
As redes neurais tornaram-se ferramentas fundamentais em visão computacional, PNL e muitos outros campos, fornecendo capacidades para modelar e prever padrões complexos. O processo de treinamento é fundamental para o desempenho de uma rede neural, onde os parâmetros da rede são ajustados iterativamente para minimizar erros por meio de técnicas de otimização, como gradiente descendente. Essa otimização ocorre em um espaço de parâmetros de alta dimensão, tornando difícil determinar como a configuração inicial dos parâmetros afeta o estado final do treinamento.
Embora tenha havido progresso no estudo dessas mudanças, questões sobre a dependência dos parâmetros finais de seus valores iniciais e o papel dos dados de entrada ainda precisam ser respondidos. Os investigadores querem determinar se certas iniciativas conduzem a diferentes formas de melhoria ou se a mudança é largamente dominada por outros factores, como a arquitectura e a distribuição de dados. Esse entendimento é importante para projetar algoritmos de treinamento mais eficientes e melhorar a interpretabilidade e robustez das redes neurais.
Pesquisas anteriores forneceram insights sobre a natureza de baixa dimensão do treinamento de redes neurais. A pesquisa mostra que as atualizações de parâmetros tendem a ocupar muito pouco do espaço geral de parâmetros. Por exemplo, a projeção de atualizações de gradiente em subespaços de baixa dimensão definidos aleatoriamente geralmente tem pouco efeito no desempenho final da rede. Alguns estudos observaram que muitos parâmetros permanecem próximos de seus valores iniciais durante o treinamento, e as atualizações costumam ser de baixo nível em intervalos curtos. No entanto, estas abordagens não conseguem explicar completamente a relação entre os estados inicial e final ou como as estruturas específicas dos dados influenciam estas dinâmicas.
Pesquisadores da EleutherAI introduziram uma nova estrutura para analisar o treinamento de redes neurais usando a matriz Jacobiana para resolver os problemas acima. Este método avalia o Jacobiano dos parâmetros treinados em relação aos seus valores iniciais, capturando como a inicialização molda o parâmetro final. Usando uma decomposição de valor único desta matriz, os pesquisadores dividiram o processo de treinamento em três subáreas distintas:
- Porão caótico
- Subespaço Múltiplo
- Um subespaço estável
Esta decomposição fornece uma compreensão detalhada do efeito da inicialização e da estrutura de dados na dinâmica de treinamento, o que fornece uma nova perspectiva para otimização de redes neurais.
A metodologia envolve linearizar o processo de treinamento em torno dos parâmetros iniciais, permitindo que a matriz Jacobiana mapeie como pequenas perturbações de inicialização se propagam durante o treinamento. Uma decomposição de valor único revela três regiões distintas no espectro Jacobiano. A região caótica, composta por aproximadamente 500 valores singulares maiores que um, representa as direções nas quais as mudanças de parâmetros são maximizadas durante o treinamento. A região de massa, com valores de cerca de 3.000 singularidades próximas de um, corresponde à dimensão onde os parâmetros permanecem constantes. Uma região estável, com valores de cerca de 750 singularidades menores que uma, dá sinais de que as mudanças estão diminuindo. Esta decomposição sistemática destaca a influência variável das direções do espaço de parâmetros no progresso do treinamento.
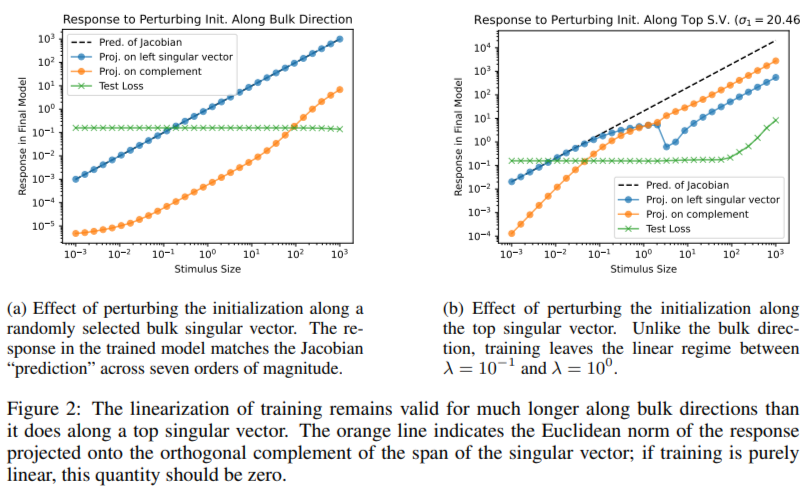
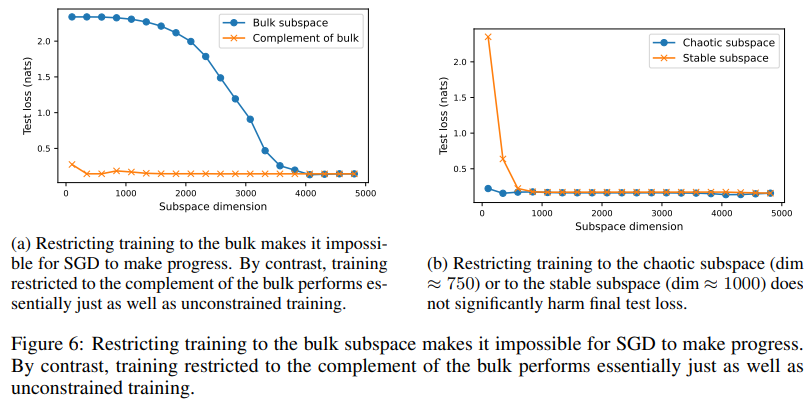
Em testes, a subsuperfície turbulenta altera o potencial de otimização e aumenta a perturbação do parâmetro. Um subespaço estável garante uma convergência suave ao amortecer as transições. Curiosamente, apesar de ocupar 62% do espaço de parâmetros, o subespaço de massa tem pouca influência no comportamento da distribuição, mas afeta significativamente as previsões dos dados fora de distribuição. Por exemplo, perturbações ao longo das direções em massa deixam as previsões do conjunto de teste quase inalteradas, enquanto aquelas na subsuperfície turbulenta ou estável podem alterar a saída. Restringir o treinamento a um substrato de massa dada uma descida gradiente foi ineficaz, enquanto o treinamento em substratos turbulentos ou estáveis alcançou desempenho comparável ao treinamento irrestrito. Esses padrões foram consistentes em diferentes implementações, funções de perda e conjuntos de dados, demonstrando a robustez da estrutura proposta. Um teste de perceptron multicamadas (MLP) com uma camada oculta de 64 larguras, treinado no conjunto de dados de dígitos UCI, confirmou esta observação.
Existem muitas conclusões deste estudo:
- A subsuperfície turbulenta, que inclui quase 500 valores singulares, maximiza a perturbação do parâmetro e é importante na formação da força de otimização.
- Com valores de aproximadamente 750 por unidade, a base estável amortece eficazmente as perturbações, contribuindo para uma sessão de treino suave e estável.
- O subespaço em massa, que representa 62% do espaço de parâmetros (cerca de 3.000 valores singulares), permanece constante durante o treinamento. Tem pouco efeito no comportamento de difusão, mas efeitos importantes na previsão e difusão de longo alcance.
- Perturbações associadas a subespaços caóticos ou estáveis alteram a saída da rede, enquanto a maioria das perturbações não afeta as previsões experimentais.
- Restringir o treinamento ao subsolo torna a otimização ineficaz, enquanto o treinamento forçado em subsuperfícies caóticas ou estáveis é mais eficaz do que o treinamento completo.
- Os experimentos mostraram consistentemente esses padrões em diferentes conjuntos de dados e implementações, destacando a generalidade das descobertas.
Concluindo, este estudo apresenta uma estrutura para a compreensão da dinâmica do treinamento de redes neurais, decompondo as atualizações de parâmetros em subespaços caóticos, estáveis e múltiplos. Ele destaca a interação complexa entre inicialização, estrutura de dados e evolução de parâmetros, fornecendo informações importantes sobre como ocorre o treinamento. Os resultados revelam que o subespaço caótico impulsiona a eficiência, o subespaço estável garante a convergência e o subespaço em massa, embora grande, tem pouco efeito no comportamento de difusão interna. Esse insight sutil desafia suposições comuns sobre atualizações uniformes de parâmetros. Ele fornece métodos eficazes para o desenvolvimento de redes neurais.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que são tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


