
Modelos multimodais de grandes linguagens (MLLMs) mostrou resultados promissores em várias tarefas de percepção de linguagem, combinando modelos avançados de linguagem de regressão automática com incorporações visuais. Esses modelos geram respostas usando entrada visual e de texto, com recursos visuais do incorporador de imagem processados antes da incorporação de texto. No entanto, ainda existe uma grande lacuna na compreensão dos mecanismos internos por trás de como essas tarefas multimodais são processadas. A falta de compreensão do funcionamento interno dos MLLMs limita a sua interpretabilidade, reduz a transparência e impede o desenvolvimento de modelos mais eficientes e fiáveis.
Pesquisas anteriores analisaram o funcionamento interno dos MLLMs e como eles se relacionam com o seu comportamento externo. Eles se concentram em áreas como a forma como as informações são armazenadas no modelo, como a distribuição de logs mostra conteúdo indesejado, como as informações virtuais relacionadas aos objetos são identificadas e alteradas, como as medidas de segurança são implementadas e como os tokens virtuais desnecessários são reduzidos. Outros estudos analisaram a forma como estes modelos processam a informação, examinando as relações entre entradas e saídas, as contribuições de vários métodos e seguindo previsões para entradas específicas, muitas vezes tratando os modelos como caixas negras. Outros estudos exploraram conceitos de nível superior, incluindo semântica visual e compreensão de ações. No entanto, os modelos existentes lutam para integrar informações visuais e linguísticas para produzir resultados precisos de forma eficiente.
Para resolver isso, pesquisadores de Universidade de Amsterdã, Universidade de Amsterdã, assim como Universidade Técnica de Munique propuseram um método que analisa a integração de informações visuais e linguísticas dentro de MLLMs. Os pesquisadores estão muito focados auto-regressivo grandes modelos de linguagem multimodal, que incluem um codificador de imagem e um modelo de linguagem somente decodificador. Pesquisadores investigaram a interação de informações visuais e linguísticas em diferentes modelos macrolinguísticos (MLLMs) no tempo a resposta para a questão visual (Controle de Qualidade de Qualidade). Os pesquisadores examinaram como a informação flui entre a imagem e a consulta, bloqueando seletivamente a comunicação entre os dois caminhos em várias estruturas de modelo. Este método, conhecido como atenção, foi usado em diferentes MLMs, incl LLaVA-1.5-7b de novo LLaVA-v1.6-Vicuna-7be testado em diferentes tipos de perguntas no VQA.
Os pesquisadores usaram dados de GQG O conjunto de dados apoia o raciocínio visual e as respostas às questões formuladas e avalia como o modelo processa e integra as informações visuais e escritas. Eles se concentraram em seis áreas de perguntas e aplicaram Nocaute de atenção analisando como o bloqueio da interação entre métodos afetou a capacidade do modelo de prever respostas.
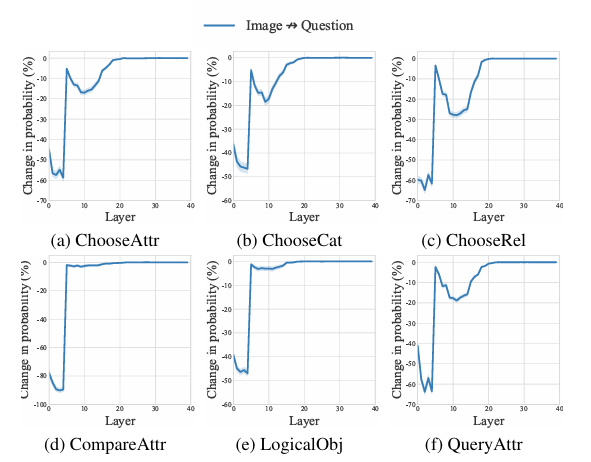
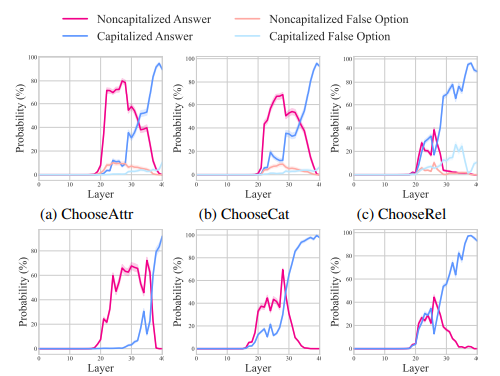
Os resultados mostram que o conhecimento das questões desempenhou um papel direto na previsão final, enquanto o conhecimento das imagens teve um efeito indireto. O estudo também mostrou que o modelo integrou informações da imagem por meio de um processo de duas etapas, com mudanças significativas observadas nas fases inicial e final do modelo.
Em resumo, a abordagem proposta revela que diferentes tarefas multimodais apresentam padrões de processamento semelhantes dentro do modelo. O modelo combina informações de imagem com informações de consulta nas primeiras camadas e as utiliza para previsão final em camadas posteriores. As respostas são produzidas em letras minúsculas e escritas em letras maiúsculas nas camadas superiores. Essas descobertas melhoram a clareza de tais modelos, fornecem novas direções de pesquisa para compreender melhor as interações bidirecionais em MLLMs e podem levar a designs de modelos aprimorados!
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


