: um modelo de difusão para produção eficaz de vídeo por meio da reutilização de movimento")
Usando modelos avançados de inteligência artificial, a produção de vídeo envolve a criação de imagens em movimento a partir de descrições de texto ou imagens estáticas. Esta área de pesquisa busca produzir vídeos realistas e de alta qualidade, superando grandes desafios computacionais. Os vídeos gerados por IA estão encontrando aplicações em diversos campos, como cinema, educação e simulação de vídeo, fornecendo uma maneira eficiente de automatizar a produção de vídeo. No entanto, as exigências computacionais para a produção de vídeos longos e consistentes continuam a ser um obstáculo significativo, levando os investigadores a desenvolver métodos que meçam a qualidade e a eficiência na produção de vídeos.
Um grande problema na produção de vídeo é o alto custo computacional associado à criação de cada quadro. O processo iterativo de extração de ruído, onde o ruído é gradualmente removido da representação subjacente até que a qualidade visual desejada seja alcançada, é demorado. Esse processo deve ser repetido para cada quadro do vídeo, tornando proibitivos o tempo e os recursos necessários para produzir vídeos de alta resolução ou de longa duração. O desafio, portanto, é melhorar esse processo sem sacrificar a qualidade e a consistência do conteúdo do vídeo.
Métodos existentes, como Modelos Probabilísticos de Difusão com Denoising (DDPMs) e Modelos de Difusão de Vídeo (VDMs), produziram com sucesso vídeos de alta qualidade. Esses modelos refinam os quadros de vídeo com etapas de separação de ruído, produzindo visualizações detalhadas e coerentes. No entanto, cada quadro passa por um processo completo de remoção de ruído, o que aumenta as demandas computacionais. Soluções como a comutação oculta tentam reutilizar recursos ocultos em todos os quadros, mas ainda precisam ser melhoradas em termos de eficiência. Esses métodos lutam para produzir vídeos de longo prazo ou de alta resolução sem uma grande quantidade de poder computacional, criando a necessidade de métodos mais eficientes.
A equipe de pesquisa introduziu a rede Diffusion Reuse Motion (Dr. Mo) para resolver as ineficiências dos modelos atuais de produção de vídeo. Dr. Mo reduz a carga computacional aplicando manipulação de movimento a cada quadro de vídeo consecutivo. Os pesquisadores observaram que os padrões sonoros permaneceram os mesmos na maioria dos quadros nos estágios iniciais do processo de extração de áudio. Dr. Mo usa essa consistência para espalhar o som áspero de um quadro para o outro, eliminando estatísticas indesejadas. Além disso, o Denoising Step Selector (DSS), uma meta-rede, determina automaticamente a etapa apropriada desde a propagação do movimento até a oposição normal, melhorando o processo de produção.
Em detalhes, o Dr. Mo constrói matrizes de movimento para capturar aspectos do movimento semântico entre quadros. Essas matrizes são construídas a partir de recursos latentes extraídos por um decodificador como o U-Net, que analisa o movimento entre quadros de vídeo sucessivos. O DSS então avalia quais medidas de extração de ruído podem reutilizar estimativas baseadas em movimento, em vez de recalcular cada quadro do zero. Este método permite ao programa medir a eficiência e a qualidade do vídeo. Dr. Mo reutiliza padrões sonoros para acelerar o processo nos estágios iniciais de extração de som. À medida que a produção do vídeo chega ao fim, mais detalhes são retornados com um modelo de distribuição normal, o que garante alta qualidade visual. O resultado é um sistema rápido que gera quadros de vídeo mantendo clareza e realismo.
A equipe de pesquisa examinou o desempenho do Dr. Mo em conjuntos de dados bem conhecidos, como UCF-101 e MSR-VTT. Os resultados mostraram que o Dr. Mo não apenas reduziu o tempo de cálculo, mas também manteve alta qualidade de vídeo. Ao produzir vídeos com 16 frames e resolução de 256×256, o Dr. Mo alcançou uma melhoria de velocidade quatro vezes maior em comparação com o Latent-Shift, completando a tarefa em apenas 6,57 segundos, enquanto o Latent-Shift exigiu 23,4 segundos. Em vídeos com resolução de 512×512, o Dr. Mo foi 1,5 vezes mais rápido que modelos concorrentes como SimDA e LaVie, produzindo vídeos em 23,62 segundos em comparação com 34,2 segundos do SimDA. Além dessa aceleração, o Dr. Mo manteve uma pontuação inicial (IS) de 96% e até melhorou a pontuação Fréchet Video Distance (FVD), indicando que produziu vídeos visualmente atraentes que correspondiam de perto à realidade.
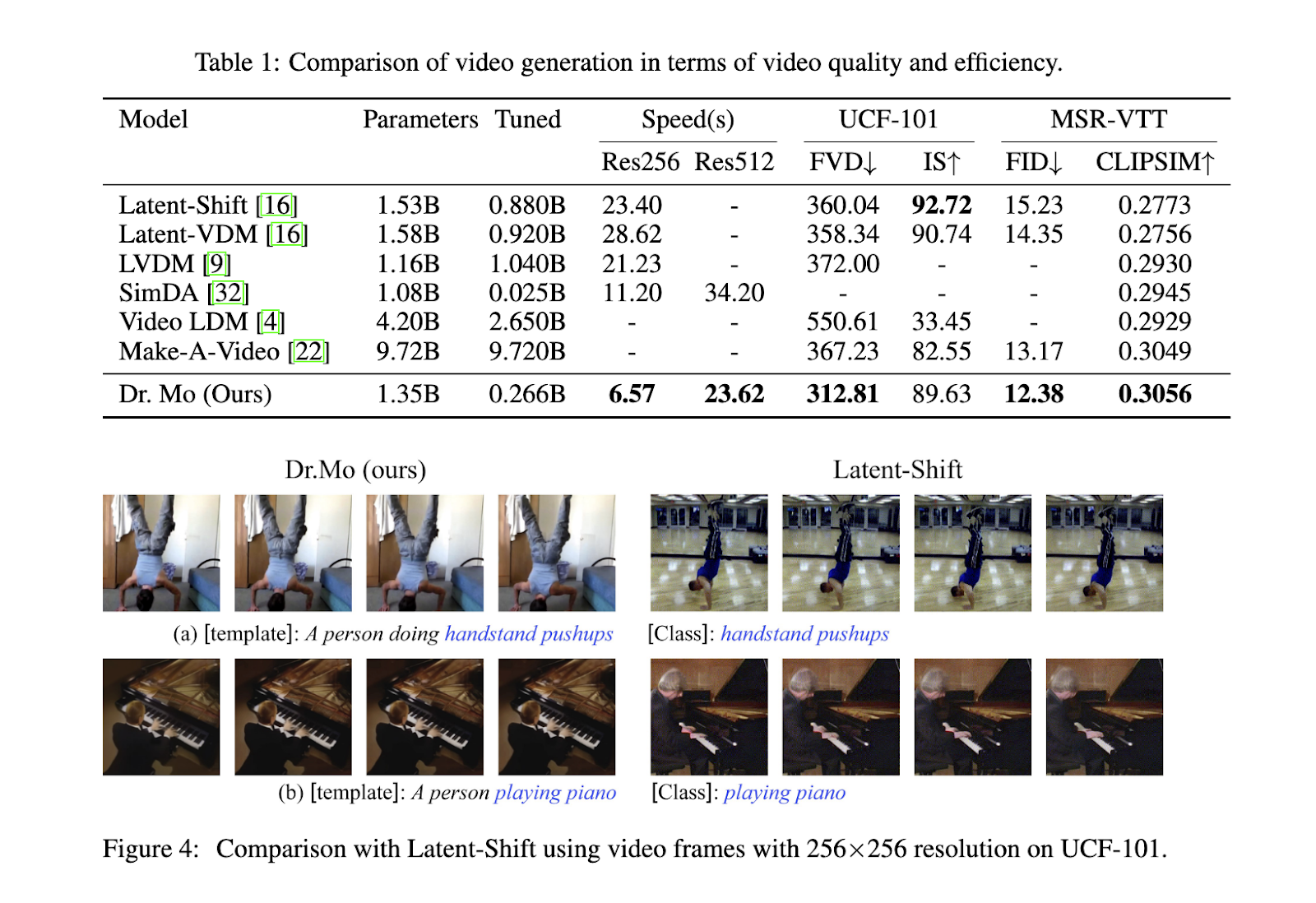
As métricas de qualidade de vídeo destacam ainda mais o trabalho do Dr. No conjunto de dados UCF-101, o Dr. Mo obteve um FVD de 312,81, superando Latent-Shift, que teve uma pontuação de 360,04. Dr. Mo obteve pontuação de 0,3056 para a métrica CLIPSIM no conjunto de dados MSR-VTT, uma medida de alinhamento semântico entre quadros de vídeo e entrada de texto. Este resultado superou todos os modelos testados, mostrando seu alto desempenho em tarefas de produção de texto para vídeo. Além disso, o Dr. Mo é excelente em programas de transferência de estilo, onde as informações de movimento de vídeos do mundo real são aplicadas aos primeiros quadros da transferência de estilo, produzindo resultados consistentes e realistas para cada quadro produzido.
Concluindo, o Dr. Mo proporciona um avanço significativo no campo da produção de vídeo, fornecendo um método que reduz drasticamente as demandas de computação sem comprometer a qualidade do vídeo. Ao reciclar de forma inteligente as informações de movimento e usar um seletor de etapas de eliminação de ruído variável, o sistema produz vídeos de alta qualidade em menos tempo. Este equilíbrio entre eficiência e qualidade marca um importante passo em frente na resolução dos desafios associados à produção de vídeo.
Confira Papel de novo O projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


 com preservação profunda da privacidade")