: o novo método para melhorar as melhorias em grandes modelos de idiomas")
Os principais modelos de idiomas (LLMs) desenvolvidos no campo da inteligência artificial usados em muitos programas. Embora possam imitar quase completamente a linguagem das pessoas completamente, elas geralmente perdem as diferenças de feedback. Esse limite é muito frustrante em atividades que exigem inteligência, como a produção de questões e assuntos, onde os vários resultados são importantes para continuar se encontrando e participando.
Um dos maiores desafios da otimização do modelo de idioma é uma redução em resposta à diferença devido à sua escolha de estratégias de treinamento. Métodos de treinamento, como o fortalecimento das pessoas, o aprendizado e a popularidade específica em popularidade (DPO) são o resultado de modelos de várias gerações de vários incentivos, o que impede sua adaptação em programas criativos. As variações de diversidade evitam modelos poderosos na linguagem para trabalhar com sucesso nos campos que exigem uma produção abrangente.
Maneiras anteriores de fazer preferências bem que enfatizam especialmente a adaptação de modelos com opções de alta qualidade. Técnicas guardadas para o humorismo e a programação de RLHF, enquanto trabalham efetivamente no desenvolvimento de alinhamento do modelo, resultando na resposta da homogeneização. A popularidade direta da popularidade (DPO) escolhe as respostas mais recompensadas ao descartar baixa qualidade, enfatiza as tendências de produzir resultados visíveis. Os esforços para combater esse problema, como alterar os níveis de amostragem ou o uso do status de defesa de difer de KL, falharam em promover diferenças sem comprometer a qualidade da saída.
Investigadores da Meta, Nova York University e ETH Zurich introduziram o DivPo, um novo processo projetado para melhorar as variáveis de resposta, enquanto armazenava alta qualidade. Ao contrário dos métodos de desempenho tradicionais que estimulam a resposta mais recompensada, o DivPO escolhe em seus pares favoritos, dependendo da qualidade e da diversidade. Isso garante que o modelo produz efeitos não limitados na alternativa das pessoas, mas também varia, tornando -os mais sucesso nos sistemas operacionais.

O DVPO é uma amostra de muita resposta rápida fornecida e encontre -os usando um modelo de recompensa. Em vez de escolher uma única resposta recompensada, ela responde demais, a qualidade de alta qualidade é selecionada como uma preferência. Por outro lado, uma variedade de respostas que não atendem ao limite de qualidade é selecionada como rejeitado emitido. Essa estratégia de consignação e diversificando a alocação de DIPPO para ler uma distribuição mais ampla de respostas, garantindo que cada resultado esteja mantendo um alto padrão. Essa abordagem inclui uma variedade de métodos de diversidade, incluindo o potencial dos nomes, nomes e julgamento baseado no LLM, para testar a formação de cada resposta.
Um estudo abrangente é realizado para garantir o desempenho do divpo, com foco na identidade humana formal e nas atividades de escrita aberta. Os resultados mostraram que o DivPO aumentou a diversidade sem desistir da qualidade. Comparado aos métodos comuns da metodologia, o DIVPO levou a um aumento de 45,6% no pessoal pessoal e 74.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6.6% O aumento da variação da história. O exame também mostrou que o DivPO impede os modelos para criar um pequeno conjunto de respostas diferentes, confirmar a distribuição dos recursos produzidos. A visão principal era que os modelos foram treinados usando os modelos United DivPO nas variações na diversidade, enquanto armazenam alta qualidade, conforme testado pelo modelo revisado do ArmorM.
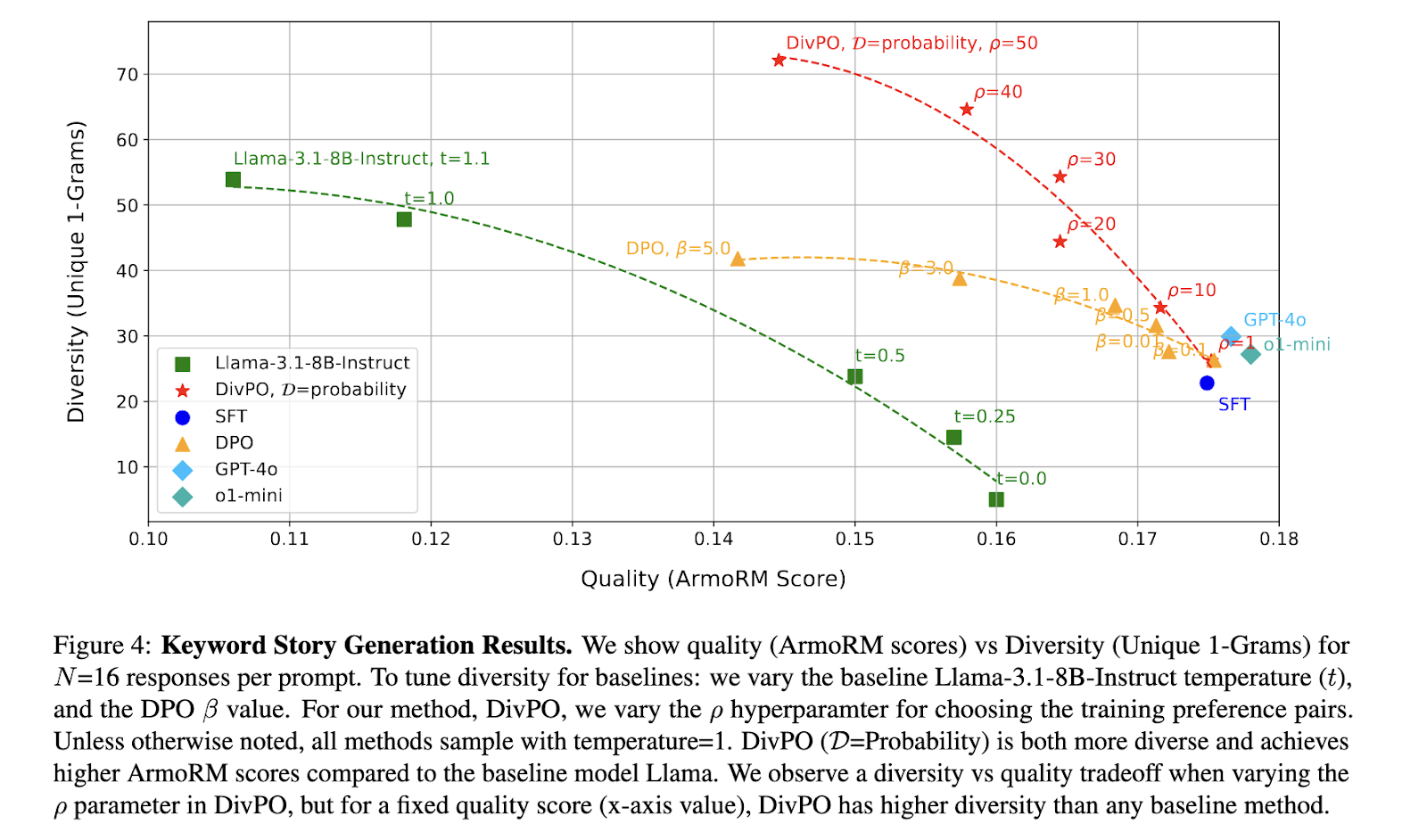
Análises de geração humana adicionais dos modelos bem organizados do país, como a LLAMA-INFORMAÇÃO DE 3,1-8B, não produziram diferentes qualidades de persona, geralmente repetem um grupo de nomes diferentes. O DVPO preparou esse problema aumentando a lista de qualidade produzida, resultando na distribuição de um resultado equilibrado e representativo. A função da geração de geração organizada indicou que o vídeo da Internet tem a frequência das palavras que desenvolvem diferenças em 30,07% em comparação com o modelo básico, mantendo a qualidade da qualidade da resposta. Da mesma forma, a função de escrita de palavras -chave mostrou grande desenvolvimento, que detecta 13,6% da diversidade e aumentou 39,6% de qualidade relacionada ao desempenho normal.
Essas descobertas garantem que os métodos de uso de gostos para reduzir a diversidade, desafiadores de idiomas feitos para tarefas abertas. A DivPO está aliviando esse problema instalando opções de diversidade, permitindo que os modelos de linguagem mantenham respostas de alta qualidade sem impedir a variação. Com a variedade de alinhamento, o DVPO melhora a variável e o uso de LLMs em todos os domínios de domínio, para garantir que eles permaneçam úteis em aplicativos criativos, de análise e produção de dados. O lançamento do DivPO é uma grande ênfase na qualidade da popularidade, que fornece uma solução ativa para a solução de longo prazo.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 O Marktechpost está gritando para as empresas / inicialização / grupos cooperarem com as próximas revistas da IA a seguinte 'fonte AI em produção' e 'e' Agentic AI '.
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo


