
Os modelos linguísticos de grande escala (LLMs) tornaram-se uma parte importante da inteligência artificial, permitindo que os sistemas compreendam, ajam e respondam à linguagem humana. Esses modelos são usados em diversos domínios, incluindo raciocínio em linguagem natural, geração de código e resolução de problemas. Os LLMs são frequentemente treinados com grandes quantidades de dados não estruturados da Internet, permitindo-lhes desenvolver uma ampla compreensão da linguagem. No entanto, é necessário um ajuste fino para ser mais específico sobre a tarefa e alinhar-se com o propósito da pessoa. O ajuste fino envolve o uso de conjuntos de dados de instruções que contêm pares estruturados de consulta-resposta. Este processo é fundamental para melhorar a capacidade dos modelos de funcionarem com precisão em aplicações do mundo real.
A crescente disponibilidade de conjuntos de dados instrucionais apresenta um grande desafio para os pesquisadores: selecionar corretamente um subconjunto do conjunto de dados que otimize o treinamento do modelo sem esgotar os recursos computacionais. Como os conjuntos de dados atingem centenas de milhares de amostras, é difícil decidir qual subconjunto é adequado para treinamento. Este problema é agravado pelo facto de alguns pontos de dados contribuírem mais para o processo de aprendizagem do que outros. É necessário mais do que apenas confiar na qualidade dos dados. Em vez disso, é necessário que haja um equilíbrio entre a qualidade e a diversidade dos dados. Priorizar a diversidade nos dados de treinamento garante que o modelo possa ser adaptado com sucesso a todas as diferentes tarefas, evitando overfitting em determinados domínios.
Os métodos atuais de seleção de dados tendem a focar em aspectos espaciais, como a qualidade dos dados. Por exemplo, os métodos tradicionais tendem a filtrar amostras de baixa qualidade ou eventos duplicados para evitar treinar o modelo nos dados subjacentes. No entanto, esta abordagem muitas vezes ignora a importância da diversidade. A seleção apenas de dados de alta qualidade pode levar a modelos com bom desempenho em determinadas tarefas, mas que precisam de ajuda para uma integração mais ampla. Embora a amostragem qualitativa inicial tenha sido utilizada em estudos anteriores, ela não tem uma visão completa da representação completa do conjunto de dados. Além disso, conjuntos de dados selecionados manualmente ou filtros baseados em qualidade consomem tempo e podem não capturar toda a complexidade dos dados.
Pesquisadores da Northeastern University, Stanford University, Google Research e Cohere For AI apresentaram uma nova abordagem método de desenvolvimento iterativo para superar esses desafios. Sua abordagem enfatiza a seleção central de dados usando k-clustering. Esta abordagem garante que um subconjunto selecionado de dados represente o conjunto de dados completo com mais precisão. Os pesquisadores propõem um processo de filtragem iterativo inspirado em técnicas de aprendizagem ativa, que permite ao modelo reutilizar exemplos de clusters durante o treinamento. Esta abordagem iterativa garante que os clusters que contêm dados de baixa qualidade ou discrepantes sejam gradualmente filtrados, concentrando-se mais em pontos de dados diversos e representativos. O método visa medir a qualidade e a diversidade, garantindo que o modelo não seja enviesado para determinadas categorias de dados.
O método é apresentado amostragem de qualidade k (kMQ). também agrupa pontos de dados em grupos com base na similaridade. O algoritmo então amostra os dados de cada cluster para formar um subconjunto dos dados de treinamento. Cada cluster recebe um peso amostral proporcional ao seu tamanho, que é ajustado durante o treinamento com base em quão bem o modelo aprende com cada cluster. Basicamente, os clusters com dados de alta qualidade são priorizados, enquanto aqueles com baixa qualidade recebem menos importância na próxima iteração. O processo iterativo permite que o modelo melhore seu aprendizado à medida que avança no treinamento, fazendo alterações conforme necessário. Este método se compara aos métodos tradicionais de amostragem fixa, que não consideram o comportamento do modelo durante o treinamento.
A eficácia dessa abordagem foi rigorosamente testada em diversas tarefas, incluindo resposta a perguntas, raciocínio, matemática e codificação. A equipe de pesquisa testou seu modelo em vários conjuntos de dados de referência, como MMLU (resposta a perguntas educacionais), GSM8k (matemática do ensino primário) e HumanEval (geração de código). Os resultados foram significativos: o método de amostragem kMQ levou a uma melhoria de desempenho de 7% em relação à seleção aleatória de dados e a uma melhoria de 3,8% em relação aos métodos de última geração, como Deita e QDIT. Em tarefas como HellaSwag, que testa o raciocínio de bom senso, o modelo alcançou 83,3% de precisão, enquanto para GSM8k, o modelo melhorou de 14,5% para 18,4% de precisão usando o processo iterativo kMQ. Isto mostrou a eficácia da amostra de primeira variedade na melhoria da modelagem de todas as diversas funções.
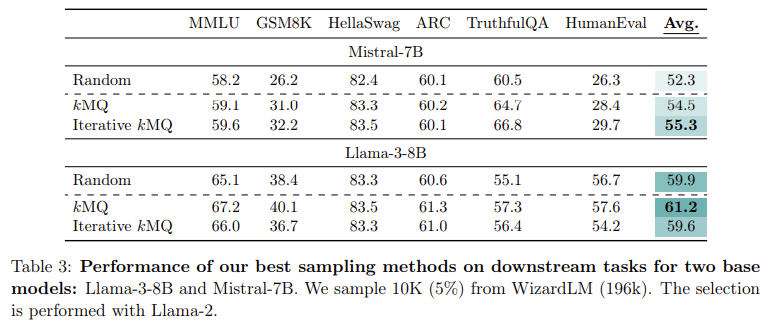
O método dos pesquisadores superou as técnicas anteriores com esses grandes ganhos de desempenho. Ao contrário de processos mais complexos que dependem de grandes modelos de linguagem para localizar e classificar pontos de dados, o kMQ alcança resultados competitivos sem recursos computacionais caros. Usando um algoritmo de clustering simples e otimização iterativa, o processo é escalonável e acessível, tornando-o adequado para uma variedade de modelos e conjuntos de dados. Isso torna o método particularmente útil para pesquisadores que trabalham com recursos limitados e que ainda almejam alcançar alto desempenho na formação de LLMs.

Concluindo, este estudo resolve um dos desafios mais importantes no treinamento de grandes modelos linguísticos: selecionar um subconjunto diversificado e de alta qualidade que maximize o desempenho em todas as tarefas. Ao introduzir uma combinação de médias k e correção iterativa, os pesquisadores desenvolveram um método eficiente que mede a diversidade e a qualidade na seleção de dados. Seu método leva a uma melhoria de desempenho de até 7% e garante que os modelos possam cobrir todas as tarefas multitarefa.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


