
Modelos Linguísticos de Grande Escala (LLMs) demonstraram habilidades notáveis em uma ampla gama de tarefas de processamento de linguagem natural (PNL), como tradução automática e resposta a consultas. No entanto, um grande desafio permanece na compreensão da base teórica do seu trabalho. Em particular, falta uma estrutura abrangente que explique como os LLMs produzem sequências de texto coerentes e coerentes. Este desafio é agravado por limitações como tamanhos fixos de vocabulário e janelas de contexto, que restringem a compreensão completa da sequência de tokens que os LLMs podem processar. Enfrentar este desafio é essencial para melhorar a eficácia dos LLMs e aumentar a sua eficácia no mundo real.
Pesquisas anteriores concentraram-se no sucesso dos LLMs, especialmente aqueles construídos sobre uma estrutura de transformador. Embora esses modelos tenham um bom desempenho em tarefas que envolvem a produção sequencial de tokens, as pesquisas existentes simplificaram sua formulação para análise teórica ou ignoraram a dependência temporal associada às sequências de tokens. Isto limita o âmbito das descobertas e deixa lacunas na nossa compreensão de como os LLMs funcionam em geral, para além dos seus dados de formação. Além disso, nenhuma estrutura encontrou com sucesso os parâmetros teóricos gerais dos LLMs ao lidar com sequências dependentes do tempo, o que é importante para a sua ampla aplicação em aplicações do mundo real.
Uma equipe de pesquisadores da ENS Paris-Saclay, Inria Paris, Imperial College London e Huawei Noah's Ark Lab apresentam uma nova estrutura modelando LLMs como cadeias de Markov de estado finito, onde cada sequência de entrada de tokens corresponde a um estado, e transições entre os estados são determinados pela previsão do modelo para o próximo token. Esta formulação captura toda a gama de sequências de tokens possíveis, fornecendo uma maneira sistemática de analisar o comportamento do LLM. Ao formalizar os LLMs com esta estrutura probabilística, a pesquisa fornece insights sobre suas capacidades de raciocínio, especificamente a distribuição estacionária de sequências de tokens e a velocidade com que o modelo converge para esta distribuição. Esta abordagem representa um avanço importante na compreensão de como funcionam os LLMs, pois fornece uma base mais interpretável e teoricamente fundamentada.
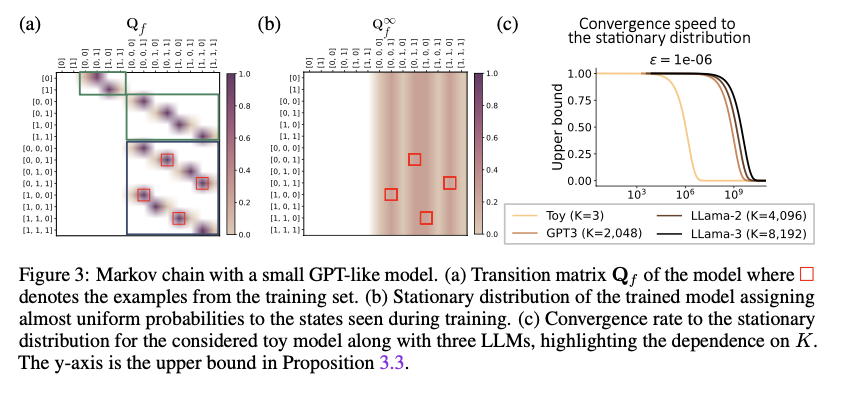
Este método constrói uma representação em cadeia de Markov de LLMs definindo uma matriz de transição Qf, com uma estrutura esparsa e restrita, que captura a sequência de possíveis saídas do modelo. O tamanho da matriz de transformação é O(T^k), onde T é o tamanho das palavras e K é o tamanho da janela de contexto. A distribuição estacionária obtida a partir desta matriz mostra o comportamento de previsão de longo prazo do LLM para todas as sequências de entrada. Os investigadores também examinaram o efeito da temperatura na capacidade do LLM de atravessar a região de forma eficiente, mostrando que temperaturas mais elevadas levam a uma convergência mais rápida. Esses detalhes foram confirmados testando modelos semelhantes ao GPT, confirmando as previsões teóricas.
Testes experimentais em vários LLMs confirmaram que modelá-los como cadeias de Markov leva à exploração eficiente do espaço de estados e à rápida convergência para uma distribuição estacionária. Configurações de temperatura mais altas melhoraram significativamente a velocidade de convergência, enquanto modelos com núcleos de janela maiores exigiram etapas adicionais de estabilização. Além disso, o quadro tem sido mais eficaz do que os métodos tradicionais no estudo de matrizes de transição, especialmente em grandes áreas do estado. Estes resultados destacam a robustez e eficiência desta abordagem no fornecimento de informações aprofundadas sobre o comportamento do LLM, especialmente na geração de sequências coerentes que funcionam em tarefas do mundo real.
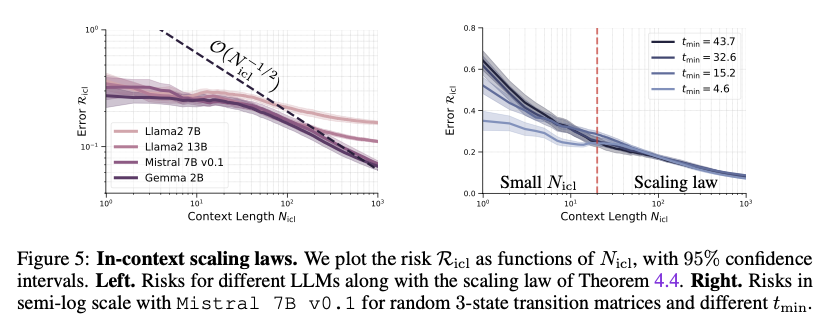
Este estudo apresenta um arcabouço teórico que modela LLMs como cadeias de Markov, o que fornece uma forma sistemática de compreender seus processos de raciocínio. Ao encontrar parâmetros de generalização e validá-los por meio de testes de quadros, os pesquisadores mostram que os LLMs são os aprendizes mais eficazes de sequências de tokens. Essa abordagem melhora muito o design e a otimização dos LLMs, levando a uma melhor otimização e melhor desempenho em toda a gama de práticas de PNL. A estrutura fornece uma base sólida para pesquisas futuras, particularmente no exame de como os LLMs processam e geram sequências coerentes em diferentes ambientes do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – Conferência de recuperação de dados GenAI (promovida)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.


