
Principais modelos de linguagem (LLMs) visa alinhar-se com as preferências das pessoas, para garantir uma tomada de decisão confiável e confiável. No entanto, estes modelos sofrem preconceitos, saltos lógicos e ilusões, o que os torna inválidos e inofensivos para tarefas críticas que envolvem raciocínio lógico. Problemas de consistência lógica tornam impossível construir LLMs logicamente consistentes. Eles também usam pensamento ad hoc, otimização e sistemas automáticos, levando a conclusões menos confiáveis.
Os métodos atuais de alinhamento de Grandes Modelos de Linguagem (LLMs) e preferências humanas dependem deles treinamento supervisionado com dados seguindo instruções e aprendizado reforçado com feedback humano. No entanto, estes métodos sofrem de problemas como omissões, preconceitos e inconsistências lógicas, minando assim a validade dos LLMs. Grande parte do desenvolvimento da consistência do LLM foi, portanto, feito com base no simples conhecimento factual ou na simples inclusão em apenas algumas declarações, ignorando outras situações ou tarefas de tomada de decisão mais complexas que envolvem mais de um fator. Esta lacuna limita a sua capacidade de fornecer raciocínio consistente e confiável em aplicações do mundo real onde a consistência é crítica.
Para examinar a consistência lógica em grandes modelos linguísticos (LLMs), pesquisadores de na Universidade de Cambridge de novo Universidade Monash propôs uma estrutura global para medir o consenso racional, avaliando três fatores principais: caminhar, andando por aíde novo a imutabilidade da negação. A transitividade garante que se o modelo determinar que um item é preferido ao segundo e o segundo ao terceiro, ele também conclui que o primeiro item é preferido ao terceiro. A comutatividade garantiu que o julgamento do modelo permanecesse o mesmo independentemente de como os objetos fossem comparados.
Ao mesmo tempo, a incompatibilidade e a incompatibilidade foram examinadas quanto à compatibilidade no tratamento da oposição no relacionamento. Essas propriedades formam a base para um raciocínio confiável em modelos. Os pesquisadores formalizaram o processo de avaliação tratando o LLM como uma atividade do usuário FFF que comparou pares de objetos e atribuiu decisões sobre relacionamentos. A consistência lógica foi medida usando métricas semelhantes stran(K)s_{tran}(K)stran(K) para caminhar de novo scomms_{comm}scommde andando por aí. Stran (K)s_{tran}(K)stran(K) transitividade quantificada tomando subconjuntos de amostras de objetos e encontrando ciclos no gráfico de correlação. Ao mesmo tempo, scomms_{comm}scomm testaram se as conclusões do modelo permaneceram estáveis quando a ordem dos fatores comparados foi alterada. Ambas as métricas variam de 0 a 1com valores mais altos indicando melhor desempenho.
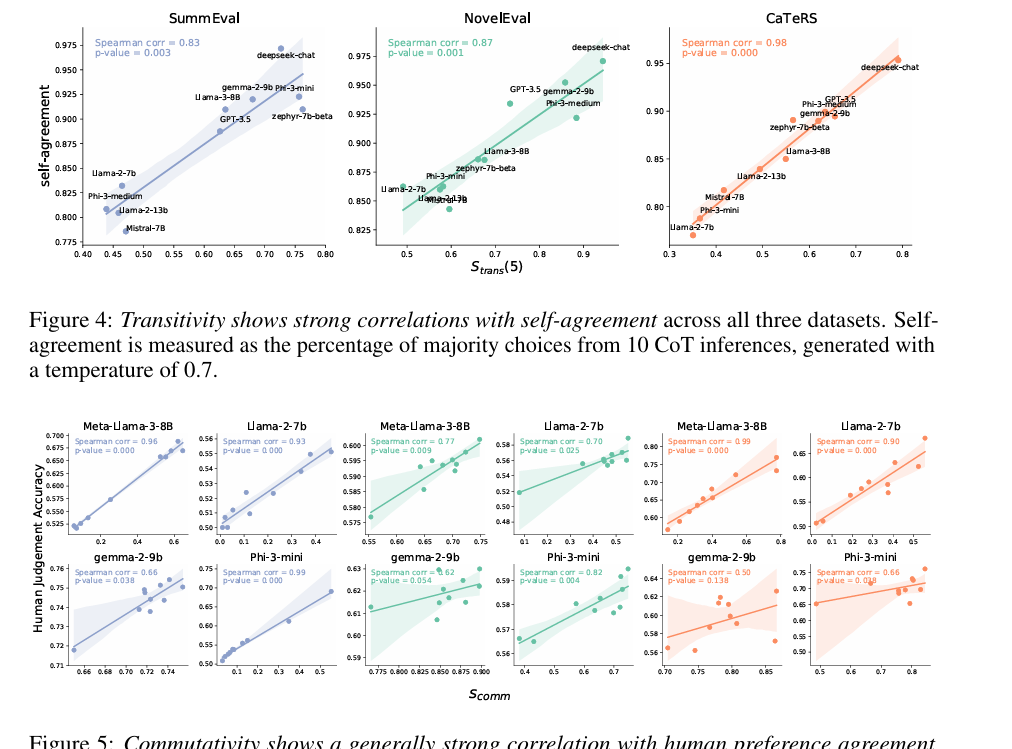
Os pesquisadores aplicaram essas métricas a vários LLMs, revelando vulnerabilidade a preconceitos como favoritismo e preconceito de posição. Para resolver isso, eles apresentaram um método de otimização de dados e métodos aditivos usando métodos de soma de classificação para estimar classificações de preferência parciais ou ordenadas a partir de comparações com ruído ou poucas comparações de pares. Isto melhorou a consistência lógica sem comprometer o alinhamento com as preferências humanas e enfatizou o importante papel da consistência lógica na melhoria do desempenho de um algoritmo baseado em lógica.
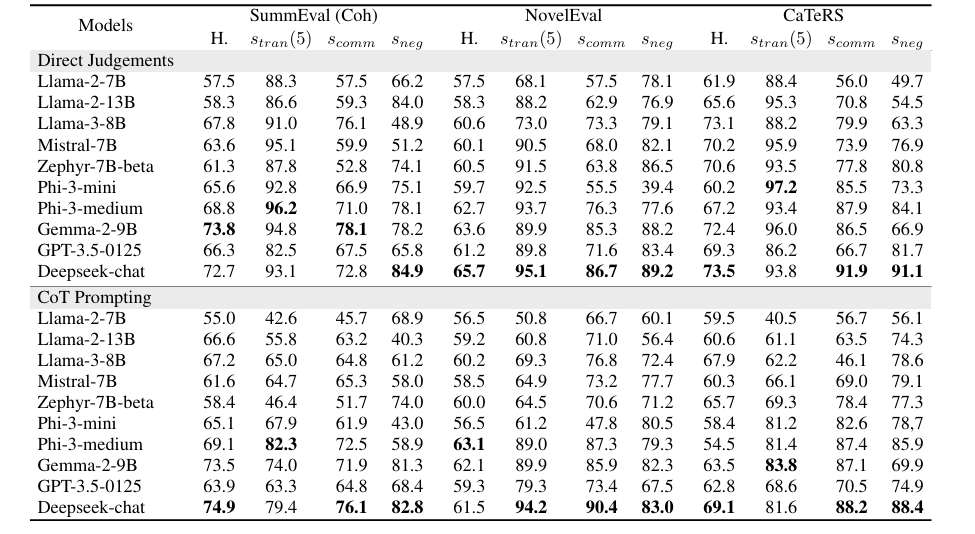
Os pesquisadores testaram três tarefas para avaliar a consistência lógica em LLMs: resumo abstrato, reorganização de documentos, de novo ordem de evento temporal usando conjuntos de dados como Avaliação de soma, NovelaEvalde novo ATENDIMENTOS. Eles examinaram flexibilidade, flexibilidade, consistência de negação e acordo e compromisso pessoal. Os resultados mostraram que os novos modelos gostaram Bate-papo Deepseek, Phi-3-médio, de novo Gema-2-9B teve uma concordância razoável elevada, embora isto não estivesse significativamente relacionado com a precisão da concordância da pessoa. EU ATENDIMENTOS O conjunto de dados apresentou forte consistência, com foco nas relações temporais e causais. A introdução de cadeias de pensamento teve resultados mistos, às vezes reduzindo a probabilidade de ocorrências devido aos tokens de pensamento adicionados. A própria adaptação estava relacionada à mobilidade; isso mostra que o raciocínio consistente é a base da consistência lógica, e modelos como Phi-3-medium e Gemma-2-9B têm confiabilidade igual para cada tarefa, enfatizando a necessidade de dados de treinamento limpos.
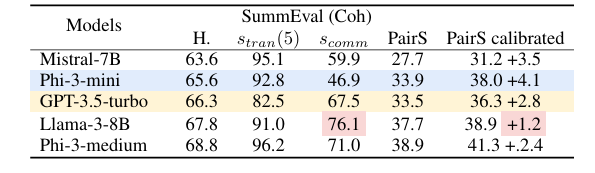
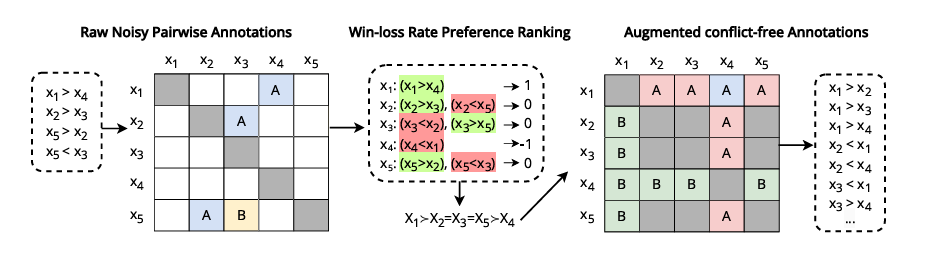
Finalmente, os investigadores demonstraram a importância da consistência lógica na melhoria da fiabilidade de grandes modelos linguísticos. Eles apresentaram um método para quantificar aspectos importantes de consistência e descreveram um processo de limpeza de dados que reduz a quantidade de aleatoriedade e ao mesmo tempo é relevante para as pessoas. Este quadro também pode ser usado como um guia para futuras pesquisas sobre a melhoria da consistência dos LLMs e dos esforços contínuos para implementar os LLMs nos sistemas de tomada de decisão para melhorar a eficácia e a produtividade.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
✅ [Recommended Read] Nebius AI Studio se expande com modelos de visão, novos modelos de linguagem, incorporados e LoRA (Aprimorado)


