
Atacar inimigos e defender LLMs envolve uma variedade de táticas e estratégias. Os métodos de integração vermelha autoprojetados e automatizados revelam vulnerabilidade, enquanto o acesso à caixa branca revela o potencial para ataques de pré-preenchimento. Os mecanismos de defesa incluem RLHF, DPO, otimização rápida e treinamento inimigo. As defesas do tempo de inferência e a engenharia representacional mostram-se promissoras, mas enfrentam limitações. A base vetorial de controle melhora a resistência do LLM alterando as representações do modelo. Estes estudos, em conjunto, formam a base para o desenvolvimento de contramedidas, destinadas a melhorar a compreensão e a resiliência do sistema de IA contra ameaças cada vez mais complexas.
Pesquisadores da Gray Swan AI, da Carnegie Mellon University e do Center for AI Security desenvolveram um conjunto de métodos para melhorar a segurança e a robustez dos sistemas de IA. O treinamento de rejeição visa ensinar modelos a rejeitar conteúdo inseguro, mas permanecer vulneráveis a ataques sofisticados. O treino do inimigo melhora a resiliência face a ameaças específicas, mas não é generalizável e incorre em elevados custos computacionais. As defesas em tempo real, como filtros de ofuscação, fornecem proteção contra ataques estáticos, mas são difíceis com aplicações em tempo real devido aos requisitos de computação.
Os métodos de controle representacional concentram-se no monitoramento e gerenciamento de representações de modelos internos, proporcionando uma abordagem mais familiar e eficiente. As Sondas de Nocividade avaliam os resultados detectando representações prejudiciais, o que reduz bastante as taxas de sucesso de ataques. O novo processo de disjuntores interrompe a produção de saídas perigosas controlando os processos dos modelos internos, proporcionando uma solução eficaz para problemas de segurança. Estes métodos avançados abordam as limitações dos métodos convencionais, o que pode levar a sistemas de IA mais robustos e coordenados, capazes de resistir a ataques adversários sofisticados.
A abordagem do disjuntor melhora a segurança do modelo de IA por meio de intervenções direcionadas no núcleo do modelo de linguagem. Inclui configurações precisas de parâmetros, com foco em camadas específicas da aplicação de perdas. Um conjunto de dados de pares texto-imagem maliciosos e inofensivos facilita os testes de robustez. Análise de ativação usando passes diretos e direções de controle de saída do modelo extraído por PCA. Teoricamente, estas diretivas modificam a saída da camada para evitar a geração de conteúdo prejudicial. Os testes de robustez utilizam informações de segurança e categorizam os resultados com base nas condições do MM-SafetyBench. O método se estende aos agentes de IA, que demonstram ações de risco reduzido sob ataque. Esta abordagem abrangente representa um grande avanço na segurança da IA, abordando os riscos numa vasta gama de aplicações.
Os resultados mostram que os disjuntores, baseados na Engenharia de Representação, melhoram significativamente a segurança e a resiliência do modelo de IA contra ataques invisíveis de oponentes. Os testes usando 133 pares de texto-imagem maliciosos do HarmBench e MM-SafetyBench revelam maior robustez, mantendo o desempenho em benchmarks como MT-Bench e OpenLLM Leaderboard. Os modelos com disjuntores apresentam melhor desempenho do que as fundações sob ataques de PGD, reduzindo efetivamente os efeitos nocivos sem sacrificar a utilidade. Este método mostra completude e eficiência em todos os modelos somente texto e em diversos tipos, resistindo a diversas situações conflitantes. O desempenho em benchmarks multimodais como LLaVA-Wild e MMMU permanece forte, refletindo a versatilidade dos métodos. Ainda são necessárias mais investigações sobre o desempenho sob diferentes tipos de ataque e a resiliência contra mudanças na distribuição das fases da lesão.
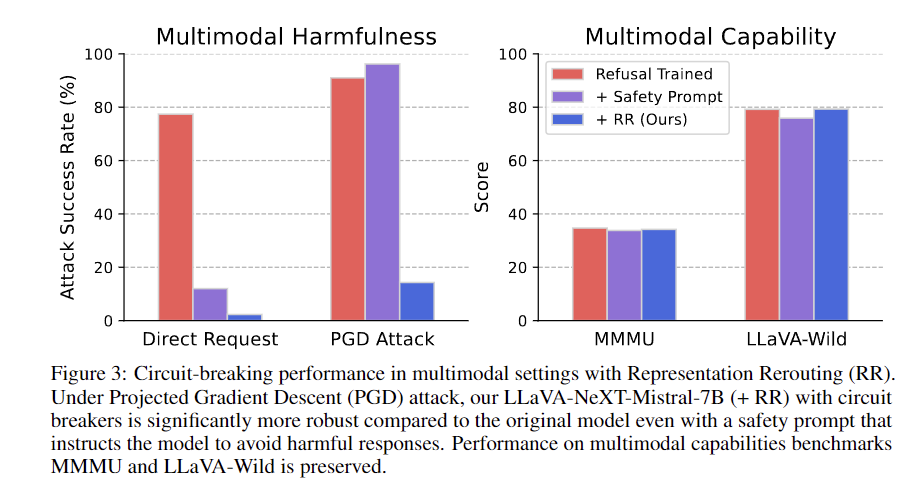
Concluindo, o método do disjuntor lida de forma eficaz com os ataques de adversários que produzem conteúdo malicioso, melhorando a segurança do modelo e o alinhamento. Essa abordagem melhora significativamente a robustez contra ataques invisíveis, reduzindo a conformidade de aplicativos maliciosos em 87 a 90% em todos os modelos. A estratégia mostra forte generalização e potencial para uso em sistemas multimodais. Embora promissores, são necessárias mais pesquisas para testar considerações adicionais de design e melhorar a robustez contra vários cenários conflitantes. A metodologia representa um progresso significativo no desenvolvimento de defesas confiáveis contra comportamentos maliciosos de IA, equilibrando segurança e utilidade. Esta abordagem marca um passo importante na criação de modelos de IA altamente alinhados e robustos.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!

Shoaib Nazir é estagiário de consultoria na MarktechPost e concluiu seus dois diplomas de M.Tech no Instituto Indiano de Tecnologia (IIT), Kharagpur. Com uma forte paixão pela Ciência de Dados, está particularmente interessado nas diversas aplicações da inteligência artificial em vários domínios. Shoaib é movido pelo desejo de explorar os mais recentes desenvolvimentos tecnológicos e suas implicações práticas na vida cotidiana. Sua paixão pela inovação e pela solução de problemas do mundo real alimenta seu aprendizado e envolvimento contínuos no campo da IA.

: uma abordagem de IA para melhorar a adaptabilidade e a eficiência dos agentes de navegação na Web")
