
Os métodos de destilação de conhecimento livre de dados (DFKD) transferem conhecimento de professores para modelos de alunos sem dados reais, usando geração de dados artificiais. Os métodos não adversários usam heurística para criar dados semelhantes aos originais, enquanto os métodos adversários usam o aprendizado adversário para explorar pontos de distribuição. O One-Shot Federated Learning (FL) aborda os desafios de comunicação e segurança em uma configuração típica de FL, permitindo o treinamento de modelo colaborativo em uma única rodada de comunicação. No entanto, os métodos convencionais de FL one-shot enfrentam limitações, incluindo a necessidade de conjuntos de dados públicos e o foco em configurações homogêneas de modelo.
Métodos existentes como o DENSE tentam lidar com a diversidade de dados usando DFKD, mas é difícil extrair informações limitadas devido à configuração de um único servidor gerador. Os métodos anteriores, incluindo DENSE e FedFTG, limitaram a cobertura do espaço de treinamento e a eficiência da transferência de conhecimento. Estas limitações destacam a necessidade de novas soluções para melhorar o treinamento de modelos em ambientes colaborativos, especialmente no tratamento da diversidade de modelos e na melhoria da qualidade do processamento de dados sintéticos. O desenvolvimento de abordagens abrangentes, como a abordagem DFDG, visa enfrentar estes desafios e desenvolver o campo da aprendizagem colaborativa.
Uma equipe de pesquisadores da China apresentou o DFDG, um novo método de Aprendizagem Federada que resolve desafios nos métodos existentes. As técnicas atuais baseiam-se frequentemente em conjuntos de dados públicos e geradores individuais, o que limita a cobertura do espaço de formação e impede a robustez do modelo global. O DFDG usa geradores binários treinados arbitrariamente para otimizar o ambiente de treinamento, com foco na confiabilidade, transferibilidade e variação. Introduza uma perda de separação para reduzir a sobreposição da saída do gerador. O método visa superar limitações de privacidade de dados, custos de comunicação e desempenho do modelo em vários cenários de dados de clientes. Testes extensivos em conjuntos de dados de classificação de imagens mostram o desempenho superior do DFDG em comparação com estruturas de última geração, confirmando sua eficácia na melhoria do treinamento de modelos globais em ambientes compactos.
O método DFDG usa geradores binários treinados arbitrariamente para melhorar o aprendizado federado único. Este método explora um espaço de treinamento mais amplo, minimizando a sobreposição de saídas entre geradores. Os geradores são testados quanto à confiabilidade, transferibilidade e variabilidade, o que garante uma representação válida da distribuição espacial dos dados. Uma função de perda de separação é introduzida para reduzir a sobreposição das saídas do gerador, aumentando a cobertura do espaço de treinamento. A metodologia se concentra na geração de dados artificiais que simulam conjuntos de dados locais sem acesso direto, abordando questões de privacidade e melhorando o desempenho do modelo global para vários cenários de clientes.
Os experimentos são realizados em vários conjuntos de dados de classificação de imagens, comparando o DFDG com estruturas de última geração, como FedAvg, FedFTG e DENSE. A configuração simula uma rede centralizada com dez clientes, utilizando o processo Dirichlet para modelar os dados heterogêneos e o orçamento de recursos que é claramente distribuído para refletir a diversidade do modelo. O desempenho é avaliado principalmente usando a precisão do teste global (iG.acc), com testes repetidos em três sementes de confiabilidade. Este extenso projeto experimental valida a eficácia do DFDG no desenvolvimento de aprendizagem combinada única em uma variedade de contextos e distribuições de dados.
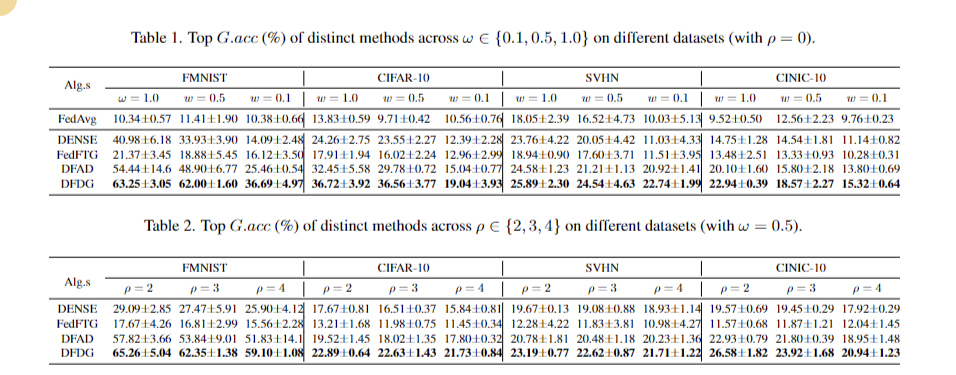
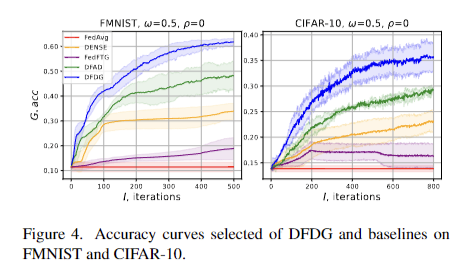
Os resultados experimentais mostram o alto desempenho do DFDG no aprendizado conjunto de uma única imagem em diversas condições de dados e variações de modelo. Com o parâmetro de concentração de heterogeneidade ω variando entre {0,1, 0,5, 1,0} e os parâmetros do modelo de heterogeneidade σ = 2 e ρ entre {2, 3, 4}, o DFDG mais eficaz é contínuo. Alcançou uma melhoria de precisão em relação ao DFAD de 7,74% para FNIST, 3,97% para CIFAR-10, 2,01% para SVHN e 2,59% para CINIC-10. O desempenho do DFDG também foi verificado em tarefas desafiadoras como CIFAR-100, Tiny-ImageNet e FOOD101 com diferentes números de clientes N. Usando a precisão do teste global (iG.acc) como métrica principal, testes repetidos em três caracteres confirmam o capacidade de desenvolvimento -DFDG um. -Aprendizagem integrada para trabalhar em diferentes ambientes.
Concluindo, o DFDG apresenta um novo método de aprendizagem por conjunto sem dados únicos que utiliza geradores duplos para explorar um amplo espaço de treinamento de modelos espaciais. Este método funciona em contra-arranjo com dois geradores e dois estágios de destilação. Ele enfatiza a confiabilidade, transmissão e diversidade do gerador, introduzindo perdas de separação para reduzir a sobreposição da saída do gerador. A fase de destilação de modelo duplo utiliza dados sintéticos de geradores treinados para desenvolver um modelo global. Testes extensivos em diversas tarefas de classificação de imagens mostram a superioridade do DFDG em relação às estruturas de última geração, confirmando ganhos significativos de precisão. O DFDG aborda efetivamente os desafios de privacidade e comunicação de dados, ao mesmo tempo que melhora o desempenho do modelo por meio de treinamento em geração de energia e técnicas de destilação.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)

Shoaib Nazir é estagiário de consultoria na MarktechPost e concluiu dois cursos de M.Tech no Instituto Indiano de Tecnologia (IIT), Kharagpur. Com uma forte paixão pela Ciência de Dados, está particularmente interessado nas diversas aplicações da inteligência artificial em vários domínios. Shoaib é movido pelo desejo de explorar os mais recentes desenvolvimentos tecnológicos e suas implicações práticas na vida cotidiana. Sua paixão pela inovação e pela solução de problemas do mundo real alimenta seu aprendizado e envolvimento contínuos no campo da IA.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
 ajustado a partir do PaLM-2 para prever múltiplas propriedades de negócios relevantes para o desenvolvimento terapêutico")

