
A Aprendizagem Colaborativa por Reforço Multiagente (MARL) emergiu como uma técnica poderosa em vários domínios, incluindo controle de semáforos, robôs de enxame e redes de sensores. No entanto, o MARL enfrenta desafios significativos devido às complexas interações entre os agentes, que introduzem a não estacionariedade no ambiente. Esta descontinuidade complica o processo de aprendizagem e dificulta a adaptação dos agentes às condições em mudança. Além disso, à medida que o número de agentes aumenta, o dimensionamento torna-se uma questão crítica, exigindo formas eficientes de gerir grandes sistemas multiagentes. Os investigadores estão, portanto, focados no desenvolvimento de estratégias que possam superar estes desafios e, ao mesmo tempo, permitir interações eficazes entre agentes em ambientes dinâmicos e complexos.
Os esforços anteriores para superar os desafios do MAR concentraram-se principalmente em duas categorias principais: abordagens baseadas em políticas e abordagens baseadas em valores. Métodos de gradiente de políticas como MADDPG, COMA, MAAC, MAPPO, FACMAC e HAPPO foram testados para desenvolver estimativas de políticas multiagentes. Abordagens baseadas em valor, como VDN e QMIX, concentram-se na execução de funções de valor global para melhorar a escalabilidade e o desempenho.
Nos últimos anos, a pesquisa sobre métodos de comunicação multiagentes fez avanços significativos. Uma classe de métodos visa limitar a transmissão de mensagens dentro da rede, utilizando métodos de acesso local para reduzir os links de comunicação. Outra seção concentra-se na aprendizagem eficaz para criar mensagens significativas ou extrair informações importantes. Esses métodos usaram uma variedade de técnicas, incluindo métodos de atenção, redes neurais gráficas, modelagem de pares e sistemas personalizados de codificação e decodificação.
No entanto, esses métodos ainda enfrentam desafios na medição da eficiência, robustez e desempenho da comunicação em ambientes multiagentes complexos. Questões como a comunicação superficial, a capacidade limitada de expressar mensagens diferentes e a necessidade de sistemas de mensagens complexos continuam a ser áreas de investigação e desenvolvimento activos.
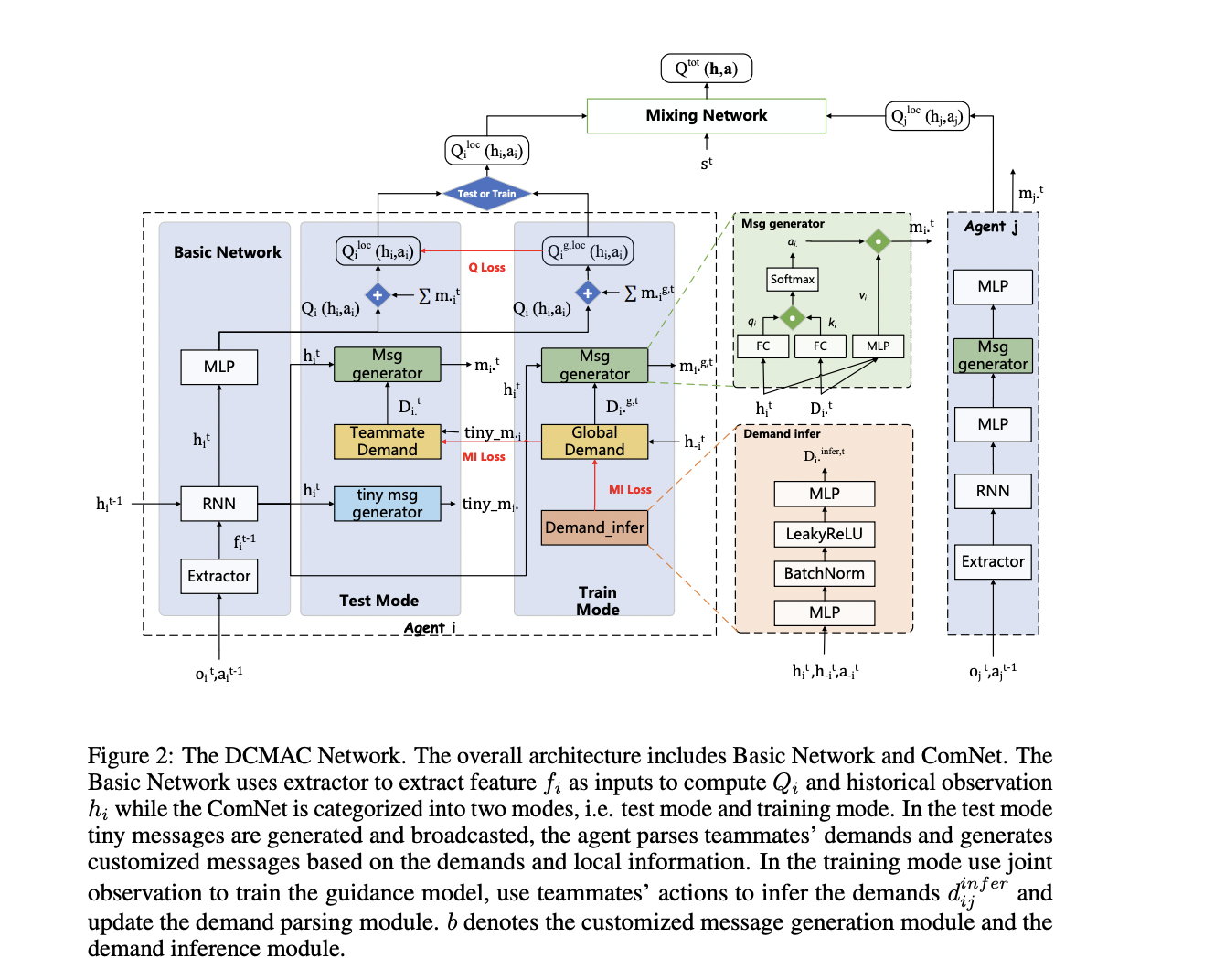
Neste artigo, os pesquisadores apresentam DCMAC (comunicação multiagente personalizada com reconhecimento de demanda)é um protocolo robusto projetado para otimizar o uso de recursos de comunicação limitados, reduzir a incerteza do treinamento e melhorar a interação do agente em sistemas de aprendizagem por reforço multiagentes. Este método de última geração introduz um método único no qual os agentes começam a transmitir mensagens curtas usando pequenos recursos de comunicação. Essas mensagens são então retransmitidas para entender as necessidades do parceiro, permitindo que os agentes gerem mensagens personalizadas que influenciam os valores Q de seus colegas de equipe com base no conhecimento local e nas necessidades percebidas.
DCMAC consiste em um paradigma de treinamento baseado em um limite superior de retorno máximo, que alterna entre Modo Trem e Modo Teste. No Modo Trem, a política ideal é treinada usando observações conjuntas para atuar como um modelo de orientação, ajudando a política-alvo a convergir de forma mais eficaz. O modo de teste usa a função de perda de demanda e erro de diferença de horário para atualizar a transmissão de demanda e os módulos de geração de mensagens personalizadas.
Esta abordagem visa facilitar a comunicação eficaz dentro de recursos limitados, abordando os principais desafios em sistemas multiagentes. O desempenho do DCMAC é demonstrado experimentalmente em vários ambientes, mostrando sua capacidade de atingir desempenho comparável a algoritmos de comunicação irrestrita, sendo ao mesmo tempo mais eficaz em situações com comunicação limitada.
A arquitetura DCMAC consiste em três módulos principais: geração de submensagens, análise de demanda de pares e geração de mensagens personalizadas. O processo começa com os agentes extraindo recursos das observações usando uma abordagem autoatentiva para reduzir informações redundantes. Essas feições são então processadas pelo módulo GRU para obter observações históricas.
O módulo de geração de micromensagens cria mensagens de baixa dimensão baseadas em observações históricas, distribuídas periodicamente. O módulo de transferência de demanda interpreta essas micromensagens para entender as demandas do parceiro. Um módulo de geração de mensagens customizado gera então mensagens que correspondem às tendências nos valores Q de outros agentes, com base em requisitos classificados e observações históricas.
Para melhorar os recursos de comunicação, o DCMAC utiliza uma função de remoção de link que utiliza atenção cruzada para calcular correlações entre agentes. As mensagens são enviadas apenas aos agentes mais apropriados com base nas restrições de comunicação.
O DCMAC apresenta um paradigma de treinamento com alta responsabilidade de retorno, que utiliza políticas apropriadas treinadas em observações conjuntas como modelo orientador. Este método combina um módulo de demanda global e um módulo de inferência de demanda para reproduzir os resultados das observações globais durante o treinamento. O processo de treinamento alterna entre o Modo Trem e o Modo Teste, usando conhecimento compartilhado e erros de TD para melhorar os vários módulos.
O desempenho do DCMAC foi testado em três ambientes de interação multiagentes bem conhecidos: Hallway, Level-Based Foraging (LBF) e StarCraft II Multi-Agent Challenge (SMAC). Os resultados foram comparados com algoritmos básicos como MAIC, NDQ, QMIX e QPLEX.

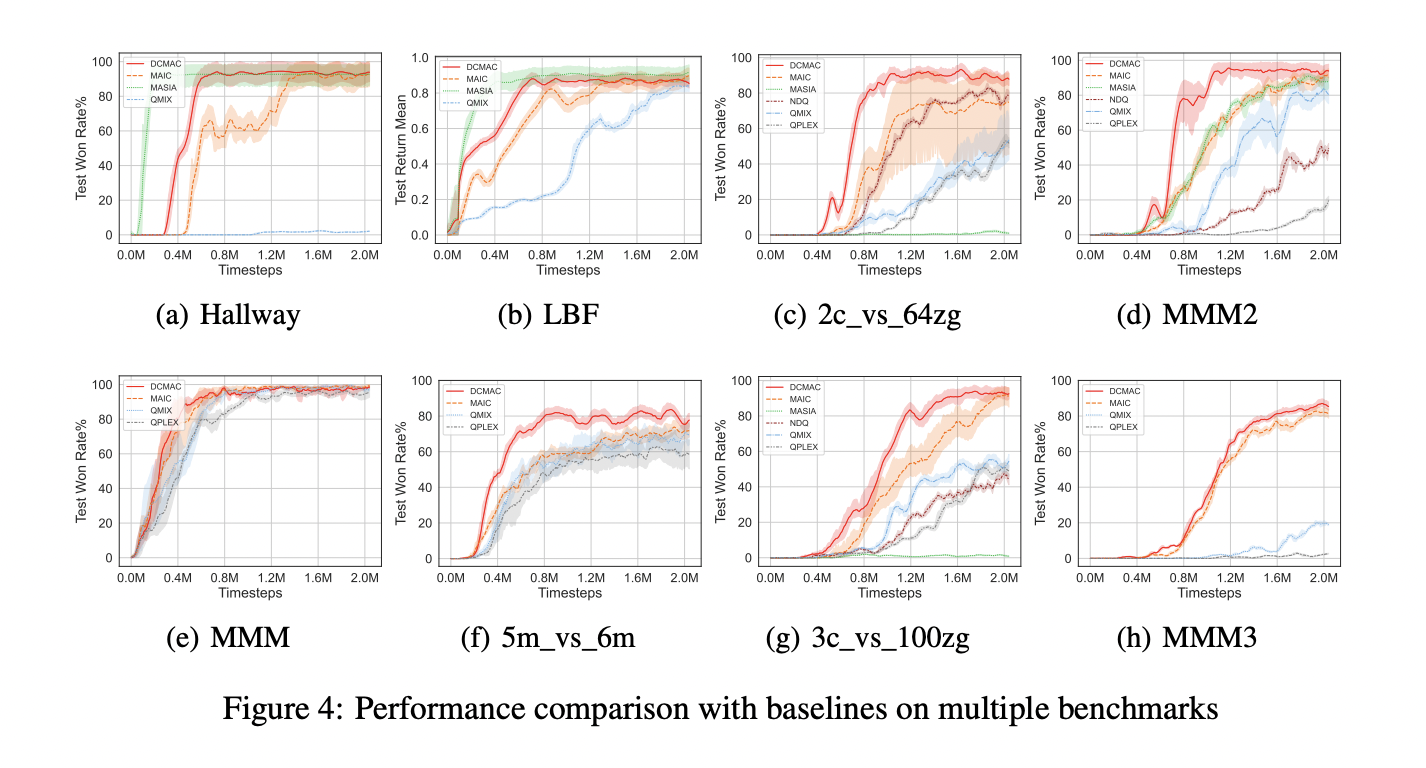
No teste de desempenho de comunicação, o DCMAC apresentou os maiores resultados em casos com grandes espaços de visualização, como o SMAC. Embora tenha tido um desempenho um pouco atrás do MASIA em pequenas áreas de visualização, como Hallway e LBF, ainda melhorou com sucesso a interação do agente. O DCMAC teve um desempenho melhor do que outros algoritmos nos mapas densos e densos do SMAC, indicando sua eficácia em ambientes complexos.
O modelo de orientação DCMAC, baseado em um paradigma de treinamento tendencioso de alto retorno, mostrou excelente convergência e altas taxas de ganho para mapas SMAC fortes e muito fortes. Este trabalho confirmou a eficácia da formação de políticas óptimas utilizando a visualização conjunta e a ajuda do módulo de inferência de procura.
Em situações com restrições de comunicação, o DCMAC manteve alto desempenho sob restrições de comunicação de 95% e superou o MAIC mesmo sob restrições rigorosas. Com uma dificuldade de comunicação de 85%, o DCMAC apresentou uma diminuição significativa, mas obteve taxas de vitória mais altas no Modo Trem.
Este estudo apresenta o DCMAC, que introduz um protocolo de comunicação multiagente com reconhecimento personalizado para melhorar a eficiência do aprendizado multiagente. Supera as limitações dos métodos anteriores, permitindo que os agentes transmitam mensagens menores e isolem as demandas dos parceiros, melhorando a eficiência da comunicação. O DCMAC inclui um modelo de orientação treinado em cognição colaborativa, motivado pelo refinamento da informação, para melhorar o processo de aprendizagem. Testes extensivos em todos os diferentes parâmetros, incluindo condições de comunicação atrasada, mostram a superioridade do DCMAC. O protocolo mostra algum potencial em ambientes complexos e com recursos de comunicação limitados, é mais eficiente do que os métodos existentes e oferece uma solução robusta para colaboração eficaz em diversas e desafiadoras tarefas de aprendizagem por reforço multiagente.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


