
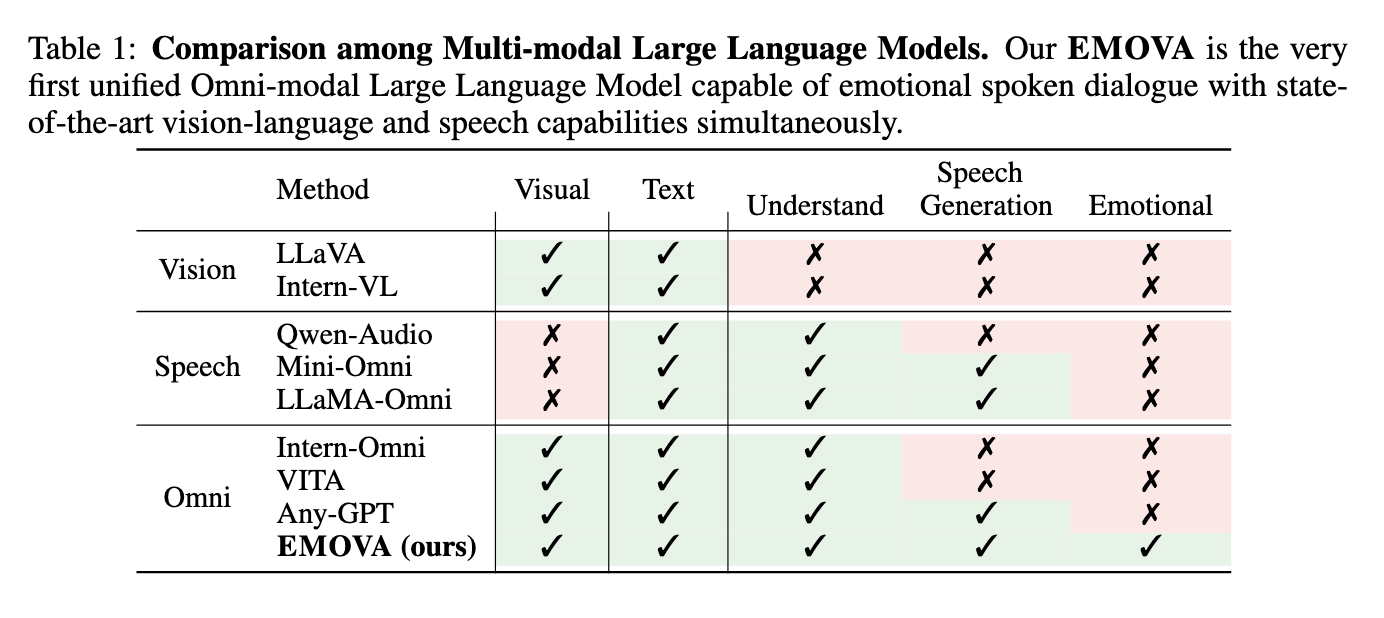
Os modelos linguísticos omnimodais (LLMs) estão na vanguarda da pesquisa em inteligência artificial, buscando integrar múltiplas modalidades de dados, como visão, linguagem e fala. O principal objetivo é melhorar as capacidades interativas desses modelos, permitindo-lhes ver, compreender e gerar resultados a partir de todas as diversas entradas, tal como um ser humano faria. Esses avanços são essenciais para a criação de sistemas completos de IA para interagir naturalmente, responder visualmente, interpretar comandos de voz e fornecer respostas personalizadas em formatos de texto e fala. Tal ação envolve projetar modelos para lidar com tarefas de alto nível, integrando informações sensoriais e textuais.
Apesar dos avanços em métodos individuais, os modelos de IA existentes precisam de ajuda para integrar capacidades visuais e de fala numa estrutura unificada. Os modelos atuais que se concentram na linguagem visual ou na linguagem falada muitas vezes não conseguem alcançar uma compreensão perfeita de todas as três modalidades simultaneamente. Esta limitação restringe a sua aplicação a situações que requerem interação em tempo real, como assistentes virtuais ou robôs autónomos. Além disso, os modelos de fala atuais dependem fortemente de dispositivos externos para gerar saída de voz, o que introduz atrasos e limita a flexibilidade no controle do estilo de fala. O desafio permanece em projetar um modelo que possa superar esses obstáculos e ao mesmo tempo manter um alto desempenho na compreensão e geração de conteúdo multimodal.
Vários métodos têm sido utilizados para desenvolver modelos multimodais. Modelos de linguagem de visão como LLaVA e Intern-VL usam codificadores de visão para extrair e combinar recursos visuais com dados textuais. Modelos de linguagem de fala, como o Whisper, usam codificadores de fala para extrair recursos contínuos, permitindo que o modelo entenda a entrada de voz. No entanto, esses modelos são limitados pela dependência de ferramentas externas de conversão de texto em fala (TTS) para gerar respostas de fala. Esta abordagem limita a capacidade do modelo de reproduzir a fala em tempo real e a dinâmica emocional. Além disso, os esforços de modelos omnimodais, como AnyGPT, dependem da segmentação de dados, o que muitas vezes leva à perda de informações, principalmente nas modalidades visuais, o que reduz o desempenho do modelo em tarefas visuais de alta resolução.
Pesquisadores da Universidade de Ciência e Tecnologia de Hong Kong, da Universidade de Hong Kong, do Huawei Noah's Ark Lab, da Universidade Chinesa de Hong Kong, da Universidade Sun Yat-sen e da Southern University of Science and Technology lançaram o EMOVA (Emotionally Omni-presente Voice Assistente). Este modelo representa um avanço significativo na pesquisa LLM ao integrar perfeitamente recursos visuais, de linguagem e de fala. A estrutura exclusiva do EMOVA combina um codificador de percepção contínua e um token de fala para unidade, permitindo que o modelo execute o processamento de fala e entrada visual de ponta a ponta. Ao utilizar um token de fala separado semântico-acústico, o EMOVA separa o conteúdo semântico (o que é dito) do estilo acústico (como é dito), permitindo produzir fala com diferentes tons emocionais. Esse recurso é importante em aplicações de conversação falada em tempo real, onde a capacidade de expressar emoções por meio da fala acrescenta profundidade às interações.
O modelo EMOVA consiste em vários componentes projetados para lidar eficazmente com métodos específicos. Um codificador de visão captura recursos visuais de alta resolução, renderizando-os em um ambiente de incorporação de texto, enquanto um codificador de fala converte a fala em unidades discretas que o LLM pode processar. Uma característica importante do modelo é o método de classificação semântico-acústica, que separa o significado do conteúdo falado de seus atributos estilísticos, como tom ou tom emocional. Isso permite que os pesquisadores introduzam um módulo de estilo leve para controlar a saída da fala, permitindo que o EMOVA expresse várias emoções e estilos de fala personalizados. Além disso, a integração de texto como uma ponte para alinhar dados de imagem e fala elimina a necessidade de conjuntos de dados omnimodais especializados, que muitas vezes são difíceis de obter.
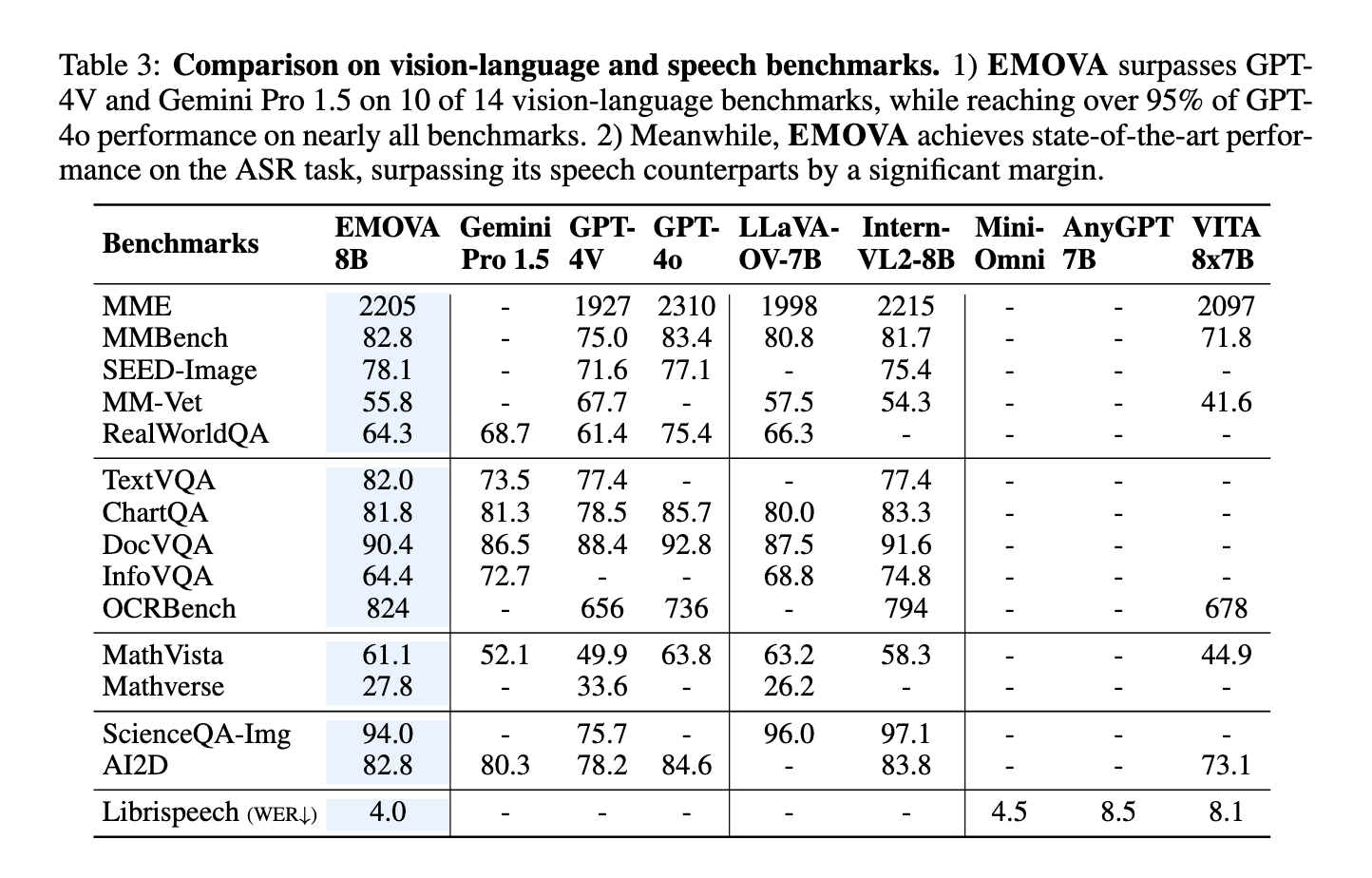
O desempenho do EMOVA foi avaliado em diversos benchmarks, mostrando seu poder superior em relação aos modelos existentes. Para tarefas de fala para idioma, o EMOVA alcançou impressionantes 97% de precisão, superando outros modelos de última geração, como AnyGPT e Mini-Omni, por uma margem de 2,8%. Para tarefas de linguagem visual, o EMOVA alcançou 96% de precisão no conjunto de dados MathVision, superando modelos concorrentes como Intern-VL e LLaVA em 3,5%. Além disso, a capacidade do modelo de manter alta precisão em tarefas visuais e de fala simultaneamente não tem precedentes, já que muitos modelos existentes muitas vezes se destacam em uma abordagem em detrimento da outra. Esta funcionalidade abrangente torna o EMOVA o primeiro LLM capaz de suportar conversas emocionalmente ricas e em tempo real, ao mesmo tempo que alcança resultados de alta qualidade em vários domínios.
Em resumo, a EMOVA aborda uma lacuna crítica na integração das capacidades de percepção, linguagem e fala num único modelo de IA. Ao combinar o desemaranhamento semântico-acústico e uma estratégia de alinhamento omnimodal eficaz, não só tem um bom desempenho em benchmarks padrão, mas também introduz flexibilidade no controle da fala emocional, tornando-o uma ferramenta versátil para interações avançadas de IA. Este avanço abre caminho para a investigação e desenvolvimento contínuos de grandes modelos de linguagem omnimodais, estabelecendo um novo padrão para o desenvolvimento futuro neste campo.
Confira Papel de novo O projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


