido algum sucesso, a sua principal desvantagem é que tal processo leva a um viés na multiplicação das recompensas. Quanto mais um modelo é treinado dessa forma em seus próprios dados de preferência, mais tendencioso se torna o sistema de recompensa, e isso reduz a confiabilidade dos dados de preferência e degrada o desempenho geral na correspondência.
Devido a essa deficiência, pesquisadores da Universidade da Carolina do Norte, da Universidade Tecnológica de Nanyang, da Universidade Nacional de Cingapura e da Microsoft introduziram o CREAM, que significa Modelos de Linguagem Auto-Recompensadores Regularizados de Consistência. Esta abordagem minimiza os problemas de aumento de preconceitos nos modelos de auto-recompensa, incluindo um termo para habituação para recompensar a consistência entre gerações durante o treino. A ideia é introduzir regularizadores de consistência que avaliem as recompensas geradas pelo modelo a cada iteração sucessiva e usar essa consistência como guia para o processo de treinamento. Ao comparar o nível de respostas da iteração atual com os das iterações anteriores, o CREAM encontra e concentra-se nos dados confiáveis preferidos, evitando a tendência do modelo de aprender demais rótulos ruidosos ou não confiáveis. Este novo processo de normalização reduz o preconceito e também permite que o modelo aprenda de forma mais eficaz e eficiente a partir dos seus próprios dados populares. Esta é uma enorme melhoria em relação aos métodos atuais de interesse próprio.
O CREAM opera dentro de uma estrutura geral de seleção iterativa que se aplica tanto às abordagens de auto-recompensa quanto à RLHF. A normalização de consistência funciona comparando o nível de respostas produzidas pelo modelo em iterações sucessivas. Mais precisamente, a concordância entre os níveis das iterações atuais e anteriores é medida pelo coeficiente Tau de Kendall. Este fator de consistência é então introduzido na função de perda como um termo de normalização, o que incentiva o modelo a confiar mais nos dados preferidos com alta consistência entre as iterações. Além disso, o CREAM tem um bom desempenho para LLMs muito pequenos, como LLaMA-7B, usando conjuntos de dados amplamente disponíveis, como ARC-Easy/Challenge, OpenBookQA, SIQA e GSM8K. Por sua vez, esta abordagem reforça isto ao utilizar um método popular de escalonamento de dados baseado na sua consistência para alcançar um elevado alinhamento sem a necessidade de grandes conjuntos de dados rotulados por humanos.

O CREAM vai além da base em muitas atividades ascendentes, juntamente com o alinhamento e a eliminação de preconceitos de modelos egoístas. Ganhos significativos de precisão usando o método incluem um aumento de 86,78% para 89,52% para ARC-Easy e de 69,50% para 72,06% para SIQA. Essa melhoria consistente na replicação demonstra a capacidade da máquina de se adaptar ao desempenho. Embora os sistemas convencionais de auto-recompensa tendam a ter baixa consistência e alinhamento geral de recompensas, o CREAM supera os modelos existentes, mesmo quando comparado a sistemas que utilizam modelos de recompensa extrínseca de alta qualidade. Isto também manteve melhorias de desempenho sem recorrer a qualquer assistência externa, demonstrando a robustez do modelo na geração de dados de preferências fiáveis. Além disso, este modelo continua a melhorar em termos de precisão e consistência nas métricas de recompensa, demonstrando verdadeiramente a importância da regularidade na redução do preconceito de recompensa e na melhoria da eficiência da auto-recompensa. Estes resultados validam ainda mais o CREAM como uma solução robusta para o problema de alinhamento, fornecendo uma forma escalável e eficiente de desenvolver modelos linguísticos em larga escala.
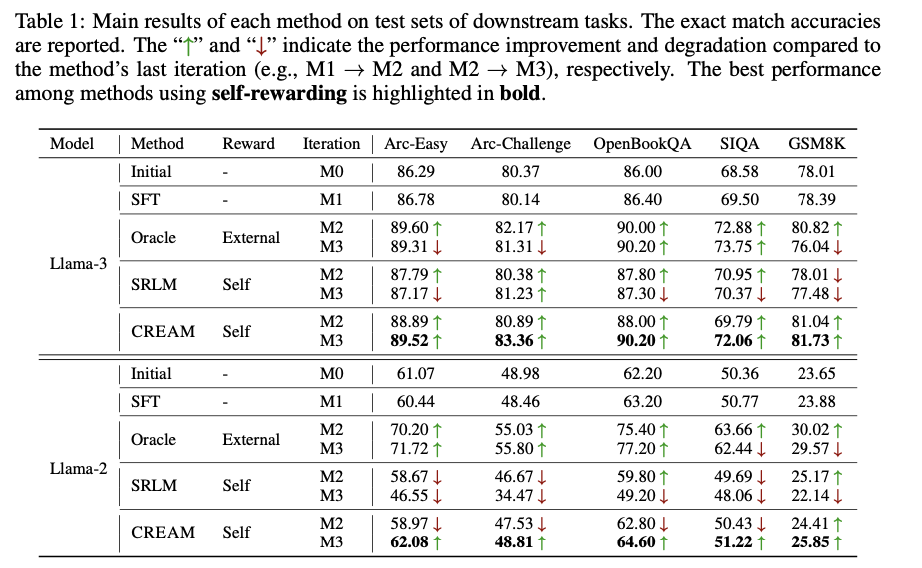
Concluindo, o CREAM fornece uma solução inovadora contra o desafio do viés de recompensa em modelos de linguagem egoístas, introduzindo um método de adaptação consistente. Ao prestar mais atenção a dados de preferências confiáveis e consistentes, o CREAM vê melhorias significativas no alinhamento de desempenho, especialmente em modelos menores como o LLaMA-7B. Embora isto exclua a dependência a longo prazo de dados auto-relatados, esta abordagem representa uma melhoria significativa no desenvolvimento e na eficácia da aprendizagem popular. Isto o posiciona como uma contribuição muito importante para o desenvolvimento contínuo de LLMs em termos de aplicações no mundo real. Os resultados técnicos confirmam fortemente que o CREAM realmente supera os métodos existentes e pode ter um impacto potencial na melhoria da compreensão e confiabilidade nos LLMs.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️

")
