
Avanços recentes na modelagem de linguagem generativa avançaram no processamento de linguagem natural, tornando possível criar texto consistente e rico em contexto em uma ampla variedade de aplicações. Os modelos autorregressivos (AR) geram texto na ordem da esquerda para a direita e são amplamente utilizados em tarefas como codificação e raciocínio complexo. Porém, esses modelos enfrentam limitações devido à sua natureza sequencial, o que os torna vulneráveis ao acúmulo de erros a cada passo. Depender de uma ordem rígida de geração de tokens pode limitar a flexibilidade na geração de sequências. Para resolver estas desvantagens, os investigadores começaram a explorar outros métodos, especialmente aqueles que permitem a produção paralela, tornando a criação de texto mais fácil e eficiente.
Um desafio crítico na modelagem de linguagem é o acúmulo contínuo de erros encontrados em métodos automatizados. Como cada token gerado depende diretamente do anterior, pequenos erros iniciais podem levar a desvios significativos, afetando a qualidade do texto gerado e reduzindo a eficiência. Abordar essas questões é importante, pois a formação de erros reduz a precisão e limita o uso de modelos AR em aplicações em tempo real que exigem saída confiável e de alta velocidade. Portanto, os pesquisadores estão investigando a geração paralela de texto para manter o alto desempenho e minimizar erros. Embora os modelos da mesma geração tenham se mostrado promissores, muitas vezes eles precisam corresponder à compreensão detalhada do contexto que os modelos convencionais de AR alcançam.
Atualmente, diferentes modelos de distribuição destacam-se como uma solução emergente para a produção de texto uniforme. Esses modelos geram sequências completas de uma só vez, proporcionando vantagens significativas de velocidade. Vários modelos de distribuição partem de uma sequência totalmente coberta e gradualmente revelam tokens de maneira não sequencial, permitindo a geração de texto bidirecional. Apesar dessa capacidade, os métodos atuais baseados em distribuição enfrentam limitações devido à sua dependência da previsão de tokens independentes, que ignoram as dependências entre tokens. Esta independência muitas vezes leva a uma diminuição na precisão e à necessidade de mais etapas de amostragem, resultando em ineficiência. Embora alguns modelos tentem preencher a lacuna entre qualidade e velocidade, a maioria precisa de ajuda para alcançar a precisão e suavidade oferecidas pela configuração automática.
Pesquisadores da Universidade de Stanford e da NVIDIA apresentam o Modelo de Linguagem de Difusão Baseado em Energia (EDLM). EDLM representa uma abordagem inovadora que combina modelagem baseada em energia com distribuições discretas para enfrentar os desafios da geração uniforme de texto. Ao integrar a função de potência em cada etapa do processo de distribuição, o EDLM busca corrigir as dependências entre tokens, melhorando assim a qualidade da sequência e mantendo os benefícios da produção paralela. A função de potência permite que o modelo aprenda a dependência dentro da série usando um modelo autoregressivo pré-treinado ou uma convolução bidirecional ajustada com estimativa inversa de ruído. A estrutura do EDLM, portanto, combina a eficiência da distribuição e a regularidade da sequência de métodos baseados em potência, tornando-o o primeiro modelo na área de geração de linguagem.
A estrutura EDLM envolve uma abordagem profunda que se concentra na introdução de uma função de energia que captura dinamicamente a correlação entre tokens ao longo do processo de produção. Esta função de poder atua como um mecanismo corretivo em cada etapa de distribuição, abordando efetivamente os desafios associados à independência do token em outros modelos de distribuição diferentes. Ao adotar uma forma residual, a função de potência permite que o EDLM refine iterativamente as previsões. A estrutura baseada em energia funciona em modelos pré-treinados, permitindo que o EDLM contorne a necessidade de treinamento potencialmente sofisticado – um processo caro. Em vez disso, a função de potência do modelo atua diretamente na sequência, o que permite ao EDLM realizar uma amostragem mais eficiente usando amostragem significativa, melhorando a precisão do modelo. Este método de amostragem eficiente reduz erros de decodificação, otimizando o método de dependência de token, diferenciando o EDLM de outros métodos baseados em distribuição.
Os testes de desempenho do EDLM revelam melhorias significativas na velocidade e qualidade da geração de texto. Em testes com outros modelos em benchmarks de linguagem, o EDLM mostrou uma redução de até 49% na confusão gerativa, marcando uma melhoria significativa na precisão da geração de texto. Além disso, o EDLM demonstrou amostragem 1,3x mais rápida em comparação com modelos de distribuição convencionais, tudo sem sacrificar o desempenho. Os testes de benchmark também mostraram que o EDLM se aproxima dos níveis de confusão normalmente alcançados pelos modelos automatizados, mantendo os ganhos de eficiência encontrados na geração paralela. Por exemplo, quando comparado usando o conjunto de dados Text8, o EDLM obteve a menor pontuação de bit por caractere entre os modelos testados, destacando sua capacidade superior de manter a consistência do texto com menos erros de decodificação. Além disso, no conjunto de dados OpenWebText, o EDLM superou outros modelos de distribuição de última geração, alcançando desempenho competitivo mesmo quando comparado a modelos autorregressivos robustos.
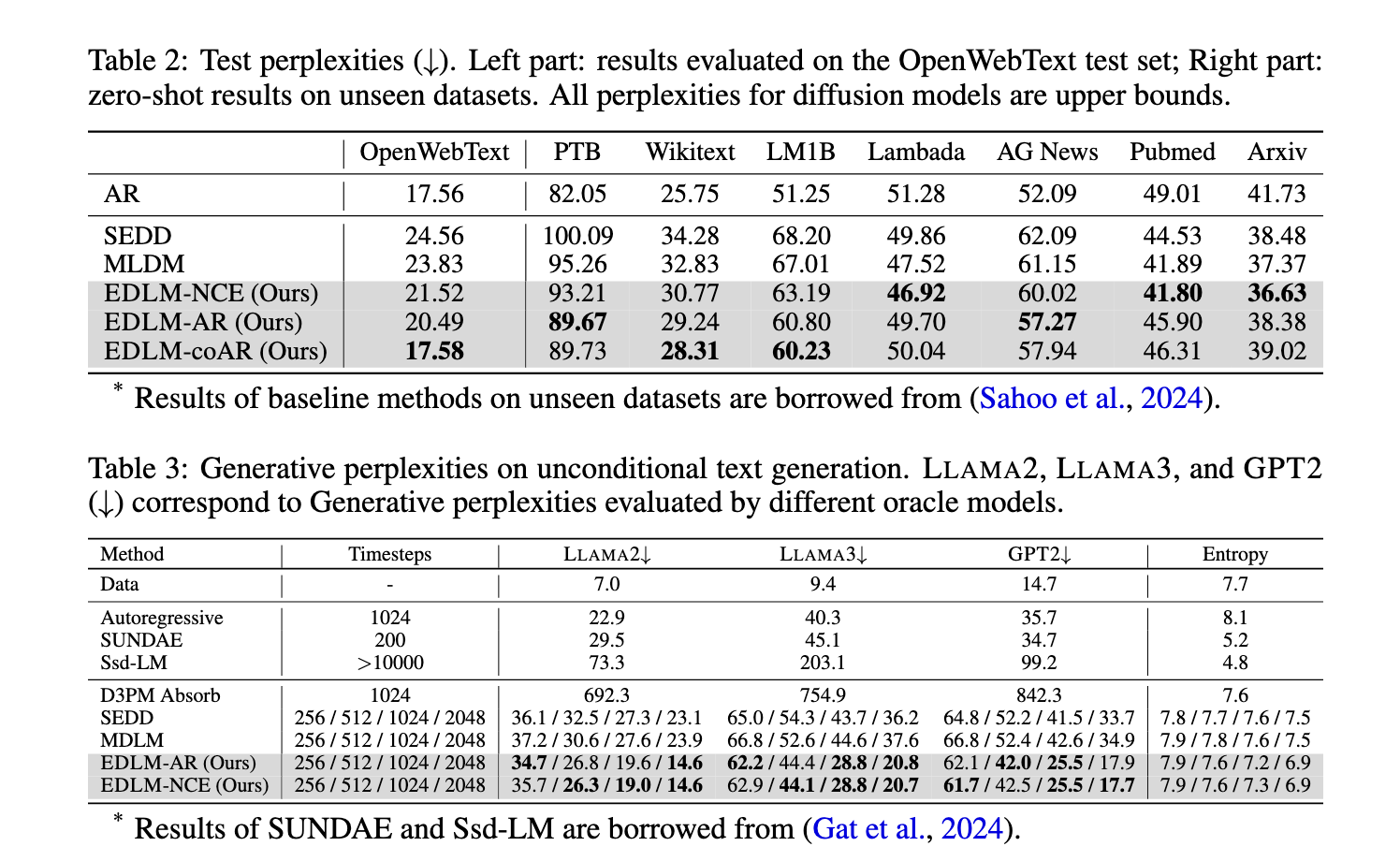
Em conclusão, o novo método EDLM aborda com sucesso os problemas de longa data de dependência de sequência e propagação de erros em modelos de produção de linguagem. Ao combinar efetivamente correções baseadas em potência com modelos de distribuição semelhantes a potência, o EDLM apresenta um modelo que oferece maior precisão e velocidade. Esta inovação de pesquisadores de Stanford e da NVIDIA mostra que os métodos baseados em energia podem desempenhar um papel importante no desenvolvimento de modelos de linguagem, fornecendo uma alternativa promissora aos métodos automatizados para aplicações que exigem eficiência e eficácia. As contribuições do EDLM formam a base para modelos de linguagem flexíveis e conscientes da situação que podem alcançar precisão e eficiência, enfatizando o poder das estruturas baseadas em dinâmicas no desenvolvimento de tecnologias de texto generativo.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


