
A integração do Reinforcement Learning RL com grandes modelos de linguagem promove o desempenho do LLM em diferentes tarefas especializadas, como controlar robôs ou processamento de linguagem natural que requerem tomada de decisão sequencial. RL offline é uma técnica atualmente em uso que funciona com conjuntos de dados estáticos sem envolvimento adicional. No entanto, apesar do seu desempenho em situações de volta única, o RL offline perde terreno em aplicações sequenciais multivoltas. Os Métodos de Gradiente de Política são frequentemente usados em LLMs e VLMs nesta situação para reduzir a complexidade do RL, ao mesmo tempo que alcança a mesma precisão. Isto contradiz o princípio de RL de como a abordagem orientada para pequenos modelos falha miseravelmente em LLMs quando há grandes dados a serem aprendidos e adaptados dinamicamente e, portanto, um grande espaço para crescimento.
A pesquisa mostrou que a resposta ao enigma acima está nos blocos básicos. O RL offline tem desempenho abaixo das expectativas do LLM devido à incompatibilidade entre os objetivos de treinamento dos dois. Os modelos linguísticos são treinados para prever probabilidades, enquanto o Q-learning para RL visa prever valores de ação. Portanto, o RL offline manipula as probabilidades treinadas para usar suas representações subjacentes para atingir seu objetivo durante o ajuste fino do modelo. Esse engano leva à perda de conhecimento, linguagem, visão e até mesmo da sequência dos LLMs. Agora que discutimos a ineficácia da RL offline e seu grande potencial para os LLMs, discutimos pesquisas recentes que sugerem medidas para reduzir esse problema.
Pesquisadores da UC Berkeley apresentaram em seu artigo “Q-SFT: Q-LEARNING FOR LANGUAGE MODELS VIA SUPERVISED FINE-TUNING” um novo algoritmo que permite desbloquear o poder do RL sem reduzir as capacidades do modelo de linguagem. Os autores adicionam pesos ao objetivo de ajuste fino supervisionado padrão para aprender probabilidades que equilibram de forma mais confiável a função de valor em vez do comportamento da política. Eles transformam a função de máxima verossimilhança em uma função de entropia ponderada obtida a partir da relação de recorrência de Bellman. A modificação proposta permitiu aos autores evitar objetivos de regressão instáveis, mantendo ao mesmo tempo alta probabilidade no pré-treinamento. Este método compete frente a frente com métodos avançados.
IQ -SFT segue uma abordagem única. Em vez de seguir o método usual de treinamento de desempenho de valor, ajustando os valores Q ao seu suporte alvo, preservando o Bellman com perda de regressão, os autores ajustam diretamente as probabilidades aprendidas no treinamento anterior com a perda proposta para garantir que o Os valores Q não são. deixado para trás. O IQ-SFT fornece uma maneira de aprender valores Q para problemas dinâmicos de RL por meio de aprendizado supervisionado, sem atualizar pesos ou novas cabeças para representar valores Q. Além disso, a função de máxima verossimilhança definida pelos autores pode ser implementada diretamente a partir do log do LLM ou VLM pré-treinado.Q-SFT é superior a outros algoritmos RL baseados em aprendizagem supervisionada, como combinação de comportamento filtrado ou aprendizagem supervisionada com regressão . .
Componentes Q-SFT combinados de Q-learning e otimização supervisionada; portanto, os autores testaram-no em relação ao SOTA em ambos os métodos individuais para ver se o modelo combinado poderia atingir as categorias individuais. Para testar o Q-SFT offline para tarefas sequenciais de várias etapas RL, os autores compilaram vários benchmarks onde se espera que o modelo de linguagem tome decisões sequenciais. O primeiro conjunto de tarefas do teste incluiu vários jogos do benchmark LMRL. As decisões sequenciais do Q-SFT foram testadas usando Chess, Wordle e vinte questões. O IQ-SFT superou o Prompting e o SFT em LLM e o Implicit Language Learning Q em RL em todos os três jogos. No próximo conjunto de tarefas, os LLMs tiveram que se comportar como agentes e realizar tarefas interativas baseadas na web que também exigiam ferramentas. O LLM deveria comprar produtos da WebShop. O IQ-SFT também obteve pontuação relativamente alta. Para testar o desempenho dos modelos de Linguagem Visual, os autores testaram o Modelo no ALFWorld, um ambiente complexo baseado em texto com visualização gráfica onde o Modelo executa diversas tarefas complexas. Na ALFWorld, o LLM ocupou o lugar em 4 dos 6 empregos, e nos 2 restantes enfrentou outros. A tarefa final foi a Manipulação Robótica, onde o Q-SFT foi realizado com SOTA.
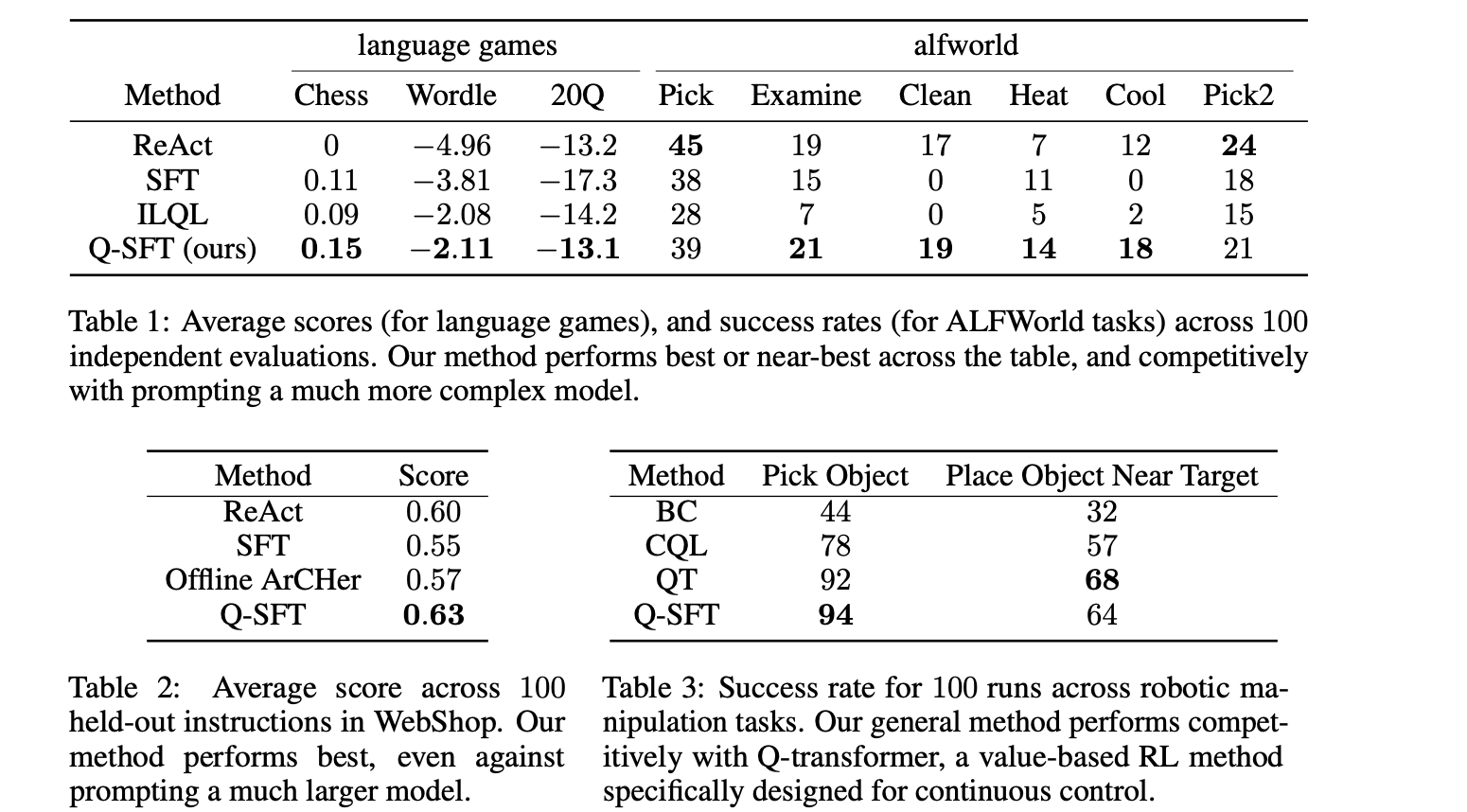
Conclusão: O IQ-SFT melhora os programas RL Q convencionais off-line, aprendendo valores Q como probabilidades semelhantes aos objetivos de ajuste fino supervisionados. IQ-SFT em modelos de linguagem grande teve melhor desempenho do que todos os RLs básicos supervisionados e baseados em valor. Também estava no mesmo nível do SOTA em tarefas de visão e robótica quando combinado com VLMs e transformadores robóticos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Adeeba Alam Ansari está atualmente cursando um diploma duplo no Instituto Indiano de Tecnologia (IIT) Kharagpur, cursando B.Tech em Engenharia Industrial e M.Tech em Engenharia Financeira. Com profundo interesse em aprendizado de máquina e inteligência artificial, ele é um leitor ávido e uma pessoa curiosa. A Adeeba acredita firmemente no poder da tecnologia para capacitar a sociedade e promover o bem-estar através de soluções inovadoras impulsionadas pela empatia e uma compreensão profunda dos desafios do mundo real.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


