
A identificação de estratégias de deleção de genes para a produção combinada de crescimento em modelos metabólicos em escala genômica apresenta desafios computacionais significativos. A produção acoplada ao crescimento, que liga o crescimento celular à síntese de metabólitos alvo, é importante para a aplicação da engenharia metabólica. No entanto, encontrar estratégias de deleção genética em grandes modelos impõe uma alta demanda computacional, uma vez que existe um grande espaço de busca combinado com a necessidade de cálculos repetidos para todos os diferentes metabólitos alvo. Estes desafios limitam a robustez e a eficiência dos métodos e a sua aplicabilidade na biotecnologia industrial e na investigação metabólica.
Métodos comumente usados, como o primeiro método baseado em vetor de fluxo, gDel minRN, GDLS e optGene, são eficientes, mas muitas vezes dispendiosos em termos computacionais. A maioria destes métodos não partilha informação entre alvos, porque a maioria deles depende da contagem de novo de todos os metabolitos envolvidos. A redundância aumenta o custo computacional, o que significa que muitos desses métodos apresentam baixa escalabilidade. A taxa de sucesso do GDLS é muito baixa, enquanto o tempo computacional necessário para implementação em escala genômica é muito alto para o optGene.
Para resolver esta ineficiência, investigadores da Universidade de Quioto desenvolveram o DBgDel, uma estrutura baseada em bases de dados para calcular estratégias de eliminação de genes. Aceita informações do banco de dados MetNetComp no cálculo. Funciona em duas etapas principais. Primeiro, ele baixa “genes residuais” com base em múltiplas estratégias de exclusão arquivadas no banco de dados com o propósito de ter um conjunto de genes fixos e, em seguida, usa uma versão melhorada do algoritmo gDel minRN para calcular com sucesso estratégias de exclusão de genes. Reduza a computação redundante e acelere a computação reduzindo o espaço de pesquisa; portanto, fornece uma solução altamente escalonável e eficiente para engenharia metabólica em escala genômica.
A equipe de pesquisa usou três modelos metabólicos com diferentes níveis de complexidade – núcleo de E. coli, iMM904 e iML1515 – usando o banco de dados MetNetComp, que contém mais de 85.000 estratégias de exclusão de genes. Este fluxo de trabalho gera um conjunto reduzido de genes residuais a partir de informações do banco de dados e usa um algoritmo baseado em MILP para refinar estratégias de exclusão. O desempenho foi medido usando uma combinação de taxas de sucesso e tempo de computação comparando DBgDel com ferramentas existentes, como gDel minRN, GDLS e optGene.
DBgDel mostrou melhorias significativas no desempenho estatístico e manteve bom desempenho em todos os modelos testados. Ele mostrou uma aceleração de 6,1 vezes em comparação aos métodos tradicionais. Ele pode identificar estratégias para remover 507 dos 991 metabólitos alvo de modelos grandes, como o iML1515, em menos tempo computacional. A introdução de recursos genéticos iniciais baseados em bancos de dados permitiu uma melhor compreensão da medição e da precisão, fornecendo evidências de sua aplicabilidade em programas de engenharia em escala genômica.
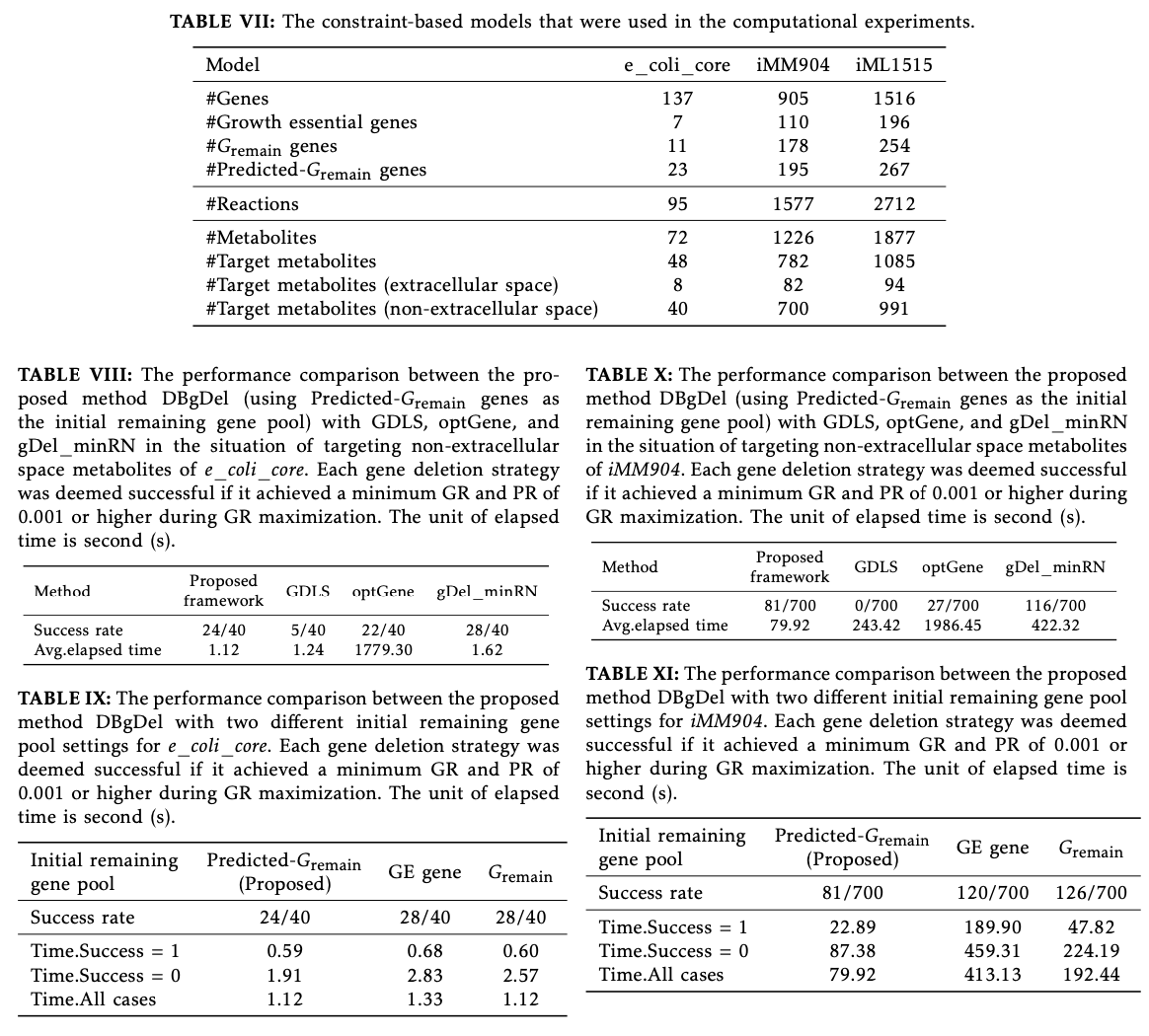
DBgDel oferece uma solução revolucionária para identificar estratégias de exclusão de genes em modelos metabólicos em escala genômica, abordando desafios de longa data em eficiência e robustez computacional. As informações extraídas de bancos de dados resultam em resultados mais rápidos e precisos, com taxas de sucesso comparáveis. Este desenvolvimento abre caminho para a aplicação prática da engenharia metabólica em escala genômica na biotecnologia industrial. Para desenvolver métodos de extração de banco de dados, estes precisarão ser desenvolvidos de diversas maneiras para serem estendidos a uma área de aplicação comum.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias– Da estrutura à produção
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🐝🐝 Evento do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar o modelo de suas equipes – a IA está mudando o jogo, rápido.

: oferece aumento de até 2 a 4x na velocidade de computação e redução de 56% no tamanho do modelo")
