 e um giro: a abordagem da IA híbrida que inclui as preferências populares e a precisão de treinamento confiável de LLM confiável")
Grandes modelos de linguagem (LLMS) dependem das estratégias de aprendizado apertado para melhorar as habilidades de resposta. Um fator crítico de seu desenvolvimento é um modelo de recompensa, ajudando nos modelos de treinamento melhor sincronização e expectativas. Os modelos de recompensa verificam as respostas com base na preferência das pessoas, mas os métodos geralmente são atormentados em manutenção e medindo a verdadeira precisão. Isso pode levar a um pequeno desempenho, pois os modelos podem priorizar a precisão. Melhorar o modelo de recompensa com sinais de precisão garantida pode ajudar a melhorar a confiabilidade dos LLMs na aplicação da Terra original.
O maior desafio nos programas atuais para recompensar sua pesada lealdade das pessoas, que é visível e tende a inspecionar. Esses modelos permitem respostas ou materiais verbase que são mais bonitos do que as respostas corretas. A ausência de verbos planejados está programada para recompensa normal Monsons limita sua capacidade de verificar a precisão, tornando -os vulneráveis para descobrir o que está errado. Além disso, os problemas crônicos são frequentemente negligenciados, resultando em um aumento que não atende a usuários específicos. É importante lidar com esses problemas para melhorar a estabilidade e a confiança das respostas produzidas pela AI.
Os modelos de recompensa tradicionais se concentram no aprendizado com base no aprendizado com base no aprendizado, como um aprendizado fortalecedor sobre a resposta das pessoas (RLHF). Enquanto o RLHF está atualizando o alinhamento do modelo, ele não inclui autenticação da precisão sistemática. Alguns dos modelos estão tentando inspecionar as respostas com base em melodial e adequadamente, mas podem fazer fortes maneiras de se adaptar à precisão ou aderência às instruções. Formas diferentes, como a confirmação relacionada, foram avaliadas, mas não amplamente integradas devido aos desafios de incluir o envolvimento. Este estimado enfatiza a necessidade de um programa de recompensa gratificante que inclua as preferências de precisão dos sinais de precisão que confirmam os efeitos do modelo de alta qualidade.
Universidade Stinghua Investigates enviados Modificações de pais agênticos (ARM)O programa de gratificante de novembro inclui recompensas visuais suportadas com sintomas de precisão verificados. O caminho inclui um agente de recompensa em nome de ErrarO que melhora a confiabilidade das recompensas combinando as preferências com a verificação da realidade. O programa garante que o LLM produza as duas respostas selecionadas pelos usuários e sejam verdadeiras. Ao integrar os seguintes fatos e avaliação, um braço fornece uma estrutura poderosa para uma recompensa que reduz uma discriminação equilibrada e melhora o alinhamento apropriado.
Esta página Errar O programa contém três módulos principais. Esta página Roteador Analise as instruções dos usuários para descobrir quais agentes de verificação devem funcionar com base nos requisitos do trabalho. Esta página Agentes de verificação Verificando as respostas em dois aspectos críticos: verdadeira precisão e adesão a questões difíceis. A idade genética um do outro analisa as informações usando conhecimento parandrico e recursos externos, para garantir que as respostas sejam formadas e definidas adequadamente. O próximo agente de ensino garante a conformidade com as questões de duração, doença e conteúdo, combinando certas ordens e confirmando as respostas contra leis definidas anteriormente. O último módulo, ElesInclui sinais e pontuações que eles gostam de integrar pontos gerais de recompensa, para equilibrar a resposta de uma pessoa à verificação de uma pessoa. O estado permite que o programa escolha os métodos apropriados para diferentes funções, para garantir variação e precisão.
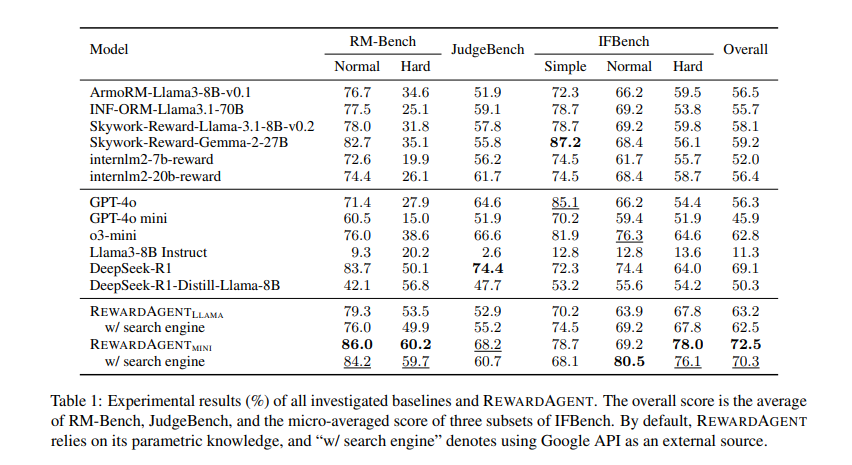
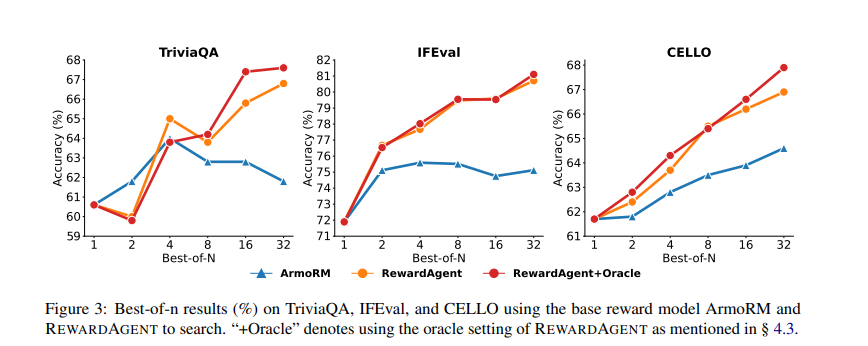
O amplo exame mostrou que Errar Os modelos tradicionais são muito altos. Foi examinado em bancos como RM-banch, Jajibench e IfbekObtendo alto desempenho na escolha de respostas verdadeiras e sucessivas. Em RM-banchO modelo recebeu um 76,0% A precisão do mecanismo de pesquisa e 79,3% Fora, comparado a 71,4% de modelos de recompensa normal. O programa também foi usado em terreno real Best of-N está pesquisando Trabalhos, quando aprimora a precisão das opções de resposta em todos os vários conjuntos de dados, incluindo Triviala, ifeval e violoncelo. Apesar de TriviaqaAssim, Errar alcançou a precisão de 68%passando pelo Base Recor Model ArmorM. Além disso, o modelo foi usado para formar uma escolha de dois Treinamento direto do treinamento merecedor (DPO)Quando o LLMS é treinado em pares gerados por produtores de vazamento é diferente daqueles que são treinados com inscrições regulares. Diretamente, os modelos são treinados para esta exibição de exibição Desenvolvimento em uma questão de questão técnica e seguintes tarefasindicando sua operação na direção do alinhamento LLM.
Os estudos estão sujeitos a um limite importante na recompensa da recompensa, modificando a precisão das preferências da pessoa. Errar Aumenta a confiabilidade dos modelos de recompensa e fornece respostas precisas e anexadas ao LLM. Essa abordagem é ativada para sinais de pesquisa adicionais, contribui para a formação de sistemas de IA confiáveis e qualificados. Trabalhos futuros podem aumentar a estimativa verbal para cobrir o tamanho sofisticado da retnoones e garantir que o modelo de recompensa continue a aparecer na crescente IA.
Enquete papel incluindo Página do Github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, fique à vontade para segui -lo Sane E não se esqueça de se juntar ao nosso 80k + ml subreddit.
🚨 Pesquisa recomendada recomendada para nexo
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
🚨 Plataforma de IA de código aberto recomendado: 'Interestagente Sistema de código aberto com várias fontes para testar o sistema de IA difícil (promovido)

: um novo padrão conceitual para grandes modelos de linguagem projetados para melhorar o gerenciamento de longas sequências de entrada em tarefas orientadas para recuperação")
