
Os Modelos de Linguagem em Grande Escala (LLMs) demonstraram capacidades excepcionais em uma variedade de aplicações, mas sua ampla adoção enfrenta grandes desafios. A principal preocupação vem do treinamento de conjuntos de dados que contêm conteúdo diversificado, desfocado e potencialmente malicioso, incluindo código malicioso e informações relacionadas a ataques cibernéticos. Isto cria uma necessidade importante de adaptar os resultados do LLM aos requisitos específicos do usuário, evitando o uso indevido. Abordagens atuais, como a Aprendizagem por Reforço a partir do Feedback Humano (RLHF), tentam resolver essas questões incorporando as preferências humanas no comportamento modelado. No entanto, o RLHF enfrenta grandes limitações devido aos seus elevados requisitos computacionais, à dependência de modelos de recompensa complexos e à instabilidade inerente aos algoritmos de aprendizagem por reforço. Esta situação exige métodos eficientes e confiáveis para ajustar os LLMs, mantendo ao mesmo tempo o seu desempenho e garantindo o desenvolvimento responsável da IA.
Vários métodos de alinhamento surgiram para enfrentar os desafios de ajustar os LLMs às preferências das pessoas. O RLHF ganhou destaque pela primeira vez ao usar um modelo de recompensa treinado em dados de preferência humana, combinado com algoritmos de aprendizagem por reforço, como PPO, para desenvolver um modelo comportamental. No entanto, a sua implementação complexa e a natureza intensiva de recursos levaram ao desenvolvimento da Direct Policy Optimization (DPO), que simplifica o processo, eliminando a necessidade de um modelo de recompensa e, em vez disso, utilizando perdas cruzadas binárias. Estudos recentes exploraram diferentes métodos de divergência para controlar a variabilidade da produção, concentrando-se particularmente na divergência α como um equilíbrio entre a divergência KL reversa e a divergência KL direta. Além disso, os pesquisadores investigaram uma variedade de métodos para melhorar a variabilidade da resposta, incluindo técnicas de amostragem baseadas na temperatura, manipulação rápida e manipulação do objetivo de desempenho. A importância da diversidade está a tornar-se cada vez mais relevante, especialmente em tarefas onde o agrupamento – a capacidade de resolver problemas com múltiplas amostras geradas – é importante, como em matemática e aplicações de codificação.
Pesquisadores da Universidade de Tóquio e da Preferred Networks, Inc. eles apresentam DPOuma modificação radical da abordagem convencional do DPO que aborda as limitações do comportamento de busca de modo. Uma inovação fundamental reside no controlo da entropia da distribuição política resultante, permitindo a captura eficiente dos modos de distribuição alvo. A minimização da regressão KL tradicional às vezes pode falhar em atingir o ajuste de pesquisa de modo adequado, preservando a variância ao ajustar uma única distribuição a um alvo multimodal. O DPO aborda isso introduzindo um hiperparâmetro α que modifica o termo de normalização, permitindo a minimização deliberada da entropia quando α
A abordagem H-DPO apresenta uma abordagem robusta para controle de entropia no alinhamento do modelo de linguagem, alterando o termo KL inverso do particionador de variância. O método decompõe a regressão KL em componentes de entropia e entropia cruzada, introduzindo um coeficiente α que permite um controle preciso sobre a entropia da distribuição. A função objetivo do H-DPO é formulada como JH-DPO, que combina a recompensa esperada com o tempo de separação fixo. Se α for igual a 1, a função mantém o comportamento padrão do DPO, mas definir α abaixo de 1 promove a redução da entropia. Por otimização finita utilizando multiplicadores de Lagrange, a política ótima é obtida em função da política de referência e da recompensa, com α controlando a nitidez da distribuição. A implementação requer poucas modificações na estrutura DPO existente, que envolve basicamente a substituição do coeficiente β por αβ na função de perda, tornando-o mais aplicável a aplicações do mundo real.
Os testes experimentais do H-DPO mostraram melhorias significativas em vários benchmarks em comparação com o DPO padrão. O método foi testado em uma variedade de tarefas, incluindo problemas de matemática do ensino fundamental (GSM8K), tarefas de codificação (HumanEval), questões de múltipla escolha (MMLU-Pro) e tarefas de seguimento de instruções (IFEval). Ao reduzir α para valores entre 0,95 e 0,9, o H-DPO obteve melhor desempenho em todas as tarefas. As métricas de diversidade mostraram uma compensação interessante: valores baixos de α resultaram em diversidade reduzida na temperatura 1, enquanto valores altos de α aumentaram a diversidade. No entanto, a relação entre α e variabilidade mostrou-se mais complexa quando a variabilidade de temperatura foi considerada. No benchmark GSM8K, o H-DPO com α=0,8 obteve cobertura perfeita em 1 temperatura, os melhores resultados para o DPO padrão com melhor desempenho em 0,5. É importante ressaltar que no HumanEval, grandes valores de α (α=1,1) indicaram alto desempenho em situações de amostragem ampla (k>100), indicando que a variabilidade de resposta desempenhou um papel importante no desempenho da tarefa de codificação.
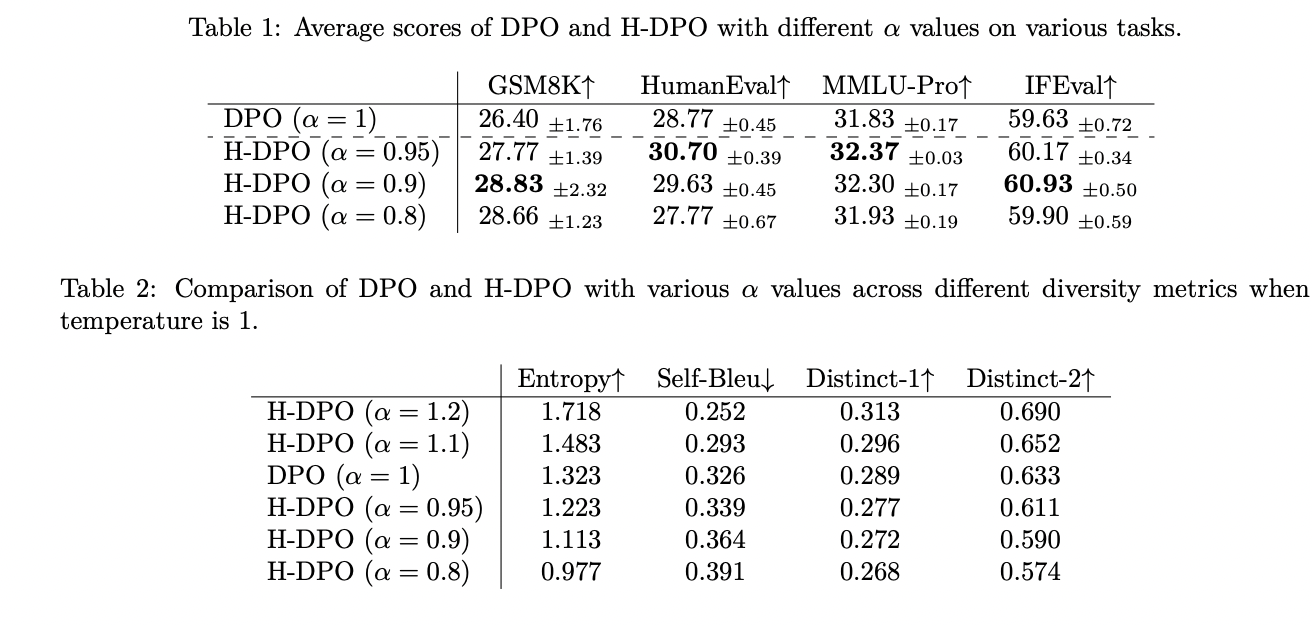
O DPO representa um grande avanço na modelagem de linguagem, fornecendo uma modificação simples, porém eficaz, à estrutura padrão do DPO. Ao usar seu método de controle de entropia usando o hiperparâmetro α, o método atinge um comportamento de busca de modo mais elevado e permite um controle mais preciso sobre a distribuição de saída. Os resultados dos testes em todas as diversas funções mostraram maior precisão e diversidade nos resultados dos modelos, principalmente eles apresentam bom desempenho em raciocínio estatístico e métricas de integração. Embora o ajuste α manual ainda seja uma limitação, a implementação direta e o desempenho impressionante do H-DPO fazem dele uma contribuição importante para o campo do alinhamento de modelos de linguagem, abrindo caminho para sistemas de IA eficientes e controláveis.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias– Da estrutura à produção
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
🐝🐝 Evento do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar o modelo de suas equipes – a IA está mudando o jogo, rápido.
: uma série 1B, 3B e 40B de modelos de IA generativos")

 para geração eficiente de dados incorporados em grande escala")