
A geração aumentada de recuperação (RAG) representa um grande avanço na capacidade de modelos linguísticos de grande escala (LLMs) de executar tarefas com precisão, incorporando informações externas relevantes em seu processamento de tarefas. Esta abordagem, que combina técnicas de descoberta de conhecimento com modelagem generativa, tem sido cada vez mais utilizada em aplicações complexas, como tradução automática, resposta a consultas e geração de conteúdo abrangente. Ao incorporar documentos em contextos LLM, o RAG permite que os modelos acessem e utilizem fontes de dados mais amplas e diferenciadas, expandindo efetivamente a capacidade do modelo de lidar com questões especializadas. Este processo provou ser particularmente útil em indústrias que exigem respostas precisas e informativas, proporcionando a capacidade de transformar campos onde a precisão e a especificidade são críticas.
Um grande desafio enfrentado pelo desenvolvimento de modelos de linguagem em larga escala é lidar eficazmente com grandes quantidades de informação contextual. À medida que os LLMs se tornam mais poderosos, aumenta também a necessidade de serem capazes de integrar grandes volumes de dados sem perder a qualidade das suas respostas. No entanto, a incorporação de demasiada informação estranha muitas vezes leva à degradação do desempenho, uma vez que o modelo pode precisar de ajuda para reter informações importantes em instâncias longas. Este problema é agravado em casos de recuperação, onde os modelos devem extrair informações de um extenso banco de dados e combiná-las para produzir resultados significativos. Portanto, preparar LLMs para contextos mais longos é um objetivo de pesquisa importante, especialmente porque as aplicações dependem cada vez mais de interações ricas em dados e de alto volume.
Os métodos RAG mais comuns usam scripts incorporados em um banco de dados vetorial para facilitar a recuperação baseada em similaridade. Esse processo geralmente envolve a divisão de documentos em partes recuperáveis que podem corresponder à consulta de um usuário com base na relevância. Embora este método tenha se mostrado útil para comprimentos de contexto curtos a médios, muitos modelos de código aberto apresentam uma diminuição na precisão à medida que o tamanho do contexto aumenta. Embora alguns modelos mais avançados mostrem uma precisão promissora com até 32.000 tokens, permanecem limitações no uso de comprimentos de contexto ainda maiores para melhorar consistentemente o desempenho, sugerindo a necessidade de métodos mais sofisticados.
Uma equipe de pesquisadores da Databricks Mosaic Research conduziu avaliações abrangentes de desempenho de RAG em LLMs comerciais e de código aberto, incluindo modelos bem conceituados, como GPT-4 da OpenAI, Claude 3.5 da Anthropic e Google Gemini 1.5. Este experimento examinou o impacto do aumento do comprimento do contexto, de 2.000 tokens até 2 milhões de tokens, sem precedentes, para testar como diferentes modelos podem manter a precisão ao lidar com grandes quantidades de informações de contexto. Ao variar o comprimento do contexto em 20 LLMs proeminentes, os pesquisadores tiveram como objetivo identificar quais modelos apresentam desempenho superior em situações de contexto longo, tornando-os mais adequados para aplicações que exigem integração de big data.
O estudo usou uma abordagem consistente entre modelos, incorporando fragmentos de texto usando o grande modelo 3 de incorporação de texto da OpenAI e armazenando esses fragmentos em um armazenamento de vetores. Os testes de pesquisa foram realizados em três conjuntos de dados especializados: Databricks DocsQA, FinanceBench e Natural Queries, cada um escolhido por sua relevância para aplicações RAG do mundo real. Na fase de geração, esses componentes incorporados são então inseridos em uma série de modelos generativos, onde o desempenho é medido com base na capacidade do modelo de gerar respostas precisas às consultas do usuário, combinando as informações retornadas do contexto. Esta abordagem comparou a capacidade de cada modelo de lidar eficazmente com situações ricas em informações.
Os resultados mostraram diferenças significativas no desempenho entre os modelos. Nem todos se beneficiaram igualmente do aumento da duração do contexto, pois o contexto estendido não melhorou consistentemente a precisão do RAG. O estudo descobriu que modelos como o1-mini e o1-preview da OpenAI, GPT-4o, Claude 3.5 Sonnet e Gemini 1.5 Pro mostraram fortes melhorias, mantendo altos níveis de precisão mesmo com 100.000 tokens. No entanto, alguns modelos, especialmente opções de código aberto como Qwen 2 (70B) e Llama 3.1 (405B), apresentaram queda de desempenho acima da marca de 32.000 tokens. Apenas alguns modelos comerciais recentes demonstraram as mesmas capacidades de contexto longo, indicando que, embora a extensão de contexto possa melhorar o desempenho do RAG, muitos modelos ainda enfrentam grandes limitações além de certos limites de token. O mais interessante é que o modelo Gemini 1.5 Pro do Google manteve a precisão nas condições mais longas, lidando com até 2 milhões de tokens com sucesso, um feito incrível que pode ser amplamente visto entre outros modelos testados.
A análise dos padrões de falha dos modelos em condições de contexto longo forneceu insights adicionais. Outros modelos, como o Claude 3 Sonnet, recusaram-se frequentemente a responder devido a preocupações sobre o cumprimento dos direitos de autor, especialmente à medida que a extensão do conteúdo aumentava. Alguns modelos, incluindo o Gemini 1.5 Pro, tiveram dificuldades devido a filtros de segurança muito sensíveis, resultando em recusas repetidas para concluir determinadas tarefas. Os modelos de código aberto também mostraram diferentes padrões de falha; O Llama 3.1, por exemplo, apresentou falhas consistentes em situações acima de 64 mil tokens, muitas vezes renderizando conteúdo irrelevante ou aleatório. Estes resultados enfatizam que os modelos de contexto de longo prazo falham de várias maneiras, especialmente dependendo da duração do contexto e das exigências da tarefa, e sugerem algumas áreas para desenvolvimento futuro.
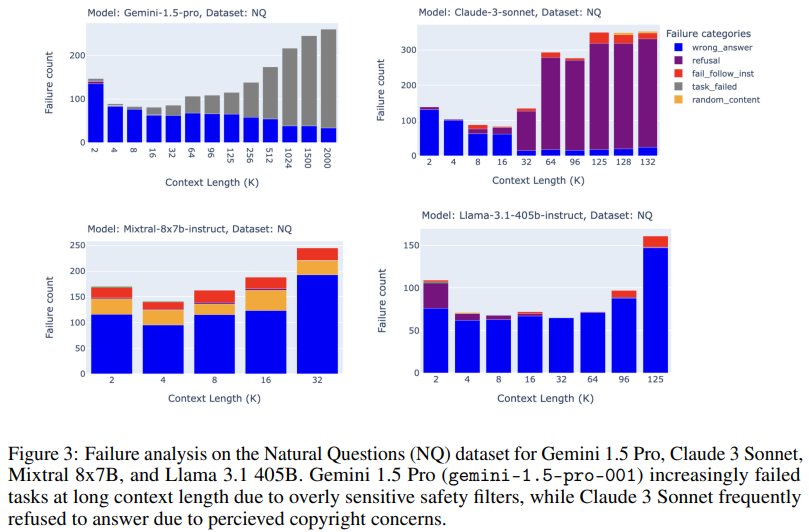
As principais conclusões do estudo revelam os pontos fortes e as limitações do uso de LLMs com um contexto longitudinal para aplicações RAG. Embora alguns modelos de ponta, como o o1 da OpenAI e o Gemini 1.5 Pro do Google, tenham mostrado melhorias consistentes na precisão em longo alcance, a maioria dos modelos só mostrou bom desempenho em curto alcance, em torno de 16.000 a 32.000 tokens. A equipe de pesquisa acredita que modelos avançados como o1 se beneficiam do aumento do tempo de digitalização, o que lhes permite lidar com consultas complexas e evitar confusão com documentos devolvidos menos relevantes. As descobertas da equipe destacam a complexidade das aplicações RAG de contexto de longo prazo e fornecem insights importantes para pesquisadores que buscam refinar essas estratégias.
As principais conclusões do estudo incluem:
- Estabilidade de desempenho: Apenas um grupo seleto de modelos comerciais, como o o1 da OpenAI e o Google Gemini 1.5 Pro, mantiveram desempenho consistente de até 100.000 tokens e mais.
- Downgrades de desempenho em modelos de código aberto: Muitos modelos de código aberto, incluindo Qwen 2 e Llama 3.1, experimentaram uma queda significativa de desempenho acima de 32.000 tokens.
- Padrões de falha: Modelos como o Claude 3 Sonnet e o Gemini 1.5 Pro falharam separadamente, com problemas como a negação do serviço devido a filtros de segurança ou questões de direitos autorais.
- Desafios mais caros: O RAG de contexto longo é mais caro e os custos de processamento variam de US$ 0,16 a US$ 5 por consulta, dependendo do modelo e do comprimento do contexto.
- Necessidades para pesquisas futuras: O estudo sugere mais pesquisas sobre gerenciamento de contexto, gerenciamento de erros e redução de custos em sistemas RAG eficazes.

Concluindo, embora o comprimento estendido do contexto apresente oportunidades interessantes para a recuperação baseada em LLM, persistem limitações práticas. Modelos avançados como o o1 da OpenAI e Gemini 1.5 do Google são promissores, mas a ampla funcionalidade em uma variedade de modelos e casos de uso requer maior desenvolvimento e melhorias direcionadas. Este estudo marca um passo importante na compreensão das vantagens e desvantagens envolvidas no dimensionamento de sistemas RAG em aplicações do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️

 para geração eficiente de dados incorporados em grande escala")
