
O treinamento de grandes modelos concentra-se em melhorar a eficiência e robustez das redes neurais, especialmente para pré-treinamento de modelos de linguagem com bilhões de parâmetros. A otimização envolve equilibrar recursos de computação, consistência e precisão dos dados. Conseguir isso requer uma compreensão clara das principais métricas, como o tamanho crítico do cluster (CBS), que desempenha um papel importante na otimização do treinamento. Os pesquisadores pretendem descobrir uma maneira de dimensionar os processos de treinamento de forma eficaz, mantendo a eficiência computacional e o desempenho do modelo.
Um dos principais desafios no treinamento de modelos em larga escala é determinar o ponto em que o aumento do tamanho do lote não reduz mais proporcionalmente as etapas de otimização. Esta limitação, conhecida como CBS, requer um ajuste cuidadoso para evitar retornos decrescentes sobre a eficiência. A gestão eficaz destas soluções de compromisso é essencial para permitir uma formação rápida com recursos limitados. Os profissionais sem uma compreensão clara do CBS enfrentam dificuldades em ampliar o treinamento de modelos com estimativas de parâmetros elevados ou grandes conjuntos de dados.
Os estudos existentes examinaram os efeitos do tamanho do cluster no desempenho do modelo, mas muitas vezes se concentram em alcançar perdas mínimas em vez de analisar claramente o CBS. Além disso, muitos métodos exigem a separação das contribuições do tamanho dos dados e do tamanho do modelo para o CBS, dificultando a compreensão de como esses fatores interagem. Os investigadores identificaram lacunas nos métodos anteriores, particularmente a necessidade de um quadro sistemático para estudar a medição da CBS na pré-formação em larga escala. Esta lacuna tem impedido o desenvolvimento de procedimentos de treinamento otimizados para modelos grandes.
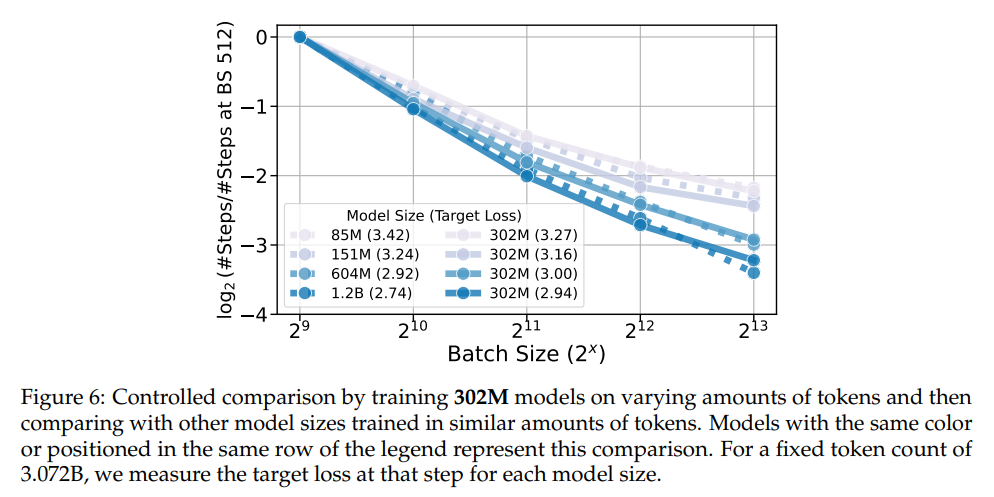
Pesquisas da Universidade de Harvard, da Universidade da Califórnia em Berkeley, da Universidade de Hong Kong e da Amazon abordaram essas lacunas introduzindo um método sistemático para medir CBS em grandes modelos de linguagem independentes, com tamanhos de parâmetros variando de 85 milhões a 1,2 bilhão. O estudo utilizou o conjunto de dados C4 que inclui 3,07 bilhões de tokens. Os pesquisadores conduziram extensos experimentos para isolar os efeitos do tamanho do modelo e do tamanho dos dados no CBS. Leis de escala foram desenvolvidas para medir essas relações, fornecendo informações valiosas sobre variáveis de treinamento em larga escala.
O teste envolve o treinamento de modelos sob condições controladas, com dados ou tamanho do modelo mantidos constantes para isolar seus resultados. Isso revelou que o CBS é mais influenciado pelo tamanho dos dados do que pelo tamanho do modelo. Para refinar suas medições, os pesquisadores incluíram uma varredura de hiperparâmetros para determinar a leitura e os valores de momento. Outra inovação importante foi o uso da média exponencial de peso (EWA), que melhorou o desempenho da otimização e garantiu um desempenho consistente em diversas configurações de treinamento.
Descobertas notáveis incluem que o CBS é dimensionado significativamente com o tamanho dos dados, permitindo maior uniformidade dos dados sem sacrificar a eficiência computacional. Por exemplo, modelos treinados em um número fixo de 3,07 bilhões de tokens mostraram um escalonamento CBS consistente, independentemente do tamanho do parâmetro. O estudo também mostrou que o aumento do tamanho dos dados reduziu significativamente o tempo de treinamento serial, destacando o potencial para melhorar a similaridade em situações com recursos limitados. Os resultados são consistentes com a análise teórica, que inclui insights dos princípios de uma rede neural de domínio infinito.
A investigação desenvolveu conclusões importantes que fornecem orientações práticas para o desenvolvimento de formação em larga escala. Isso é resumido da seguinte forma:
- Regra de tamanho de dados: O CBS é dimensionado principalmente de acordo com o tamanho dos dados, permitindo correspondência eficiente em grandes conjuntos de dados sem degradar a eficiência computacional.
- Diferenças de tamanho do modelo: O aumento do tamanho do modelo tem pouco efeito no CBS, especialmente além de um determinado limite de parâmetro.
- Peso aparente médio: O EWA melhora a consistência e a eficiência do treinamento, superando a programação tradicional de cosseno em cenários de grandes clusters.
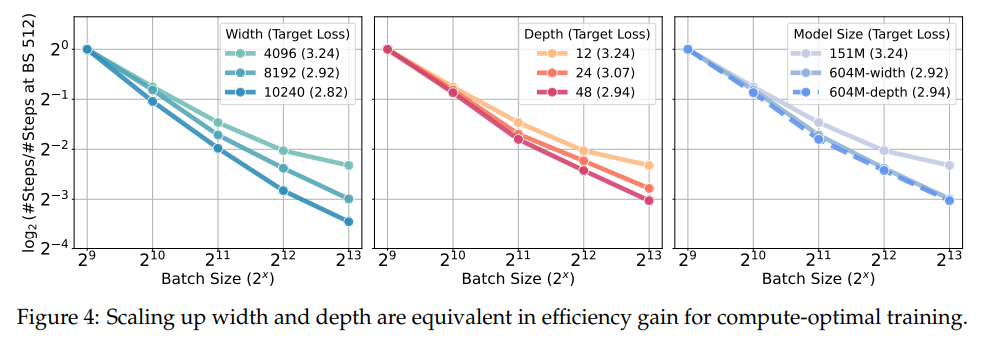
- Técnicas de medição: A amplitude e a profundidade da medição oferecem ganhos iguais em eficiência, proporcionando flexibilidade no design do modelo.
- Ajuste de hiperparâmetros: Ajustes apropriados nas taxas e intensidade de aprendizagem são essenciais para alcançar um CBS ideal, especialmente em situações de excesso e falta de treinamento.

Concluindo, este estudo esclarece os principais fatores que influenciam o treinamento de modelos em larga escala, com o CBS emergindo como uma importante métrica de desempenho. O estudo fornece insights concretos sobre como melhorar a eficiência do treinamento, mostrando que o CBS é dimensionado com o tamanho dos dados e não com o tamanho do modelo. A introdução de novas regras e métodos de escalonamento, como o EWA, garante desempenho prático em situações do mundo real, permitindo aos pesquisadores projetar melhores protocolos de treinamento para conjuntos de dados estendidos e modelos complexos. Essas descobertas abrem caminho para um uso mais eficiente de recursos no campo emergente do aprendizado de máquina.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a intersecção entre IA e soluções da vida real.
🐝🐝 Leia este relatório de pesquisa de IA da Kili Technology 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de métodos de passagem vermelha'


